
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- HANA based BW Transformation - New features delive...
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Advisor
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
08-29-2016
1:41 PM
4 HANA based BW Transformation - New features delivered by 7.50 SP04
This blog is part of the blog series HANA based BW Transformation.
Following new features are shipped with the BW 7.50 Support Package 04 (feature pack):
- SQL Script (AMDP) based Start-, End-, and Field Routines
- Error Handling
4.1 Mixed implementation (HANA / ABAP)
In a stacked data flow it is possible to mix HANA executed BW transformation (Standard push down or SQL Script) and ABAP Routines. In case of a mixed scenario it is important that the lower level BW transformations are HANA push down capable. Lower level means the transformation is executed closer to the source object.
Figure 4.1 shows a stacked data flow with one InfoSource in between, see (1). The upper BW transformation (2) contains an ABAP start routine, therefore only the ABAP runtime is supported. In the lower BW transformation (3) only standard rules are used, therefore both the HANA and ABAP runtime are supported.
Despite the fact that in the data flow an ABAP routine is embedded, the DTP setting does support the SAP HANA execution, see (4) if the SAP HANA execution flag is set and the processing mode switch is set to (H) Parallel Processing with partial SAP HANA Execution, see (5).
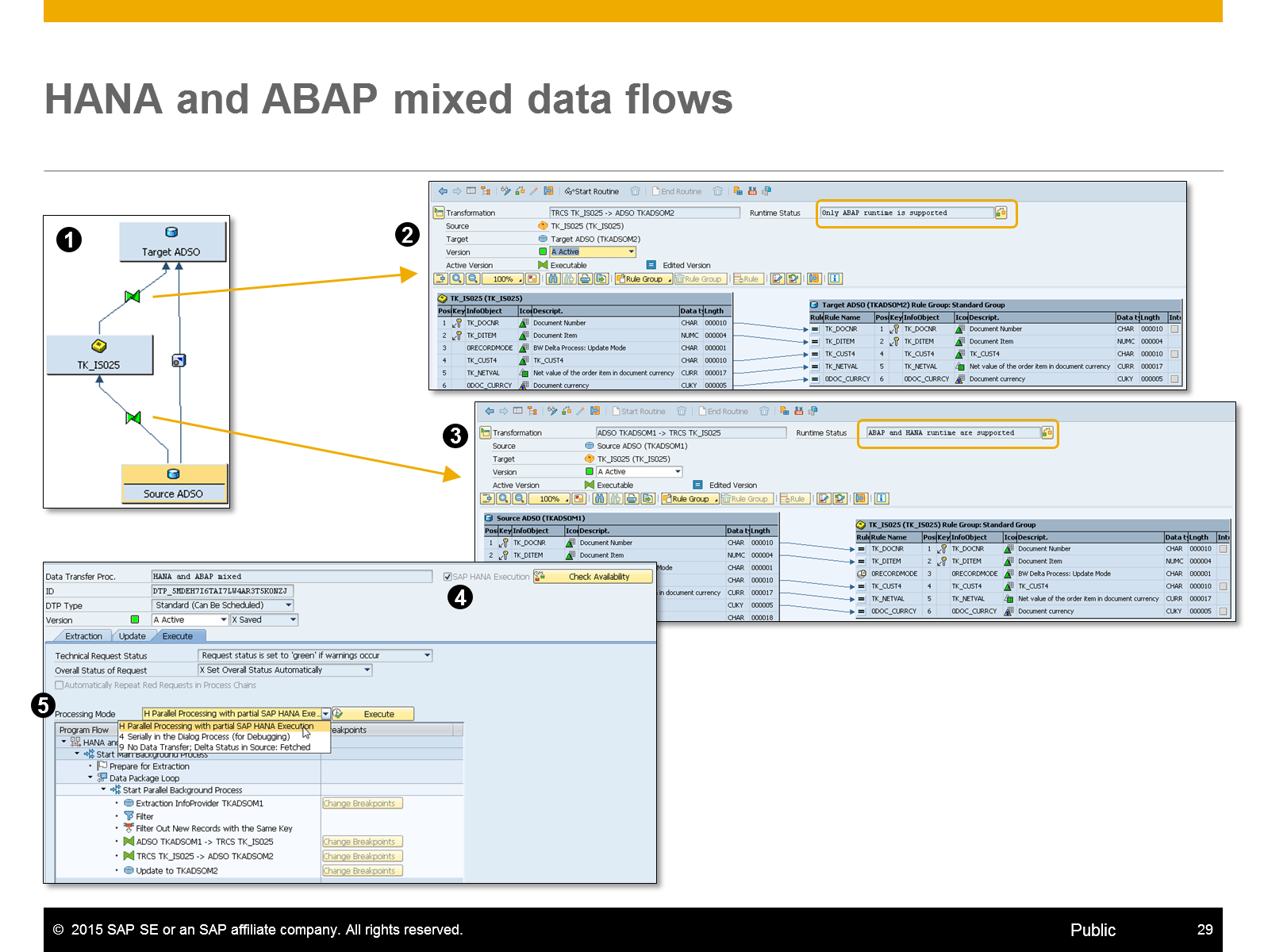
Figure 4.1: HANA and ABAP mixed data flows
4.1.1 Restriction in mixed data flows (Added on 03/07/2017)
In a mixed data flow (SAP HANA and ABAP processing) it is not possible to enable the error handling. For a mixed data flow, the DTP flag SAP HANA Execution is set and the flag is grayed out. That means the first part of the data flow must be executed in the HANA processing mode.
