
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by Members
- Test your CPI Transforms with Spock, the Behavior ...
Technology Blogs by Members
Explore a vibrant mix of technical expertise, industry insights, and tech buzz in member blogs covering SAP products, technology, and events. Get in the mix!
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
anthony_bateman
Participant
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
02-01-2022
1:27 PM
Introduction
In this blog post, I will explain:
- What Behavior Driven Development is
- Why it is useful
- What Spock is and how it implements BDD
- How you can test any transform or chain of transforms in CPI from the comfort of your IDE.
What is Behavior Driven Development?
First off, 'Behavior Driven Development is such a mouthful, I shall henceforth refer to it as BDD.
BDD is an evolution and refinement of Test Driven Development (TDD). In TDD, software unit tests are written that test a specific aspect of a program. The typical process of TDD is:
- Write a simple test for one aspect of the program
- watch test fail
- write code to make the test pass
- refactor
TDD focuses on code functionality at a fairly technical level; as such, it requires a certain amount of technical familiarity to understand what the tests are actually doing.
BDD on the other hand is more concerned with describing features of the software in a way that can be understood by people with different skill sets, such as business experts, testers, developers etc. The way that this is done is by standardizing on a natural language description of how the software is behaving (by natural language I mean any language that has evolved naturally in humans). The advantages of this are:
- More effective cross-domain conversation about the nature of the features of the software
- Easier to understand the structure of the tests
- Easier to maintain the tests
- Self-documenting tests
There have been several excellent blog posts that have addressed the issue of testing transformations written in Groovy code, but to my knowledge none have addressed the issue of how to test non-Groovy transforms or a chain of steps containing multiple different types of transforms (XSLT, message mappings, java mappings, Groovy mappings etc.).
Enter Spock - the Logical Choice
My work with CPI has meant that I have had to invest time and effort in working with Groovy, somehow that led me to investigating test tools; Spock is a BDD framework written in Groovy, and has some very nice features that take advantage of the Groovy language that I will subsequently describe.
Firstly, each test method can be written as natural language text in quotes, for example:
def "FileHandler reads contents of file"() {
}In Spock terminology, this is known as a feature method, which describes a property of the system under specification. In this way, you can specify exactly the purpose of the test in a way that is broadly understandable.
Secondly, Spock organizes a feature method into blocks. Each block has a specific purpose. The typical phases of a feature method are:
- setup
- stimulus to the system under specification
- response expected from the system
- cleanup
Blocks assist in organising these phases
So without explaining any more, see if this makes intuitive sense to you:
def "FileHandler reads contents of file"() {
given: "a FileHandler instance"
FileHandler fileHandler = new FileHandler(pathAndFileName)
def contents
when: "I read the contents of the file"
contents = fileHandler.readFileContents()
then: "I expect the contents to be non-null"
contents != null
}
}In the above example, given, when and then are examples of blocks: 'given' is equivalent to a setup method, 'when' contains the stimulus, and 'then' the expected response. These are not the only blocks, but are most commonly used.
Thirdly, Spock makes parametric testing a breeze and so much easier that with JUnit for example. If one wishes to repeat the same test using different values of input data and expected response, one can use the 'where' block with a number of different data input methods. One of the easiest is to use data tables, which contain parameter names in the header and a row for each test case and expected result:
def "FileHandler reads contents of file"() {
given: "a FileHandler instance"
FileHandler fileHandler = new FileHandler(pathAndFileName)
def contents
when: "I read the contents of the file"
contents = fileHandler.readFileContents()
then: "I expect the contents to be non-null"
contents != null
where: "test files are"
pathAndFileName || _
'tests/Test1.xml' || _
'tests/Test2.xml' || _
}
}(The '||' separates input fields from output. In this case, because we have no expected output because in this simple test we are testing for non-null output, Spock requires the '_' to be placed in the output field).
In this case, Spock will iterate through each row of the table, replacing the variables in the column headers with the values specified in the test code.
When such a Feature method is run, the following output is produced in my IDE:

Results of running feature method of Spock
Hopefully, this has given you some idea of some of the power and elegance of Spock.
