
- SAP Community
- Products and Technology
- Enterprise Resource Planning
- ERP Blogs by SAP
- Safeguard Performance of ABAP CDS Views – Part 1 C...
Enterprise Resource Planning Blogs by SAP
Get insights and updates about cloud ERP and RISE with SAP, SAP S/4HANA and SAP S/4HANA Cloud, and more enterprise management capabilities with SAP blog posts.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
former_member18
Active Participant
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
11-15-2018
2:26 PM
In this series of blog posts, I want to discuss some performance aspects of ABAP CDS views. As a performance expert daily working on CDS view performance topics I hope to be able to give some insights from my experience.
I roughly plan to cover the following points, but you are invited to ask for more if it has something to do with CDS view performance. If necessary, I will then consult the true experts ...
As a service for the hasty reader, I put the recommendations of this blog post at the beginning, so that you do not have to scroll down over all the details to find them:
One key principle of SAP’s Virtual Data Model (VDM) is ‘model once – use everywhere’. This means that the VDM can be used in transactional apps, analytical queries, APIs, extension views, and so on. It is also a prompt to reuse the building blocks of the VDM, the CDS entities, and with their help push-down complex application logic to the HANA database.
Since it is so easy to build and stack CDS views, there is some danger to ‘over-complicate’ single CDS views. During implementation, you should always try to keep as close to the targeted business purpose as possible, and to avoid extra-selects and operations, which are irrelevant for your application.
Read more about that in part 4 – Data Modelling.
To track the complexity of a CDS view, display the complexity metrics in ABAP Development Tools (ADT) choosing right mouse menu ‘Open With’ --> ‘Dependency Analyzer’.
In the Dependency Analyzer, the view hierarchy and complexity are visualized with 3 tools:

One simple KPI of the Complexity Metrics is the number of database tables that are used by the CDS view as data sources. The number presented includes all tables that are ‘used’ in the design time definition of the CDS view or its underlying view hierarchy. For tables that can be reached by associations, only those are included in the metric, where the associations are already followed at design time. Associations that could be followed at runtime by using explicit path notation in an SQL access are not counted.
There are of course many more factors that contribute to the complexity of a CDS view: join and union operations, CASE expressions, functions and calculations, aggregations, and others. In one of the following blog posts we will see that for example calculations can have a major impact on CDS view performance. But for now, let’s restrict to the simple ‘number of tables’ metric.
For CDS view development, SAP has defined three performance annotations (see chapter 7 Performance Requirements in SAP S/4HANA Requirements for Partner Solutions - note: link only works for customer and partners with S-user). At SAP, these annotations must be maintained for every non-private CDS view – and we strongly recommend our customers and partners doing the same. With these annotations the author of a view denotes, which quality of service, size category, and data class the consumer of the CDS view can expect. With respect to the service quality, it is required that in frequently executed transactional processes, only CDS views with high service quality A or B are used. CDS views annotated with these service qualities on the other hand must fulfill several requirements, for example with respect to their response times in simple key accesses. Another direction is that views with service quality A should not have more than 3 underlying tables (for B its 5 tables), where the numbers refer to the Complexity Metrics in ADT. CDS views build to answer complex analytical queries will have service quality D and should not have more than 100 underlying tables.
When looking at SQL statements runtime statistics of many different CDS views, one finds that the observed runtimes are only moderately correlated with number of underlying tables. Of course, the risk of built-in modelling defects raises with the number of joins and other operations in a view. But good performance can be achieved with dozens of tables, while it is also possible to obtain poor response times for a view with only 3 underlying tables. More crucial than the plain number of data sources are the amount of data in these data sources and the quality of the data model.
Nonetheless, the described complexity KPIs where set up for service quality A and B, since for CDS views with a restricted number of data sources runtimes will be better predictable, time for plan creation will be faster, created plans will be more stable and simpler to analyze. As for these views mainly accesses using the CDS key are expected, automated runtime measurements can be set up and monitored easily.
When a Fiori app is executed, user parameters will be passed down via OData query options to some handler logic in the ABAP backend. Either the SADL framework builds an SQL statement on a CDS view that is directly passed to the database, or some ABAP processing logic is called that executes SELECTs or JOINs on CDS views.

In both cases, the resulting SQL statement will incorporate the access to a CDS view, which is a SQL expression on its own, plus one or several of the following ingredients:
Also, session variables will be passed down from the ABAP session context to HANA. Session variables can influence the processing of a CDS view, since it might be susceptible to the actual session user, date, client, or language.
From the list above it becomes clear, that the SQL access to a CDS view can lead to a SQL statement that is more complex (that is, contains additional joins and accesses more tables) than the static CDS view.
In HANA PlanViz tool ‘Tables Used’ you will find the list of distinct tables that have been accessed in the execution of the SQL statement. Note that this is an aggregated list: tables that are accessed several times in the execution plan will be listed only once. Opposed to that, the Dependency Analyzer in ADT double-counts tables that occur in several positions of the view hierarchy.