The attempt to activate the error handling results in the message in Figure 4.1b.

Figure 4.1b: Mixed data flow and error handling
If the error handling is absolutely necessary, an intermediate persistence may have to be integrated into the data flow.
4.2 Routines
SAP Help: What's new - Routines in Transformations?
With BW 7.50 SP04 all BW Transformation routines can be implemented in ABAP or in SQL Script. Figure 4.2 shows the available routine types in a BW transformation context.

Figure 4.2: Available Routines in BW transformations
With BW 7.50 SP04 the concept and therefore the menu structure to create / delete a new routine changed. With BW 7.50 SP04 all routines, Start-, Field-, End- and Expert-Routines can be implemented ABAP or SQL Script based. It is not possible to mix ABAP and SQL Script routines within one transformation.
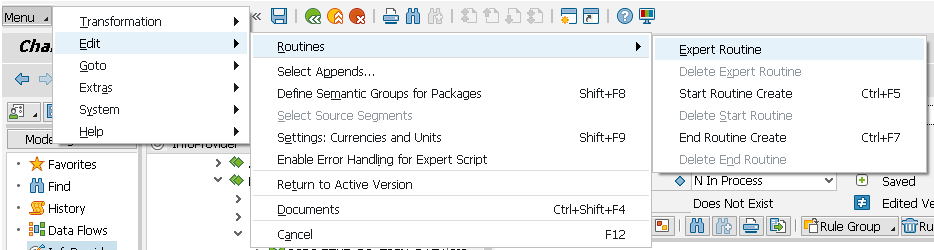
Figure 4.3: Routines in BW transformation
The transformation framework always tries to offer both execution modes, ABAP and HANA. For more information see the main blog of this series.
By implementing the first routine of a BW transformation the system asks for the implementation type (ABAP or SQL Script (AMDP Script)). Figure 3.1 shows the different routine implementation types and the impact on the execution mode of the selected implementation type.

Figure 4.4: Routine implementation type
Initially both execution modes (1), ABAP and HANA, are possible (unless you are using a feature which prevents a push down). The implementation type decision for the first routine within a BW transformation sets the implementation type for all further routines within this BW transformation. The dialog (2) will only come up for the first routine within a BW transformation. If you choose ABAP routine for the first routine the Runtime Status will change from ABAP and HANA runtime are supported to Only ABAP runtime is supported (3). If you choose AMDP script for the first routine the Runtime Status changes to Only HANA runtime is supported (4).
4.2.1 General routine information
For each SQL Script (Start, End, Field and Expert) routine a specific AMDP - ABAP class is created. For more information about the AMDP - ABAP class see paragraph 1.2.2.2 »The AMDP Class« in the initial blog »HANA based BW Transformation« of this blog series.