Refactoring CPI for Testing
Before we can get to testing our Transforms with Spock, we need to do some refactoring. The motivation for this is:
- We need to be able to test our transform functionality as-is, with no copying or subsequent adjustments after refactoring.
- We need to provide an endpoint by which we can access the transform functionality.
Let's consider a very simple integration flow, in which we have an XSL Transform followed by a Message Mapping:

Example iFlow with Mapping Actions
Notice that there are three steps to the mapping: a Content Modifier that sets parameters used in the XSL mapping, an XSL Transform, and a Message Mapping. Other steps are superfluous from the point of view of message transformation, and all three steps need to be available to test as a transformational unit.
These are the refactoring steps:
Step 1: Identify the transform related actions
Those are the three steps mentioned above in this example.
Step 2: Isolate the transformation actions into a Local Integration Process
Here, we take those 3 steps and encapsulate them in their own Local Integration process:
![]()
Transform Local Integration Process
Step 3: Expose an http adapter endpoint to test the Transform Process
Connect the http adapter to its own process, and call the Transform Local Integration Process from it:

BDD Test Process
Overall, the refactored integration flow now looks like this:

Process Overview
Having refactored the process:
- We don't make any changes to the main process steps not involved with transformation activities.
- The main process is never called in testing, guaranteeing no spurious accidental outputs.
- The same transformational process is called by both the test process and the main process, eliminating duplicate code/actions.
Setting up your IDE for use with Spock
I won't repeat what has already been published in some excellent articles, so I refer you to these:
- If you are using Eclipse, then I recommend that you follow engswee.yeoh excellent blog post CPI’s Groovy meets Spock – To boldly test where none has tested before | SAP Blogs
- If you are using IntelliJ IDEA, then I recommend following their series of tutorials on using Spock with their IDE, starting with Tutorial: Spock Part 1 – Getting started | The IntelliJ IDEA Blog (jetbrains.com)
Writing A Spock Test
Here is what I have done; firstly, I have written a couple of very simple helper classes to make the code a little cleaner.
The FileHandler.groovy class uses the utility of Groovy to extract the contents of a file:
class FileHandler {
File file
FileHandler(String filePathAndName){
file = new File(filePathAndName)
}
String readFileContents(){
// Read contents of file
return file.text
}
}The HTTPConnectionHandler is a wrapper around the Java URL class and uses the Apache Commons IOUtils class to make things succinct:
import org.apache.commons.io.IOUtils
class HTTPConnectionHandler {
HttpURLConnection con
HTTPConnectionHandler(String urlAddress, String user, String password){
def userpass = user + ':' + password
def basicAuth = 'Basic ' + new String(Base64.getEncoder().encode(userpass.getBytes()))
URL url = new URL(urlAddress)
con = url.openConnection()
con.setRequestMethod('POST')
con.setRequestProperty ('Authorization', basicAuth)
con.setRequestProperty('Content-Type', 'application/xml; utf-8')
con.setRequestProperty('Accept', 'application/xml')
con.setDoOutput(true)
}
void setRequestBody(String body){
try(OutputStream os = con.getOutputStream()) {
IOUtils.write(body, os, 'UTF-8')
}
}
String getResponse(){
try(InputStream inputStream = con.getInputStream()) {
def response = IOUtils.toString(inputStream)
return response
}
}
}Having defined these, they are used in our Spock Test Class.
