In a previous blog post I explored a possible approach for storing business events from SAP Advanced Event Mesh into SAP Datasphere. Link:
Walkthrough: Capturing Business Events in SAP Datasphere using SAP Integration Suite
The integration flow in that scenario has a 1-to-1 link between an incoming event and a HANA insert statement. This works great if data volumes are limited, but becomes a bottleneck if the number of events increases over time (e.g. through a project rollout).
TL;DR: use a data store to buffer incoming messages for periodic bulk insert into HANA.
The Problem
Taking a sample integration flow that receives an event from Advanced Event Mesh via the AMQP adapter, and stores this in HANA via the JDBC adapter can, in its simplified form, look like the below:

An incoming JSON payload like this:
{
"id": 1,
"value": 200
}
... is transformed into XML (notice how I opted to use 'access' as the root element, which makes things a bit easier further on):
<access>
<id>1</id>
<value>200</value>
</access>
... and then encapsulated into an XML SQL insert statement like this:
<root>
<Insert_Statement>
<Events action="INSERT">
<table>MY_EVENTS</table>
<access>
<id>1</id>
<value>200</value>
</access>
</Events>
</Insert_Statement>
</root>
Result
Looking at the execution log of this integration flow we can clearly see that the JDBC step is the most time consuming. In my scenario it took about half a second, which inherently would limit my integration scenario from scaling beyond 2 events per second. This is a problem!

The Solution
SAP Integration Suite has many tools in the toolbox, but the most convenient for our scenario would be using the
Data Store. A Data Store is a small database in SAP Integration Suite that you can use to temporarily store a message to process it later. And that's what we will do here: store incoming events sequentially in the data store, and retrieve them later in batches to generate bulk insert statements for HANA.
This inherently decouples our integration flow, so we can create 2 separate flows:
- Receive the event from the AMQP sender, and write it to the data store.
- At set time intervals, read a set of events from the data store and process them in HANA.
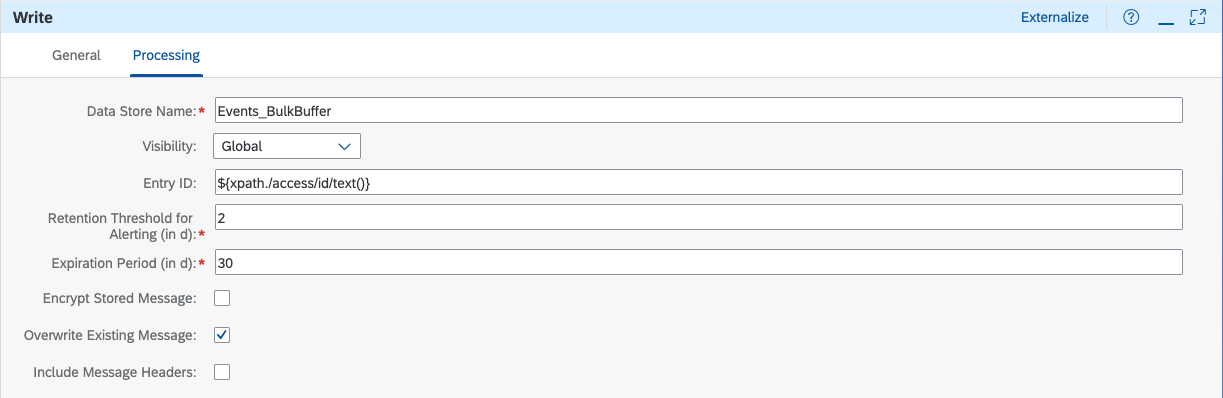
1. Writing the event to the data store