Only the method body (including the method declaration) is stored in the BW transformation metadata. You can find the source code of all BW transformation related routines (methods / procedures) in the table RSTRANSTEPSCRIPT.
| Table replacement for expert routines |
|---|
| Up to BW 7.50 SP04 the procedure source code for SAP HANA Expert Scripts is stored in the table RSTRANSCRIPT. With BW 7.50 SP04 the storage location for AMDP based routines has been changed. With BW 7.50 SP04 the source code for all AMDP based routines (in the context of a BW transformation) will be stored in the table RSTRANSTEPSCRIPT |
The column CODEID provides the ID for the ABAP class name. To get the full ABAP class name it is necessary to add the prefix “/BIC/” to the ID.
The generated AMDP - ABAP classes are not transported. Only the metadata, including the method source code are transported. The AMDP – ABAP classes are generated in the post processing transport step in the target system during the BW transformation activation.
4.2.2 Routine Parameter
Parallel to the routines (Start-, End- and Field-Routines), error handling was also delivered with BW 7.50 SP04. As a result the method declaration has changed, including the SAP HANA Expert Script. To keep existing SAP HANA Expert Scripts valid the method declaration will not change during the upgrade to SP04, for more information see paragraph 4.2.3 »Flag - Enable Error Handling for Expert Script«.
4.2.2.1 Field SQL__PROCEDURE__SOURCE__RECORD
The field SQL__PROCEDURE__SOURCE__RECORD is part of all structured parameters. The field can be used to store the original source record value of a row.
Figure 4.5 shows an example how to handle record information during the transformation and the error handling. In the example data flow the source object is a classic DataStore-Object (ODSO).
The sample data flow uses two transformations both implement a SQL Script (Start-, End- or Expert- Routine).
The inTab of the first SQL Script (AMDP Script (1)) contains information about the source data in this example the source object provides technical information to create a unique identifier for each row. If you are reading data from the active table (see DTP adjustments) of an ODSO it is not possible to get the necessary information from the source. In this case both columns RECORD and SQL__PROCEDURE__SOURCE__RECORD are set to initial. The SQL Script does not contain logic to handle erroneous records.
If the source provides technical information to create a unique identifier both columns RECORD and SQL__PROCEDURE__SOURCE__RECORD will be populated. In the inTab the content of both columns are the same. The columns will be created by concatenating of the technical field REQUID, DATAPAK and RECORD for an ODSO and REQUEST TSN, DATAPAK and RECORD for an ADSO.
The field REQUEST (see Source in Figure 4.5) cannot be used as an order criteria, because of the generated values. Therefore the related SID (see /BI0/REQUID in Figure 4.5) is used.

Figure 4.5: Source record information
The second BW transformation also contains a SQL Script (AMDP Script (2)) to verify the transferred data and identify erroneous records. The row with the record ID 4 is identified as an erroneous record. Therefore a new entry with the original record ID from the source object is written to the errorTab. The original record ID is still stored in the column SQL__PROCEDURE__SOURCE__RECORD .
For this example, the business logic requires to multiply some source rows. To get a unique sort able column the column RECORD must re-calculated with new unique sorted values. For the multiplied records the source record information in the column SQL__PROCEDURE__SOURCE__RECORD is untouched.
The field RECORD is a character-based data type (type C length 56) and not a numeric-based data type! That means the value you create to determinate the sort order must be respect that.
Figure 4.6 shows in the upper part a SQL call to generate a new numeric value. The two tables below the SQL statement highlight the problem we get with that kind of values. Within the transformation logic (the CalculationScenario) the routine result is sorted by the column RECORD, which leads into an unexpected sort order (Sorted result). Because the values are interpreted as character values and not as numbers.
The second SQL statement generate the unique values as character like values. Now the sorted result is in the expected order.