Here is how I did it in IntelliJ IDEA:
1. Define a new Spock Specification
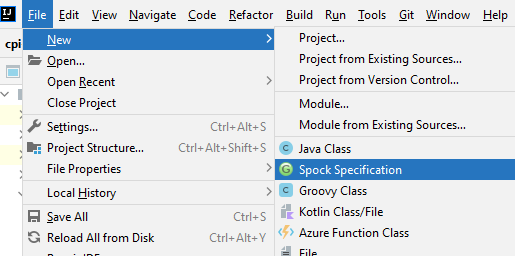

First, I set up the 'given' block:
class CPI_Transform_Specification extends Specification {
def "Testing CPI Transform"() {
given: "I set up the FileHandler and HTTPConnectionHandler"
FileHandler fileHandler = new FileHandler(pathAndFileName)
def fileContents = fileHandler.readFileContents()
def urlAddress = 'https://xxxxxxx.xx-xxxxxx-rt.cfapps.eu20.hana.ondemand.com/http/http_test_test'
def user = 'xx-xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx'
def password = 'xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxxxxxxxxxxxxxxx-xx-xxxxxxxxxxxxxxxxxxxxxxxxxxxx'
HTTPConnectionHandler ch = new HTTPConnectionHandler(urlAddress, user, password)
ch.setRequestBody(fileHandler.readFileContents())
}
}where urlAddress is the url of the endpoint of the HTTP adapter used in your integration flow and user and password are the clientid and client secret taken from a credential of the Process Integration Runtime:

This code creates a FileHandler, reads the contents of the file passed to it, then sets that as the body of the HTTP POST call that will be made into the iFlow. Note that we haven't specified yet what the parameter pathAndFileName is set to. This is important.
Next, the 'when' stimulus block is set up:
when: "I call the connection handler to fetch the response from CPI"
def response = ch.getResponse()
def responseXml = new XmlSlurper().parseText(response)All I do here is get the HTTP Response back from the HTTP call to the Integration Flow, then create a new Groovy XmlSlurper instance to handle querying the content of the response.
Next, the 'then' block. These are the actual tests you want to do on the response to make sure the transform did what you expected:
then: "I expect the following fields to match the expected results"
responseXml.IDOC.E1EDK01.CURCY == curcy
responseXml.IDOC.E1EDK01.HWAER == hwaer
responseXml.IDOC.E1EDK01.NTGEW == ntgewThe XmlSlurper class uses a syntax similar to XPath when specifying a path to an XML element; this is well documented online.
Note that each line is an assertion written in a concise way that does not require the use of the 'assert' keyword as in JUnit tests, making the tests easier to read. Also note that there are 3 variables on the right side of the '==' operators which also haven't been defined yet.
Finally the 'where' block is added:
where: "test files and expected results are"
pathAndFileName || curcy | hwaer | ntgew
'tests/INVOIC_CU Test1.xml' || 'SEK' | 'SEK' | 153.120
'tests/INVOIC_CU Test2.xml' || 'GBP' | 'GBP' | 221.937This is one of the really nice features of Spock testing. This is an example of a Datatable, and is how parameterized testing is performed. Note that:
- The variables that we commented on earlier are specified here as column headers.
- The values that these variables will adopt are written below the variable
- Variables to the left of the '| |' symbol are input variables.
- Variables to the right of the '| |' symbol are output, or expected variables.
Each row is a test; the table is iterated through a line at a time, and the 'given', 'when' and 'then' blocks are executed for each row of the table.
So this is effectively what is happening with our tests:

2. Run the Tests
When I run this test, if all goes well, this is what I see:

Nice; each test has its own line along with the parameters used.
What if one of the tests fails? How much useful information do I get? Let's force a failure by changing the second line of the Datatable:

Now, when this is run we get the following error message:

Notice that we are told what test failed, and we can see exactly where the falsehood that caused the test to fail occurred. This is very useful in cases of complex logic.
2. Extend the Tests
So how easy is it to write a new test? Really easy! You can add new test cases or add new tests to existing test cases just by extending the datatable.
2.1 Add a New Test
To do this, just add a new line to the Datatable:

Now when you re-run the tests, the new line is automatically evaluated:

2.1 Add a New Parameter
To do this, add a new parameter to the database (in this case gewei) and include it in the 'then' block as another check:


Now, when this is run, the new parameter is picked up and the check performed:

Summary
Hopefully in this blog post I have communicated
- What BDD tests are.
- Why they are useful.
- How to refactor your CPI Integration Flow to make the transforms testable.
- How to install Spock on your IDE.
- How to write a Spock test.
- How easy it is to extend your tests by adding new cases or new parameters.