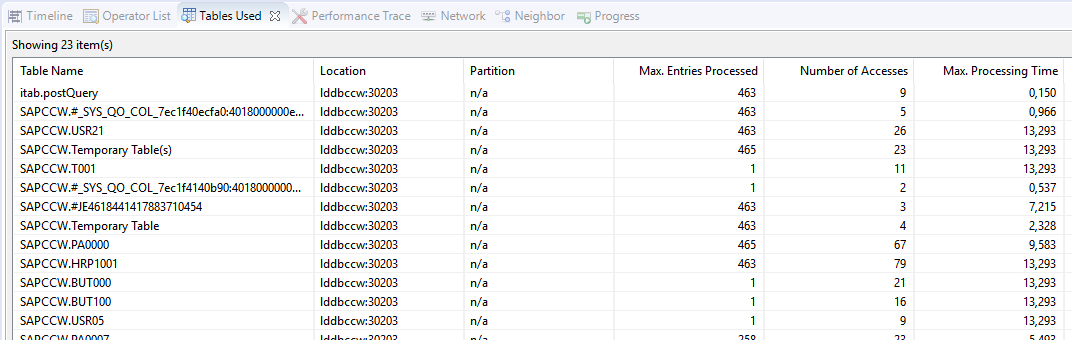
There is another reason why the number of accessed tables can be lower in the ‘Tables Used’ list than the one displayed in the Dependency Tree of the CDS view: HANA is able to skip OUTER JOINs at runtime. This happens when the following conditions are fulfilled:
Given the condition LEFT OUTER JOIN MANY TO ONE, HANA assumes that there is a 1:1 cardinality between the left and the right side of the join. Therefore, as the join does not change the cardinality of the result set, there is no need to execute it if no field is required from the right side.
With the normal OUTER JOIN, on the other hand, the view from the right-hand side can influence the result size and must not be omitted – otherwise, functional incorrect results could occur.
For the recommendations, wind up this blog post.
I roughly plan to cover the following points, but you are invited to ask for more if it has something to do with CDS view performance. If necessary, I will then consult the true experts ...
- Part 1 - CDS View Complexity - this blog
- Part 2 - HANA SQL Optimizer and Plan Cache
- Part 3 - Rules for Good Performance of CDS Views
- Part 4 - Data Modelling
- Part x - maybe more … your ideas or questions
As a service for the hasty reader, I put the recommendations of this blog post at the beginning, so that you do not have to scroll down over all the details to find them:
- Keep an eye on CDS view complexity by using the Dependency Analyzer in ADT
- Start small with creating simple CDS views, and cautiously go on with more complex ones
- Expose only required fields to reduce the number of accessed tables, used joins and operations
- Reduce complexity by using associations instead of LEFT OUTER JOIN
- Allow for join pruning by using option LEFT OUTER JOIN MANY TO ONE, if possible
- Maintain performance annotations for your CDS views
- Do not create CDS views with more than 100 underlying tables. In particular, follow the stricter recommendations of CDS views with service quality A, B, or C
- Quality of data model and amount of data in underlying data sources is more decisive for runtime than plain CDS view complexity
CDS View Complexity
One key principle of SAP’s Virtual Data Model (VDM) is ‘model once – use everywhere’. This means that the VDM can be used in transactional apps, analytical queries, APIs, extension views, and so on. It is also a prompt to reuse the building blocks of the VDM, the CDS entities, and with their help push-down complex application logic to the HANA database.
Since it is so easy to build and stack CDS views, there is some danger to ‘over-complicate’ single CDS views. During implementation, you should always try to keep as close to the targeted business purpose as possible, and to avoid extra-selects and operations, which are irrelevant for your application.
Read more about that in part 4 – Data Modelling.
Static Complexity
To track the complexity of a CDS view, display the complexity metrics in ABAP Development Tools (ADT) choosing right mouse menu ‘Open With’ --> ‘Dependency Analyzer’.
In the Dependency Analyzer, the view hierarchy and complexity are visualized with 3 tools:
- SQL Dependency Tree
- SQL Dependency Graph
- Complexity Metrics
One simple KPI of the Complexity Metrics is the number of database tables that are used by the CDS view as data sources. The number presented includes all tables that are ‘used’ in the design time definition of the CDS view or its underlying view hierarchy. For tables that can be reached by associations, only those are included in the metric, where the associations are already followed at design time. Associations that could be followed at runtime by using explicit path notation in an SQL access are not counted.
There are of course many more factors that contribute to the complexity of a CDS view: join and union operations, CASE expressions, functions and calculations, aggregations, and others. In one of the following blog posts we will see that for example calculations can have a major impact on CDS view performance. But for now, let’s restrict to the simple ‘number of tables’ metric.