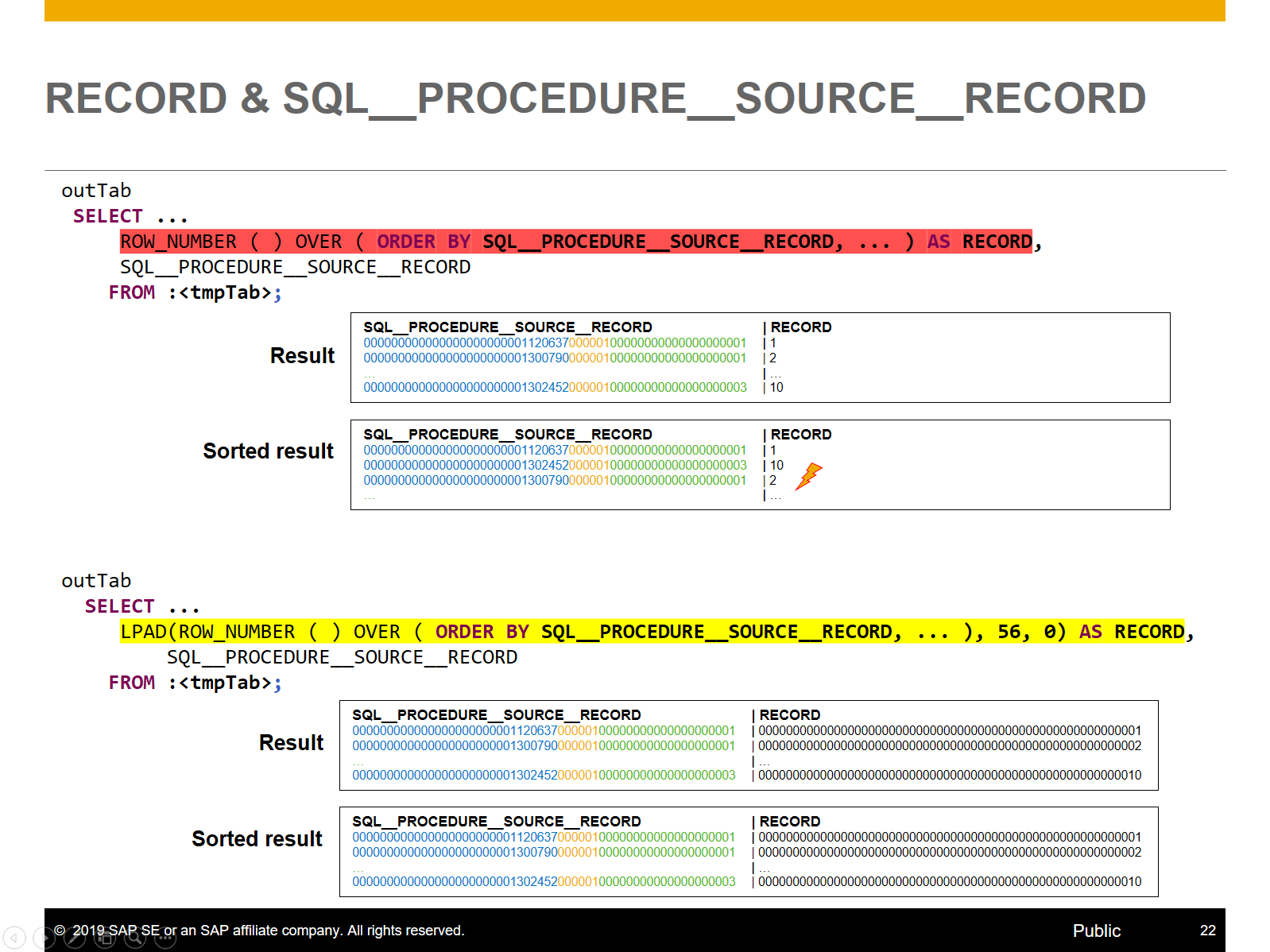
Figure 4.5: Unique RECORD value
This example explains the purpose off the column SQL__PROCEDURE__SOURCE__RECORD . I’ll provide more details about the error handling in paragraph 4.3 »Error Handling«.
4.2.2.2 Common Parameter
The following parameters are available in all new SQL Script routine created after the upgrade to BW 7.50 SP04:
- errorTab (table) and
- I_ERROR_HANDLING (field)
In addition the field SQL__PROCEDURE__SOURCE__RECORD is a member the importing parameter inTab and the exporting parameter outTab, with the exception of the field routine exporting parameter outTab.
The error handling related parameters (I_ERROR_HANDLING, errorTab and the additional field SQL__PROCEDURE__SOURCE__RECORD ) are only available if the flag Enable Error Handling for Expert Script is set, see paragraph 4.2.3 »Flag - Enable Error Handling for Expert Script«.
There is a special handling for existing SAP HANA Expert Scripts which were created before upgrading to SP04. To preserve the customer code, for existing SAP HANA Expert Script the flag is not set by default. Therefore the error related parameters are not been added for existing SAP HANA Expert Scripts.