Next Steps
One thing I haven't touched on is the issue with using a Mock adapter to replace calls to external systems. I have been thinking that a way to do this would be to extend the standard adapters to make them mockable. As far as I can tell, CPI Adapters are based on OSGi, which, to my understanding is open source and hence the source code should be available, at least in theory. Unfortunately, I have posted a question regarding this in the SAP Community, but have had no clarification, so I'm a bit stuck on this.
If anybody can enlighten me on this issue, please comment on this blog post.
Thank you for taking the time to read this! I hope it was useful and easy to understand.
Acknowledgements
I'd like to thank my colleague Jukka Saralehto for mulling this idea over with me and providing the final missing piece to the puzzle; to my ex-colleague Antti Kurkinen for kindly enduring my endless inane questions, and to engswee.yeoh for his excellent and inspiring articles! Finally, to all of you for being part of the community 🙂
- SAP Managed Tags:
- Cloud Integration
4 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
"automatische backups"
1 -
"regelmäßige sicherung"
1 -
"TypeScript" "Development" "FeedBack"
1 -
505 Technology Updates 53
1 -
ABAP
14 -
ABAP API
1 -
ABAP CDS Views
2 -
ABAP CDS Views - BW Extraction
1 -
ABAP CDS Views - CDC (Change Data Capture)
1 -
ABAP class
2 -
ABAP Cloud
3 -
ABAP Development
5 -
ABAP in Eclipse
1 -
ABAP Platform Trial
1 -
ABAP Programming
2 -
abap technical
1 -
abapGit
1 -
absl
2 -
access data from SAP Datasphere directly from Snowflake
1 -
Access data from SAP datasphere to Qliksense
1 -
Accrual
1 -
action
1 -
adapter modules
1 -
Addon
1 -
Adobe Document Services
1 -
ADS
1 -
ADS Config
1 -
ADS with ABAP
1 -
ADS with Java
1 -
ADT
2 -
Advance Shipping and Receiving
1 -
Advanced Event Mesh
3 -
Advanced formula
1 -
AEM
1 -
AI
8 -
AI Launchpad
1 -
AI Projects
1 -
AIML
9 -
Alert in Sap analytical cloud
1 -
Amazon S3
1 -
Analytic Models
1 -
Analytical Dataset
1 -
Analytical Model
1 -
Analytics
1 -
Analyze Workload Data
1 -
annotations
1 -
API
1 -
API and Integration
4 -
API Call
2 -
API security
1 -
Application Architecture
1 -
Application Development
5 -
Application Development for SAP HANA Cloud
3 -
Applications and Business Processes (AP)
1 -
Artificial Intelligence
1 -
Artificial Intelligence (AI)
5 -
Artificial Intelligence (AI) 1 Business Trends 363 Business Trends 8 Digital Transformation with Cloud ERP (DT) 1 Event Information 462 Event Information 15 Expert Insights 114 Expert Insights 76 Life at SAP 418 Life at SAP 1 Product Updates 4
1 -
Artificial Intelligence (AI) blockchain Data & Analytics
1 -
Artificial Intelligence (AI) blockchain Data & Analytics Intelligent Enterprise
1 -
Artificial Intelligence (AI) blockchain Data & Analytics Intelligent Enterprise Oil Gas IoT Exploration Production
