
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- Aggregate Data from Multiple SAP HANA Sources to O...
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
danielsblog01
Participant
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
08-05-2021
7:08 PM
With SAP HANA Cloud, hybrid landscapes (on-premise systems working with cloud systems) have become easily attainable. However, when doing aggregate data analysis, it might be easier to have the data of interest in a single source to keep data types and functionality consistent. We will see that with a HANA Cloud database and remote connections, the movement of data from multiple HANA instances to an SAP HANA Cloud data lake can be done from a single SQL console!
Today, I am going to bring data from an on-premise SAP HANA system together with an SAP HANA Cloud database in a single SAP HANA data lake. I will start from a landscape which has an SAP HANA Cloud database, SAP HANA database, and SAP HANA data lake connected. If you’re interested in learning about how to connect your on-premise SAP HANA database to an SAP HANA Cloud instance, you can find that here.
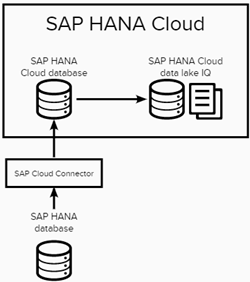
The Plan
The plan is to aggregate the data and move it to an SAP HANA data lake using virtual tables within the SAP HANA Cloud database. Then, I will use EXPORT statements from the HANA Cloud database console to export the data to Amazon S3. After the export, the data will be loaded into a data lake instance with a LOAD table statement. Let’s begin.
Creating the Virtual Tables
I will assume that the remote connection from the HANA Cloud database to the HANA on-premise database has already been established. Then, creating the virtual tables can be done through the SAP Database Explorer.
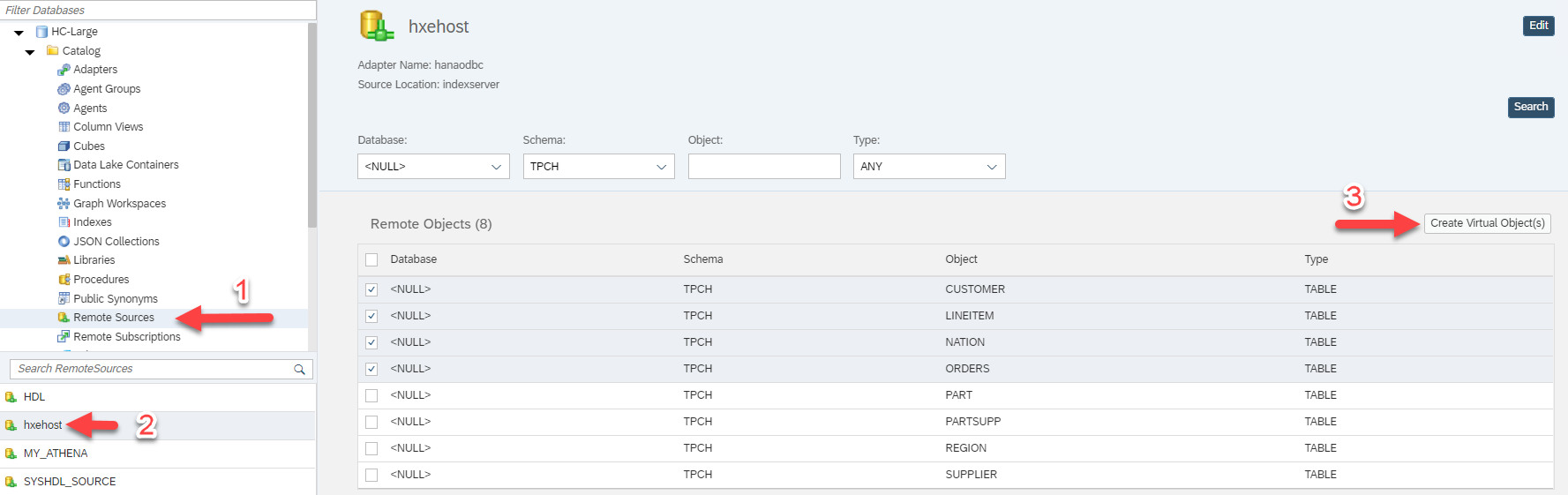
Then, after the tables are created, I can check for them in the database catalogue.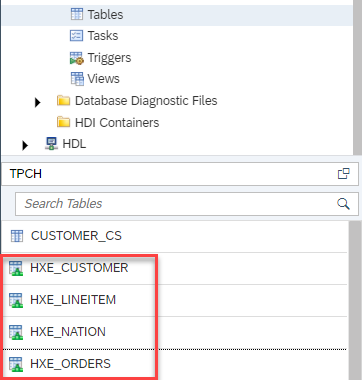
The Export and Import Query
The best part of this method of moving the data from multiple instances into the data lake using this method is that it can be done from a single SQL Console and it can be done in one run too!
