
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- A New Approach for Replicating Tables Across Diffe...
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Advisor
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
08-11-2020
6:13 AM
Update on September 15, 2023:
|
Starting with SAP HANA Cloud, the SAP HANA database in SAP HANA Cloud supports a new remote table replication feature that allows tables to be replicated across different SAP HANA systems natively. With this new feature, users can handily replicate remote tables by sending DDL and DML logs directly from a source system to a target system through the SAP HANA smart data access (SDA) ODBC connection.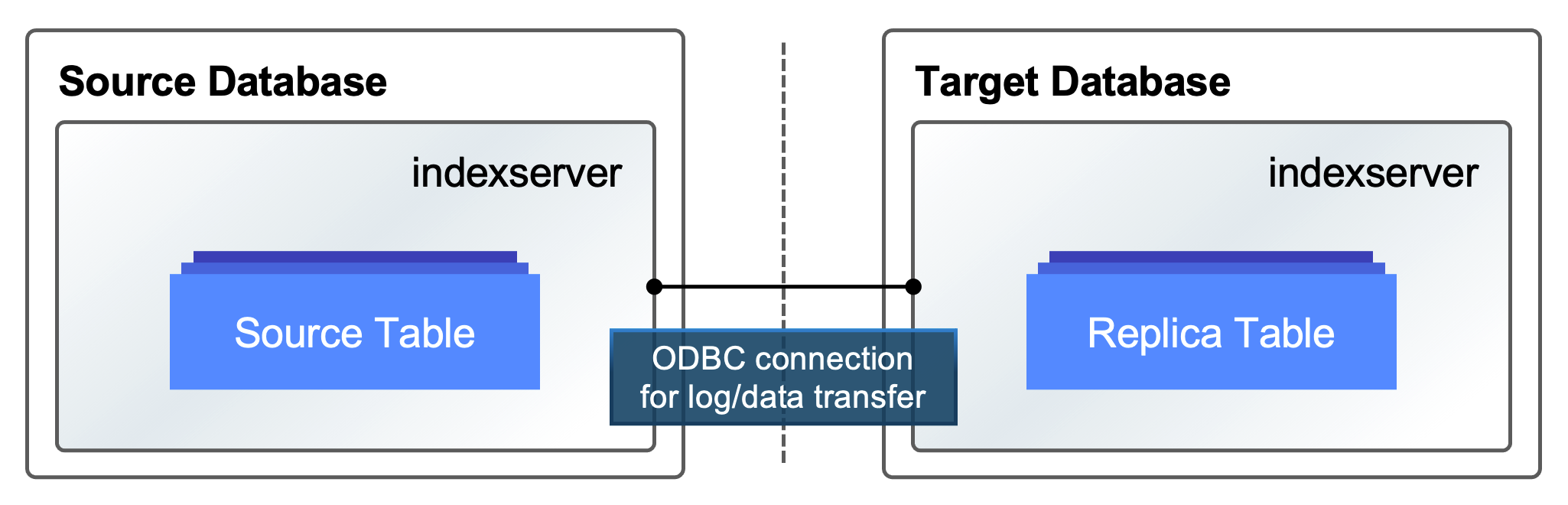
In a nutshell, the new remote table replication was developed with the following five key characteristics.
- Transient (in-memory) log-based replication: Since this new feature is log-based at the transactional layer, it can provide better performance with less overhead to a source system compared to trigger-based replication.
- ODBC connection: It ensures optimized performance between SAP HANA systems because it uses an SDA ODBC connection with the hanaodbc adapter for its log/data transfer.
- Transactional consistency: If multiple source tables are updated within one transaction, it applies the same behavior to the target tables to ensure database-level transactional consistency. However, transactional consistency is only guaranteed if the transaction is handled at the database level, and it doesn’t guarantee transaction consistency at the application level such as ABAP.
- Near real-time replication: It continues to replicate changes as they occur (change data capture).
- Auto reactivation for failures: When an indexserver is turned off for any reasons, such as a crash or upgrade, all replications are disabled. However, when the indexserver restarts, the replications are reactivated and resumes replicating.