1 -
Artificial Intelligence (AI) blockchain Data & Analytics Intelligent Enterprise sustainability responsibility esg social compliance cybersecurity risk
1 -
AS Java
1 -
ASE
1 -
ASR
2 -
ASUG
1 -
Attachments
1 -
Authentication
1 -
Authorisations
1 -
Automating Processes
1 -
Automation
2 -
aws
2 -
Azure
2 -
Azure AI Studio
1 -
Azure API Center
1 -
Azure API Management
1 -
B2B Integration
1 -
Backorder Processing
1 -
Backpropagation
1 -
Backup
1 -
Backup and Recovery
1 -
Backup schedule
1 -
BADI_MATERIAL_CHECK error message
1 -
Bank
1 -
Bank Communication Management
1 -
BAS
1 -
basis
2 -
Basis Monitoring & Tcodes with Key notes
2 -
Batch Management
1 -
BDC
1 -
Best Practice
1 -
BI
1 -
bitcoin
1 -
Blockchain
3 -
bodl
1 -
BOP in aATP
1 -
BOP Segments
1 -
BOP Strategies
1 -
BOP Variant
1 -
BPC
1 -
BPC LIVE
1 -
BTP
14 -
BTP AI Launchpad
1 -
BTP Destination
2 -
Business AI
1 -
Business and IT Integration
1 -
Business application stu
1 -
Business Application Studio
1 -
Business Architecture
1 -
Business Communication Services
1 -
Business Continuity
2 -
Business Data Fabric
3 -
Business Fabric
1 -
Business Partner
12 -
Business Partner Master Data
10 -
Business Technology Platform
2 -
Business Trends
4 -
BW4HANA
1 -
CA
1 -
calculation view
1 -
CAP
4 -
Capgemini
1 -
CAPM
1 -
Catalyst for Efficiency: Revolutionizing SAP Integration Suite with Artificial Intelligence (AI) and
1 -
CCMS
2 -
CDQ
12 -
CDS
2 -
Cental Finance
1 -
Certificates
1 -
CFL
1 -
Change Management
1 -
chatbot
1 -
chatgpt
3 -
CICD
1 -
CL_SALV_TABLE
2 -
Class Runner
1 -
Classrunner
1 -
Cloud ALM Monitoring
1 -
Cloud ALM Operations
1 -
cloud connector
1 -
Cloud Extensibility
1 -
Cloud Foundry
4 -
Cloud Integration
6 -
Cloud Platform Integration
2 -
cloudalm
1 -
communication
1 -
Compensation Information Management
1 -
Compensation Management
1 -
Compliance
1 -
Compound Employee API
1 -
Configuration
1 -
Connectors
1 -
Consolidation
1 -
Consolidation Extension for SAP Analytics Cloud
3 -
Control Indicators.
1 -
Controller-Service-Repository pattern
1 -
Conversion
1 -
Cosine similarity
1 -
CPI
1 -
cryptocurrency
1 -
CSI
1 -
ctms
1 -
Custom chatbot
3 -
Custom Destination Service
1 -
custom fields
1 -
Custom Headers
1 -
Customer Experience
1 -
Customer Journey
1 -
Customizing
1 -
cyber security
4 -
cybersecurity
1 -
Data
1 -
Data & Analytics
1 -
Data Aging
1 -
Data Analytics
2 -
Data and Analytics (DA)
1 -
Data Archiving
1 -
Data Back-up
1 -
Data Flow
1 -
Data Governance
5 -
Data Integration
2 -
Data Quality
12 -
Data Quality Management
12 -
Data Synchronization
1 -
data transfer
1 -
Data Unleashed
1 -
Data Value
8 -
Database and Data Management
1 -
database tables
1 -
Databricks
1 -
Dataframe
1 -
Datasphere
3 -
datenbanksicherung
1 -
dba cockpit
1 -
dbacockpit
1 -
Debugging
2 -
Defender
1 -
Delimiting Pay Components
1 -