Performance Annotations and Complexity
For CDS view development, SAP has defined three performance annotations (see chapter 7 Performance Requirements in SAP S/4HANA Requirements for Partner Solutions - note: link only works for customer and partners with S-user). At SAP, these annotations must be maintained for every non-private CDS view – and we strongly recommend our customers and partners doing the same. With these annotations the author of a view denotes, which quality of service, size category, and data class the consumer of the CDS view can expect. With respect to the service quality, it is required that in frequently executed transactional processes, only CDS views with high service quality A or B are used. CDS views annotated with these service qualities on the other hand must fulfill several requirements, for example with respect to their response times in simple key accesses. Another direction is that views with service quality A should not have more than 3 underlying tables (for B its 5 tables), where the numbers refer to the Complexity Metrics in ADT. CDS views build to answer complex analytical queries will have service quality D and should not have more than 100 underlying tables.
When looking at SQL statements runtime statistics of many different CDS views, one finds that the observed runtimes are only moderately correlated with number of underlying tables. Of course, the risk of built-in modelling defects raises with the number of joins and other operations in a view. But good performance can be achieved with dozens of tables, while it is also possible to obtain poor response times for a view with only 3 underlying tables. More crucial than the plain number of data sources are the amount of data in these data sources and the quality of the data model.
Nonetheless, the described complexity KPIs where set up for service quality A and B, since for CDS views with a restricted number of data sources runtimes will be better predictable, time for plan creation will be faster, created plans will be more stable and simpler to analyze. As for these views mainly accesses using the CDS key are expected, automated runtime measurements can be set up and monitored easily.
Complexity at Execution Time
When a Fiori app is executed, user parameters will be passed down via OData query options to some handler logic in the ABAP backend. Either the SADL framework builds an SQL statement on a CDS view that is directly passed to the database, or some ABAP processing logic is called that executes SELECTs or JOINs on CDS views.
In both cases, the resulting SQL statement will incorporate the access to a CDS view, which is a SQL expression on its own, plus one or several of the following ingredients:
- Filters (via WHERE-clause and / or view parameters), projections (field lists), and other SQL options (GROUP BY, ORDER BY, LIMIT, …)
- Explicit joins of the CDS view with other tables and views in ABAP OpenSQL
- Additional OUTER JOINs that are added if associations are followed explicitly by accessing fields via path notation
- Additional fields in WHERE-clause or joins are added if authority checks (DCLs - Data Control Language objects) are assigned to the CDS view
Also, session variables will be passed down from the ABAP session context to HANA. Session variables can influence the processing of a CDS view, since it might be susceptible to the actual session user, date, client, or language.
From the list above it becomes clear, that the SQL access to a CDS view can lead to a SQL statement that is more complex (that is, contains additional joins and accesses more tables) than the static CDS view.
In HANA PlanViz tool ‘Tables Used’ you will find the list of distinct tables that have been accessed in the execution of the SQL statement. Note that this is an aggregated list: tables that are accessed several times in the execution plan will be listed only once. Opposed to that, the Dependency Analyzer in ADT double-counts tables that occur in several positions of the view hierarchy.
There is another reason why the number of accessed tables can be lower in the ‘Tables Used’ list than the one displayed in the Dependency Tree of the CDS view: HANA is able to skip OUTER JOINs at runtime. This happens when the following conditions are fulfilled:
- The join has been defined as LEFT OUTER JOIN MANY TO ONE
- Fields coming from the right side of the join are not requested in the field list
- No filter, ORDER BY or GROUP BY is applied to the right side
Given the condition LEFT OUTER JOIN MANY TO ONE, HANA assumes that there is a 1:1 cardinality between the left and the right side of the join. Therefore, as the join does not change the cardinality of the result set, there is no need to execute it if no field is required from the right side.
With the normal OUTER JOIN, on the other hand, the view from the right-hand side can influence the result size and must not be omitted – otherwise, functional incorrect results could occur.
For the recommendations, wind up this blog post.
- SAP Managed Tags:
- ABAP Development,
- SAP S/4HANA
Labels:
8 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
Artificial Intelligence (AI)
1 -
Business Trends
363 -
Business Trends
29 -
Customer COE Basics and Fundamentals
1 -
Digital Transformation with Cloud ERP (DT)
1 -
Event Information
461 -
Event Information
28 -
Expert Insights
114 -
Expert Insights
189 -
General
1 -
Governance and Organization
1 -
Introduction
1 -
Life at SAP
414 -
Life at SAP
2 -
Product Updates
4,679 -
Product Updates
274 -
Roadmap and Strategy
1 -
Technology Updates
1,499 -
Technology Updates
100
Related Content
- Subscription Billing with Convergent Invoicing and Contract-Based Revenue Recognition in Enterprise Resource Planning Blogs by SAP
- Five Key assessments for a Smooth ECC to S/4HANA Transformation in Enterprise Resource Planning Q&A
- Asset Management in SAP S/4HANA Cloud Private Edition | 2023 FPS01 Release in Enterprise Resource Planning Blogs by SAP
- What is the "standard" in Fit-to-Standard? in Enterprise Resource Planning Blogs by SAP
- Streamline Your Journey to the Cloud with the RISE with SAP Methodology in Enterprise Resource Planning Blogs by SAP
Top kudoed authors
| User | Count |
|---|---|
| 7 | |
| 6 | |
| 4 | |
| 4 | |
| 4 | |
| 3 | |
| 3 | |
| 3 | |
| 3 | |
| 3 |