Getting started with the new remote table replication
First of all, this feature is supported between SAP HANA Cloud systems. It is also supported when replicating tables from SAP HANA Platform 2.0 SPS05 or later (source) to SAP HANA Cloud (target) as a hybrid scenario. In this hybrid scenario, the SAP Cloud Connector is needed to create SDA remote sources to SAP HANA Platform 2.0 SPS05 or later, which is protected by a firewall.
Please also refer to the table below for the supported scenarios.
| Scenario | Supported? |
| Replication between SAP HANA Cloud systems | Yes |
| Replication from SAP HANA Platform 2.0 SPS05 or later (source) to SAP HANA Cloud (target) | Yes |
| Replication from SAP HANA Platform 2.0 SPS04 or earlier (source) to SAP HANA Cloud (target) | No |
| Replication from SAP HANA Cloud (source) to SAP HANA Platform 2.0 (target) | No |
| Replication between SAP HANA Platform 2.0 systems | No |
That is, the remote table replication feature is only supported when the target is the SAP HANA database in SAP HANA Cloud, as this feature is exclusively available in SAP HANA Cloud. Therefore, it cannot be used for replicating tables between SAP HANA Platform 2.0 (on-premise) systems. For replicating tables between SAP HANA Platform 2.0 (on-premise) systems, SAP HANA smart data integration (SDI) is the right solution.
Configuration and activation
To use this new remote table replication, the first step is to create a remote source with SDA in the target SAP HANA database in SAP HANA Cloud. SDA supports 3 types of credential modes to access a remote source with SAP HANA Cloud: technical user, secondary credentials, and single sign-on (SSO) with JSON Web Tokens (JWT). Currently, this new feature only supports the technical user mode, and users need to configure 'DML Mode' of a remote source property as ‘readwrite’.
The ‘readwrite’ is a default value for the remote source property ‘DML Mode’ in SAP HANA Database Explorer but please make sure that the created remote source is configured correctly. And the remote source should be named in UPPERCASE to initialize the remote table replication.
For more details of creating an SAP HANA Cloud remote source, please refer to the below official documentations.
- SAP HANA Cloud, SAP HANA Database Data Access Guide: Import Certificates for SSL Connections to Remote Sources
- SAP HANA Cloud, SAP HANA Database Data Access Guide: Create an SAP HANA Cloud Remote Source
For creating an SAP HANA on-premise remote source in a hybrid scenario, which is becoming increasingly important, please refer to the below official documentations.
- SAP HANA Cloud, SAP HANA Database Data Access Guide: Set Up the Cloud Connector
- SAP HANA Cloud, SAP HANA Database Data Access Guide: Create an SAP HANA On-Premise Remote Source
The next step is to create a virtual table in the target system. The following statement will create a virtual table called V_CUSTOMER in the MARKETING schema of the target system. This virtual table will be based on the CUSTOMER table in the SALES schema of the source system.
CREATE VIRTUAL TABLE MARKETING.V_CUSTOMER AT "REMOTE_REP"."<NULL>"."SALES"."CUSTOMER";Then to create a replica table and remote subscription, the following steps are needed.
-- create a replica table
CREATE COLUMN TABLE MARKETING.R_CUSTOMER LIKE MARKETING.V_CUSTOMER;
-- create a remote subscription
CREATE REMOTE SUBSCRIPTION SUB ON MARKETING.V_CUSTOMER TARGET TABLE MARKETING.R_CUSTOMER;Since the replica table is created with COLUMN LOADABLE by default, the entire columns will be loaded into memory for optimal performance. However, if necessary, the user can switch it to PAGE LOADABLE. This means that column data is loaded by page into the buffer cache, reducing memory usage. To switch, the user can use the following statement.
-- switch to page loadable
ALTER TABLE MARKETING.R_CUSTOMER PAGE LOADABLE;
-- switch to column loadable
ALTER TABLE MARKETING.R_CUSTOMER COLUMN LOADABLE;Those are all the configurations for setting up new remote table replication. The following statements can be used to activate, deactivate, or drop the replication.