Delta Integrations
1 -
Destination
3 -
Destination Service
1 -
Developer extensibility
1 -
Developing with SAP Integration Suite
1 -
Devops
1 -
digital transformation
1 -
Disaster Recovery
1 -
Documentation
1 -
Dot Product
1 -
DQM
1 -
dump database
1 -
dump transaction
1 -
e-Invoice
1 -
E4H Conversion
1 -
Eclipse ADT ABAP Development Tools
2 -
edoc
1 -
edocument
1 -
ELA
1 -
Embedded Consolidation
1 -
Embedding
1 -
Embeddings
1 -
Employee Central
1 -
Employee Central Payroll
1 -
Employee Central Time Off
1 -
Employee Information
1 -
Employee Rehires
1 -
Enable Now
1 -
Enable now manager
1 -
endpoint
1 -
Enhancement Request
1 -
Enterprise Architecture
1 -
Entra
1 -
ESLint
1 -
ETL Business Analytics with SAP Signavio
1 -
Euclidean distance
1 -
Event Dates
1 -
Event Driven Architecture
1 -
Event Mesh
2 -
Event Reason
1 -
EventBasedIntegration
1 -
EWM
1 -
EWM Outbound configuration
1 -
EWM-TM-Integration
1 -
Existing Event Changes
1 -
Expand
1 -
Expert
2 -
Expert Insights
2 -
Exploits
1 -
Fiori
15 -
Fiori Elements
2 -
Fiori SAPUI5
12 -
first-guidance
1 -
Flask
2 -
FTC
1 -
Full Stack
8 -
Funds Management
1 -
gCTS
1 -
GenAI hub
1 -
General
2 -
Generative AI
1 -
Getting Started
1 -
GitHub
10 -
Google cloud
1 -
Grants Management
1 -
groovy
2 -
GTP
1 -
HANA
6 -
HANA Cloud
2 -
Hana Cloud Database Integration
2 -
HANA DB
2 -
Hana Vector Engine
1 -
HANA XS Advanced
1 -
Historical Events
1 -
home labs
1 -
HowTo
1 -
HR Data Management
1 -
html5
8 -
HTML5 Application
1 -
Identity cards validation
1 -
idm
1 -
Implementation
1 -
Infuse AI
1 -
input parameter
1 -
instant payments
1 -
Integration
3 -
Integration Advisor
1 -
Integration Architecture
1 -
Integration Center
1 -
Integration Suite
1 -
intelligent enterprise
1 -
iot
1 -
Java
1 -
JMS Receiver channel ping issue
1 -
job
1 -
Job Information Changes
1 -
Job-Related Events
1 -
Job_Event_Information
1 -
joule
4 -
Journal Entries
1 -
Just Ask
1 -
Kerberos for ABAP
9 -
Kerberos for JAVA
8 -
KNN
1 -
Launch Wizard
1 -
Learning Content
2 -
Life at SAP
5 -
lightning
1 -
Linear Regression SAP HANA Cloud
1 -
Loading Indicator
1 -
local tax regulations
1 -
LP
1 -
Machine Learning
4 -
Marketing
1 -
Master Data
3 -
Master Data Management
14 -
Maxdb
2 -
MDG
1 -
MDGM
1 -
MDM
1 -
Message box.
1 -
Messages on RF Device
1 -
Microservices Architecture
1 -
Microsoft
1 -
Microsoft Universal Print
1 -
Middleware Solutions
1 -
Migration
5 -
ML Model Development
1 -
MLFlow
1 -
Modeling in SAP HANA Cloud
8 -
Monitoring
3 -
MPL
1 -
MTA
1 -
Multi-factor-authentication
1 -
Multi-Record Scenarios
1 -
Multilayer Perceptron
1 -
Multiple Event Triggers
1 -
Myself Transformation
1 -
Neo
1 -
Neural Networks
1 -
New Event Creation
1 -
New Feature
1 -
Newcomer
1 -
NodeJS
3 -
ODATA
2 -
OData APIs
1 -
odatav2
1 -
ODATAV4
1 -
ODBC
1 -
ODBC Connection
1 -
Onpremise
1 -
open source
2 -
OpenAI API
1 -
Oracle
1 -
PaPM
1 -