In this flow, the
Write Payload step (Persistence > Data Store Operations > Write) is the most interesting as it will take care of storing the message. Notice how we can use the id of the payload as
Entry ID to make it easy to identify it in the data store later on (though this is just for monitoring purposes as we will not rely on this for further processing).
Result
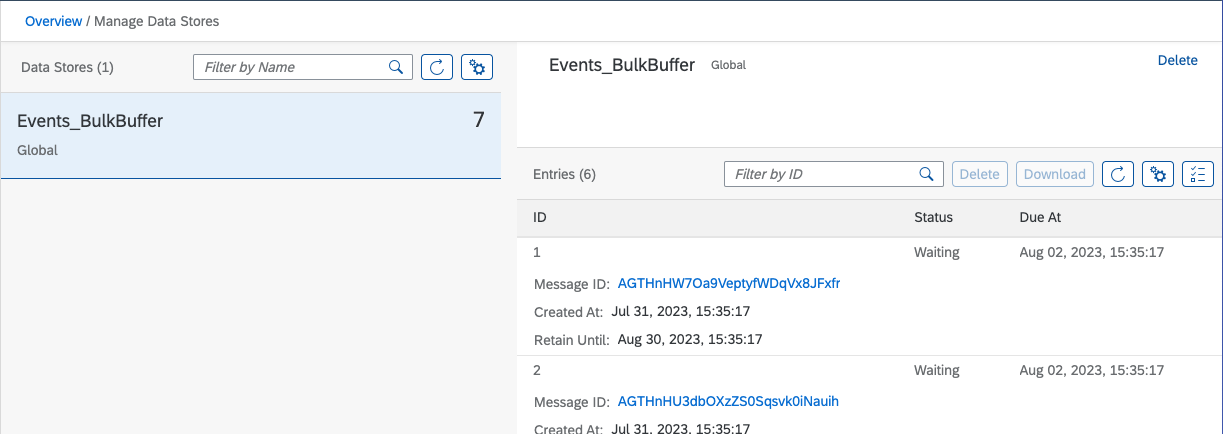
After deploying this flow, the data store will have messages that start to come in, awaiting further processing:
2. Receiving a batch of events to process in HANA

In this flow, the
Select Messages step (Persistence > Data Store Operations > Select) defines how many messages will (maximum) be fetched from the data store at once. I set it to 50 messages. More than enough to process all my events, with even some buffer to make sure that if - for whatever reason - my flow has a temporary outage and needs to catch-up afterwards it can do so at a fast pace:

Note that the bulk fetching of messages from the data store introduces a new XML elements (
messages) in your payload. The outcome of this step will be:
<messages>
<message id="1">
<access>
<id>1</id>
<value>200</value>
</access>
</message>
<message id="2">
<access>
<id>2</id>
<value>350</value>
</access>
</message>
... up to 48 more
</messages>
So to prepare this payload for HANA, the
Set Payload step (a Content Modifier) needs to do 2 things: strip the payload from the additional XML elements and encapsulate it into a XML SQL statement.
We can use an exchange property to get a list of
access elements:

... which we then use in the message body to set the HANA payload:
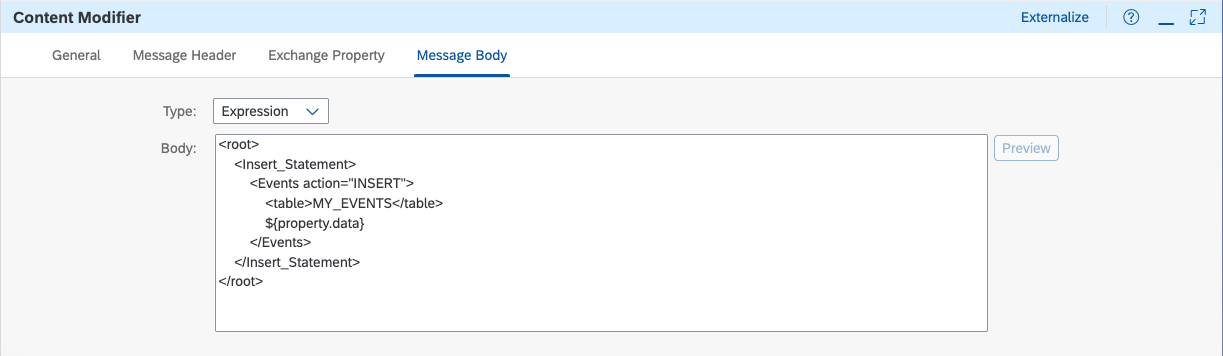
Doing so will give us the final payload for HANA having all our 50 (or less) insert statements in 1 query:
<root>
<Insert_Statement>
<Events action="INSERT">
<table>MY_EVENTS</table>
<access>
<id>1</id>
<value>200</value>
</access>
<access>
<id>2</id>
<value>350</value>
</access>
... up to 48 more
</Events>
</Insert_Statement>
</root>
The Result
The initial approach had a bottleneck to scale above 2 messages per second. With the new approach, randomly configured for a batch of 50 message per interval of 5 seconds we can easily scale to 10 messages per second or more.
The processing log below shows us a concurrent rate of about 2 messages per second, being stored in the data store very fast (only 12 to 13ms), and propagated into HANA with a 500-600ms bulk insert every 5 seconds. So, problem solved!

Feel free to leave a comment below or reach out to me for any questions or advice.
Pro Tip: Are you a developer or integration designer who already knows his/her way around SAP BTP? Then find out how to build integrations from and to cloud applications with SAP’s free learning content on SAP Integration Suite. Check out even more role-based learning resources and opportunities to get certified in one place on SAP Learning site.