-- activate the replication
ALTER REMOTE SUBSCRIPTION SUB DISTRIBUTE;
-- deactivate the replication
ALTER REMOTE SUBSCRIPTION SUB RESET;
-- drop the replication
DROP REMOTE SUBSCRIPTION SUB;If users drop the replication and want to reactivate it, they need to either truncate or recreate the replica table. Please find the further details in the links below.
- SAP HANA Cloud, SAP HANA Database Data Access Guide: Configure Remote Table Replication with the SDA HANA Adapter
- SAP HANA Cloud, SAP HANA Database Data Access Guide: System Views for Monitoring Remote Table Replication
Auto reactivation
As mentioned, this new remote table replication feature supports auto reactivation for failures. During the reactivation, it synchronizes each pair of source and target table first then changes their replication status to ENABLED. Users can also manually do reactivation with the following statements.
ALTER REMOTE SOURCE <remote_source_name> SUSPEND CAPTURE;
ALTER REMOTE SOURCE <remote_source_name> RESUME CAPTURE;Please also refer to the following official documentation.
- SAP HANA Cloud, SAP HANA Database Data Access Guide: Suspending and Resuming Remote Table Replication (Smart Data Access HANA Adapter)
Differences from the replication with SDI or SLT
SAP HANA smart data integration (SDI) with HanaAdapter can be used for replicating tables between SAP HANA Cloud systems. However, this new feature with SDA hanaodbc adapter provides better performance with log-based replication and a simplified approach without the need to deploy the Data Provisioning (DP) Agent.
Although it supports near real-time change data capture like SDI, there are some limitations. For example, the schema of source table and target table must be identical with no additional filters or different partitions. If you would like to know more about the limitations or comparisons between SDI and SDA, please refer to the link below.
- SAP HANA Cloud, SAP HANA Database Data Access Guide: Replicating Tables from Remote Sources
SAP Landscape Transformation (SLT) Replication Server can also be used for replicating tables between SAP HANA systems but it is trigger-based and requires additional installation. For these reasons, this new remote table replication can provides benefits from log-based replication with a simplified approach compared to SLT.
Furthermore, the key differentiator, as explained, compared to SDI and SLT, is that in the case where multiple source tables are updated within one transaction, it applies the same behavior to the target tables to ensure database-level transactional consistency. However, this does not mean that SDI does not support transactional consistency. The difference is that this new remote table replication ensures transactional commit order based on the original transaction commit ID.
Other limitations
For other limitations, please refer to the link below.
- SAP HANA Cloud, SAP HANA Database Data Access Guide: Unsupported Data Types and Other Limitations
Hybrid scenario and futures
As briefly mentioned above, the hybrid scenario is growing in importance, and this new remote table replication will play a crucial role as one of key enablers for the hybrid scenario. In parallel, it will continue to evolve and be augmented with more capabilities and better supportability. So, please stay tuned for our next blog series.
- SAP Managed Tags:
- SAP HANA Cloud,
- SAP HANA,
- SAP Business Technology Platform,
- SAP HANA Cloud, SAP HANA database
Labels:
23 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,658 -
Business Trends
107 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
72 -
Expert
1 -
Expert Insights
177 -
Expert Insights
340 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
GraphQL
1 -
Kafka
1 -
Life at SAP
780 -
Life at SAP
14 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,575 -
Product Updates
384 -
Replication Flow
1 -
REST API
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,872 -
Technology Updates
472 -
Workload Fluctuations
1
Related Content
- Error "Missing JWT Token for forwardAuthToken" When Using worker_threads/spawn in SAP CAP in Technology Q&A
- Exploring ML Explainability in SAP HANA PAL – Classification and Regression in Technology Blogs by SAP
- Automated check for SAP HANA Cloud availability with SAP Automation Pilot in Technology Blogs by SAP
- Replicate BOM Product from S/4 Hana Private Cloud to CPQ 2.0 in Technology Q&A
- Essential SAP Fiori Transaction Codes for Fiori Developers in Technology Q&A
Top kudoed authors
| User | Count |
|---|---|
| 17 | |
| 14 | |
| 12 | |
| 10 | |
| 9 | |
| 8 | |
| 7 | |
| 7 | |
| 6 | |
| 6 |