PaPM Dynamic Data Copy through Writer function
1 -
PaPM Remote Call
1 -
Partner Built Foundation Model
1 -
PAS-C01
1 -
Pay Component Management
1 -
PGP
1 -
Pickle
1 -
PLANNING ARCHITECTURE
1 -
Popup in Sap analytical cloud
1 -
PostgrSQL
1 -
POSTMAN
1 -
Prettier
1 -
Process Automation
2 -
Product Updates
6 -
PSM
1 -
Public Cloud
1 -
Python
5 -
python library - Document information extraction service
1 -
Qlik
1 -
Qualtrics
1 -
RAP
3 -
RAP BO
2 -
React
1 -
Record Deletion
1 -
Recovery
1 -
recurring payments
1 -
redeply
1 -
Release
1 -
Remote Consumption Model
1 -
Replication Flows
1 -
research
1 -
Resilience
1 -
REST
1 -
REST API
1 -
Retagging Required
1 -
Risk
1 -
rolandkramer
2 -
Rolling Kernel Switch
1 -
route
1 -
rules
1 -
S4 HANA
1 -
S4 HANA Cloud
1 -
S4 HANA On-Premise
1 -
S4HANA
4 -
S4HANA Cloud
1 -
S4HANA_OP_2023
2 -
SAC
10 -
SAC PLANNING
9 -
SAP
4 -
SAP ABAP
1 -
SAP Advanced Event Mesh
1 -
SAP AI Core
9 -
SAP AI Launchpad
8 -
SAP Analytic Cloud
1 -
SAP Analytic Cloud Compass
1 -
Sap Analytical Cloud
1 -
SAP Analytics Cloud
5 -
SAP Analytics Cloud for Consolidation
3 -
SAP Analytics cloud planning
1 -
SAP Analytics Cloud Story
1 -
SAP analytics clouds
1 -
SAP API Management
1 -
SAP Application Logging Service
1 -
SAP BAS
1 -
SAP Basis
6 -
SAP BO FC migration
1 -
SAP BODS
1 -
SAP BODS certification.
1 -
SAP BODS migration
1 -
SAP BPC migration
1 -
SAP BTP
24 -
SAP BTP Build Work Zone
2 -
SAP BTP Cloud Foundry
8 -
SAP BTP Costing
1 -
SAP BTP CTMS
1 -
SAP BTP Generative AI
1 -
SAP BTP Innovation
1 -
SAP BTP Migration Tool
1 -
SAP BTP SDK IOS
1 -
SAP BTPEA
1 -
SAP Build
11 -
SAP Build App
1 -
SAP Build apps
1 -
SAP Build CodeJam
1 -
SAP Build Process Automation
3 -
SAP Build work zone
10 -
SAP Business Objects Platform
1 -
SAP Business Technology
2 -
SAP Business Technology Platform (XP)
1 -
sap bw
1 -
SAP CAP
2 -
SAP CDC
1 -
SAP CDP
1 -
SAP CDS VIEW
1 -
SAP Certification
1 -
SAP Cloud ALM
4 -
SAP Cloud Application Programming Model
1 -
SAP Cloud Integration
1 -
SAP Cloud Integration for Data Services
1 -
SAP cloud platform
8 -
SAP Companion
1 -
SAP CPI
3 -
SAP CPI (Cloud Platform Integration)
2 -
SAP CPI Discover tab
1 -
sap credential store
1 -
SAP Customer Data Cloud
1 -
SAP Customer Data Platform
1 -
SAP Data Intelligence
1 -
SAP Data Migration in Retail Industry
1 -
SAP Data Services
1 -
SAP DATABASE
1 -
SAP Dataspher to Non SAP BI tools
1 -
SAP Datasphere
9 -
SAP DRC
1 -
SAP EWM
1 -
SAP Fiori
3 -
SAP Fiori App Embedding
1 -
Sap Fiori Extension Project Using BAS
1 -
SAP GRC
1 -
SAP HANA
1 -
SAP HANA PAL
1 -
SAP HANA Vector
1 -
SAP HCM (Human Capital Management)
1 -
SAP HR Solutions
1 -
SAP IDM
1 -
SAP Integration Suite
10 -
SAP Integrations
4 -
SAP iRPA
2 -
SAP LAGGING AND SLOW
1 -
SAP Learning Class
1 -
SAP Learning Hub
1 -
SAP Master Data
1 -
SAP Odata
2 -
SAP on Azure
2 -
SAP PAL
1 -
SAP PartnerEdge