Aside: in this blog we will be using Amazon S3 as the export destination for the data. It is planned for HANA Cloud database to support exports to the HANA data lake file store. This enables two possibilities. The first possibility is to use the file store as a temporary location for the data while it is loaded via a load table statement. The second possibility is that we store the data in the file store and use SQL on Files to query it. The choice will be dependent on what the value of this data is.
Anyhow, here is the export statements from the SQL console.
-- TABLES FROM ON-PREMISE HANA EXPORT INTO 's3-eu-central-1://<ACCESS KEY>:<secret access key>@<bucket name>/mydir/customer_blog.csv' FROM HXE_CUSTOMER; EXPORT INTO 's3-eu-central-1://<ACCESS KEY>:<secret access key>@<bucket name>/mydir/lineitem_blog.csv' FROM HXE_LINEITEM; EXPORT INTO 's3-eu-central-1://<ACCESS KEY>:<secret access key>@<bucket name>/mydir/nation_blog.csv' FROM HXE_NATION; EXPORT INTO 's3-eu-central-1://<ACCESS KEY>:<secret access key>@<bucket name>/mydir/orders_blog.csv' FROM HXE_ORDERS; -- TABLES FOM HANA CLOUD DATABASE EXPORT INTO 's3-eu-central-1://<ACCESS KEY>:<secret access key>@<bucket name>/mydir/partsupp_blog.csv' FROM PARTSUPP_CS; EXPORT INTO 's3-eu-central-1://<ACCESS KEY>:<secret access key>@<bucket name>/mydir/part_blog.csv' FROM PART_CS; EXPORT INTO 's3-eu-central-1://<ACCESS KEY>:<secret access key>@<bucket name>/mydir/supplier_blog.csv' FROM SUPPLIER_CS; EXPORT INTO 's3-eu-central-1://<ACCESS KEY>:<secret access key>@<bucket name>/mydir/region_blog.csv' FROM REGION_CS;
As we can see, the statements are relatively repetitive and there is no syntax difference between exporting a virtual table and a HANA table. They require some temporary storage destination and a table full of data. Next, we can use the REMOTE_EXECUTE procedure to push a LOAD table statement down to the data lake.
-- LOAD TABLE FROM EXPORT
CALL SYS.REMOTE_EXECUTE('HDL',
'LOAD TABLE REGION(
R_REGIONKEY,
R_NAME,
R_COMMENT
)
USING FILE ''s3://<bucket_name>/mydir/region_blog.csv''
DELIMITED BY ''|''
FORMAT CSV
ACCESS_KEY_ID ''<access_key>''
SECRET_ACCESS_KEY ''<secret_access_key>''
REGION ''eu-central-1''
ESCAPES OFF
QUOTES OFF;
LOAD TABLE CUSTOMER(
C_CUSTKEY,
C_NAME,
C_ADDRESS,
C_NATIONKEY,
C_PHONE,
C_ACCTBAL,
C_MKTSEGMENT,
C_COMMENT
)
USING FILE ''s3://<bucket_name>/mydir/customer_blog.csv''
DELIMITED BY ''|''
FORMAT CSV
ACCESS_KEY_ID ''<access_key>''
SECRET_ACCESS_KEY ''<secret_access_key>''
REGION ''eu-central-1''
ESCAPES OFF
QUOTES OFF;
LOAD TABLE NATION(
N_NATIONKEY,
N_NAME,
N_REGIONKEY,
N_COMMENT
)
USING FILE ''s3://<bucket_name>/mydir/nation_blog.csv''
DELIMITED BY ''|''
FORMAT CSV
ACCESS_KEY_ID ''<access_key>''
SECRET_ACCESS_KEY ''<secret_access_key>''
REGION ''eu-central-1''
ESCAPES OFF
QUOTES OFF;
LOAD TABLE SUPPLIER(
S_SUPPKEY,
S_NAME,
S_ADDRESS,
S_NATIONKEY,
S_PHONE,
S_ACCTBAL,
S_COMMENT
)
USING FILE ''s3://<bucket_name>/mydir/supplier_blog.csv''
DELIMITED BY ''|''
FORMAT CSV
ACCESS_KEY_ID ''<access_key>''
SECRET_ACCESS_KEY ''<secret_access_key>''
REGION ''eu-central-1''
ESCAPES OFF
QUOTES OFF;
LOAD TABLE CUSTOMER(
C_CUSTKEY,
C_NAME,
C_ADDRESS,
C_NATIONKEY,
C_PHONE,
C_ACCTBAL,
C_MKTSEGMENT,
C_COMMENT
)
USING FILE ''s3://<bucket_name>/mydir/customer_blog.csv''
DELIMITED BY ''|''
FORMAT CSV
ACCESS_KEY_ID ''<access_key>''
SECRET_ACCESS_KEY ''<secret_access_key>''
REGION ''eu-central-1''
ESCAPES OFF
QUOTES OFF;
LOAD TABLE ORDERS(
O_ORDERKEY,
O_CUSTKEY,
O_ORDERSTATUS,
O_TOTALPRICE,
O_ORDERDATE,
O_ORDERPRIORITY,
O_CLERK,
O_SHIPPRIORITY,
O_COMMENT
)
USING FILE ''s3://<bucket_name>/mydir/orders_blog.csv''
DELIMITED BY ''|''
FORMAT CSV