1 -
sap partners
1 -
SAP Password Reset
1 -
SAP PO Migration
1 -
SAP Prepackaged Content
1 -
sap print
1 -
SAP Process Automation
2 -
SAP Process Integration
2 -
SAP Process Orchestration
1 -
SAP Router
1 -
SAP S4HANA
2 -
SAP S4HANA Cloud
2 -
SAP S4HANA Cloud for Finance
1 -
SAP S4HANA Cloud private edition
1 -
SAP Sandbox
1 -
SAP STMS
1 -
SAP successfactors
3 -
SAP SuccessFactors HXM Core
1 -
SAP Time
1 -
SAP TM
2 -
SAP Trading Partner Management
1 -
SAP UI5
1 -
SAP Upgrade
1 -
SAP Utilities
1 -
SAP-GUI
8 -
SAP_COM_0276
1 -
SAPBTP
1 -
SAPCPI
1 -
SAPEWM
1 -
sapfirstguidance
3 -
SAPHANAService
1 -
SAPIQ
2 -
sapmentors
1 -
saponaws
2 -
saprouter
1 -
SAPRouter installation
1 -
SAPS4HANA
1 -
SAPUI5
5 -
schedule
1 -
Script Operator
1 -
Secure Login Client Setup
8 -
security
9 -
Selenium Testing
1 -
Self Transformation
1 -
Self-Transformation
1 -
SEN
1 -
SEN Manager
1 -
Sender
1 -
service
2 -
SET_CELL_TYPE
1 -
SET_CELL_TYPE_COLUMN
1 -
SFTP scenario
2 -
Simplex
1 -
Single Sign On
8 -
Singlesource
1 -
SKLearn
1 -
Slow loading
1 -
SOAP
2 -
Software Development
1 -
SOLMAN
1 -
solman 7.2
2 -
Solution Manager
3 -
sp_dumpdb
1 -
sp_dumptrans
1 -
SQL
1 -
sql script
1 -
SSL
8 -
SSO
8 -
Story2
1 -
Substring function
1 -
SuccessFactors
1 -
SuccessFactors Platform
1 -
SuccessFactors Time Tracking
1 -
Sybase
1 -
Synthetic User Monitoring
1 -
system copy method
1 -
System owner
1 -
Table splitting
1 -
Tax Integration
1 -
Technical article
1 -
Technical articles
1 -
Technology Updates
15 -
Technology Updates
1 -
Technology_Updates
1 -
terraform
1 -
Testing
1 -
Threats
2 -
Time Collectors
1 -
Time Off
2 -
Time Sheet
1 -
Time Sheet SAP SuccessFactors Time Tracking
1 -
Tips and tricks
2 -
toggle button
1 -
Tools
1 -
Trainings & Certifications
1 -
Transformation Flow
1 -
Transport in SAP BODS
1 -
Transport Management
1 -
TypeScript
3 -
ui designer
1 -
unbind
1 -
Unified Customer Profile
1 -
UPB
1 -
Use of Parameters for Data Copy in PaPM
1 -
User Unlock
1 -
VA02
1 -
Validations
1 -
Vector Database
2 -
Vector Engine
1 -
Vectorization
1 -
Visual Studio Code
1 -
VSCode
2 -
VSCode extenions
1 -
Vulnerabilities
1 -
Web SDK
1 -
Webhook
1 -
work zone
1 -
workload
1 -
xsa
1 -
XSA Refresh
1
- « Previous
- Next »
Related Content
- Tracking HANA Machine Learning experiments with MLflow: A conceptual guide for MLOps in Technology Blogs by SAP
- Terraform Cloud Foundry Provider for SAP BTP in Technology Blogs by SAP
- Enhancing the SAPUI5/OpenUI5 Demo Kit Together: A Look into Our Feedback Loop in Technology Blogs by SAP
- SAP BTP FAQs - Part 2 (Application Development, Programming Models and Multitenancy) in Technology Blogs by SAP
- How to generate a wrapper for function modules (BAPIs) in tier 2 in Technology Blogs by SAP
Top kudoed authors
| User | Count |
|---|---|
| 54 | |
| 5 | |
| 4 | |
| 4 | |
| 4 | |
| 4 | |
| 3 | |
| 3 | |
| 3 | |
| 3 |