ACCESS_KEY_ID ''<access_key>''
SECRET_ACCESS_KEY ''<secret_access_key>''
REGION ''eu-central-1''
ESCAPES OFF
QUOTES OFF;
LOAD TABLE PART(
P_PARTKEY,
P_NAME,
P_MFGR,
P_BRAND,
P_TYPE,
P_SIZE,
P_CONTAINER,
P_RETAILPRICE,
P_COMMENT
)
USING FILE ''s3://<bucket_name>/mydir/part_blog.csv''
DELIMITED BY ''|''
FORMAT CSV
ACCESS_KEY_ID ''<access_key>''
SECRET_ACCESS_KEY ''<secret_access_key>''
REGION ''eu-central-1''
ESCAPES OFF
QUOTES OFF;
LOAD TABLE LINEITEM(
L_ORDERKEY,
L_PARTKEY,
L_SUPPKEY,
L_LINENUMBER,
L_QUANTITY,
L_EXTENDEDPRICE,
L_DISCOUNT,
L_TAX,
L_RETURNFLAG,
L_LINESTATUS,
L_SHIPDATE,
L_COMMITDATE,
L_RECEIPTDATE,
L_SHIPINSTRUCT,
L_SHIPMODE,
L_COMMENT
)
USING FILE ''s3://<bucket_name>/mydir/lineitem_blog.csv''
DELIMITED BY ''|''
FORMAT CSV
ACCESS_KEY_ID ''<access_key>''
SECRET_ACCESS_KEY ''<secret_access_key>''
REGION ''eu-central-1''
ESCAPES OFF
QUOTES OFF;
LOAD TABLE PARTSUPP(
PS_PARTKEY,
PS_SUPPKEY,
PS_AVAILQTY,
PS_SUPPLYCOST,
PS_COMMENT
)
USING FILE ''s3://<bucket_name>/mydir/partsupp_blog.csv''
DELIMITED BY ''|''
FORMAT CSV
ACCESS_KEY_ID ''<access_key>''
SECRET_ACCESS_KEY ''<secret_access_key>''
REGION ''eu-central-1''
ESCAPES OFF
QUOTES OFF;
END');
We can place all this SQL code in a single console, run it, and we’ve aggregated our data into a single data lake instance! That’s it, this is a method for moving large amounts of data from multiple HANA systems to a data lake. Another approach is to use SELECT…INSERT statements which can be seen below. Keep in mind, the SELECT…INSERT method may not be suitable for large amounts of data due to performance reasons.
INSERT INTO <HDL_TABLE> (SELECT * FROM <HANA_TABLE>);
Conclusion
Data can be aggregated from multiple remote sources and loaded into a data lake from one SQL console. We can do this using an object store (Amazon S3) as a temporary storage for our data and then loading that data into a data lake. This consolidates data in one source for analysis, which is one of data lake’s strengths. Simple and effective!
Do you have questions about SAP HANA Data lake IQ? Would you like to see a specific use case covered in a blog? Leave a comment in a comment section and let me know! I’d love to cover any topic that you might be interested in.
If you’ve found this blog post useful feel free to give it a like or comment! Questions are welcome in the comment section below or on the community questions page. For more information on SAP HANA Cloud, data lake there are detailed step-by-step tutorials here.
- SAP Managed Tags:
- SAP HANA Cloud,
- SAP HANA,
- Cloud,
- SAP HANA Cloud, data lake
Labels:
4 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,658 -
Business Trends
116 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
75 -
Expert
1 -
Expert Insights
177 -
Expert Insights
354 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
GraphQL
1 -
Kafka
1 -
Life at SAP
780 -
Life at SAP
14 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,575 -
Product Updates
398 -
Replication Flow
1 -
REST API
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,871 -
Technology Updates
490 -
Workload Fluctuations
1
Related Content
- What’s New in SAP Analytics Cloud Release 2024.10 in Technology Blogs by SAP
- Business AI for Aerospace, Defense and Complex Manufacturing in Technology Blogs by SAP
- Import Data Connection to SAP S/4HANA in SAP Analytics Cloud : Technical Configuration in Technology Blogs by Members
- Currency Translation in SAP Datasphere in Technology Blogs by Members
- SAP Datasphere News in April in Technology Blogs by SAP
Top kudoed authors
| User | Count |
|---|---|
| 20 | |
| 11 | |
| 8 | |
| 8 | |
| 7 | |
| 7 | |
| 7 | |
| 6 | |
| 6 | |
| 6 |