The input parameter I_ERROR_HANDLING is an indicator to mark the current processing step as error handling step, for further information see paragraph 4.3 »Error Handling«.
The export parameters errorTab is used as part of the error handling to identify erroneous records, for further information see paragraph 4.3 »Error Handling«.
All output table parameter of an AMDP method must be assigned. Otherwise the AMDP class is not valid. In case you are not using the error handling the output table parameter errorTab must be assigned by using a dummy statement. The following statement can be used to return an empty errorTab :
errorTab =
SELECT '' AS ERROR_TEXT,
'' AS SQL__PROCEDURE__SOURCE__RECORD
FROM DUMMY
WHERE DUMMY <> 'X';
4.2.2.3 Start- and End-Routine Parameter
The Start- End-, and Expert Routine all have the same method declaration:
class-methods PROCEDURE
importing
value(i_error_handling) type STRING
value(inTab) type <<Class-Name>>=>TN_T_IN
exporting
value(outTab) type <<Class-Name>>=>TN_T_OUT
value(errorTab) type <<Class-Name>>=>TN_T_ERROR .
Only the type definition of the structures TN_T_IN and TN_T_OUT are different between the routines.
In case of the start routine the inTab (TN_T_IN ) and the outTab (TN_T_OUT ) structure are identical and can be compared with the SOURCE_PACKAGE in the ABAP case. It is possible to adjust the structure of the inTab for a start routine.
In case of the end routine the inTab (TN_T_IN ) and the outTab (TN_T_OUT ) structure are identical and can be compared with the RESULT_PACKAGE in the ABAP case. It is possible to adjust the structure of the inTab for an end routine.
In case of the SAP HANA Expert Script routine the inTab (TN_T_IN ) can be compared with the SOURCE_PACKAGE in the ABAP case and the outTab (TN_T_OUT ) can be compared with the RESULT_PACKAGE in the ABAP case. The inTab always contains all fields from the source object and can not be adjusted.
4.2.2.4 Field-Routine Parameter
The procedure declaration is exactly the same as the declaration for the Start- End-, and Expert Routine:
class-methods PROCEDURE
importing
value(i_error_handling) type STRING
value(inTab) type <<Class-Name>>=>TN_T_IN
exporting
value(outTab) type <<Class-Name>>=>TN_T_OUT
value(errorTab) type <<Class-Name>>=>TN_T_ERROR.
The inTab contains the source field(s) and in addition the columns RECORD and SQL__PROCEDURE__SOURCE__RECORD, see paragraph 4.2.2.1 »Field SQL__PROCEDURE__SOURCE__RECORD«.
| Important difference to ABAP based field routines |
|---|
| A field routine in the ABAP context is called row by row. The routine only gets the values for the current processing line for the defined source fields. In the HANA context a field routine is called once per data package. And the importing parameter (inTab ) contains all values of the source field columns, see Figure 4.2. |
I’ll provide more information about the difference in processing between SQL Script and ABAP in paragraph 4.2.5 »Field-Routine«.
4.2.3 Flag - Enable Error Handling for Expert Script
For all SAP HANA Expert Scripts created with a release before BW 7.50 SP04 it is necessary to enable the error handling explicitly after the upgrade. To set the flag go to Edit => Enable Error Handling for Expert Script.
To ensure that the existing SAP HANA Expert Script implementations are still valid after the upgrade to BW 7.50 SP04 the method declaration will be left untouched during the upgrade.
After the upgrade to BW 7.50 SP04 all new created SQL Script routines will been prepared for the error handling and the flag, see Figure 4.6, will be set by default.

Figure 4.6: Enable Error Handling for Expert Script
4.2.4 Start-Routine
Typical ABAP use cases for a start routine are:
- Delete rows from the source package that cannot filtered by the DTP
- Prepare internal ABAP table for field routines
| General filter recommendation |
|---|
| If possible, try to use the DTP filter instead of a start routine. Only use a start routine to filter data if the filter condition cannot be applied in the DTP. Also ABAP routines and BEx variable can be used in the DTP filter without preventing a push down, see blog »HANA based BW Transformation«. |
Using a filter in a start routine is still a valid approach in the push down scenario to reduce unnecessary source data. Figure 4.7 shows the steps to create an AMDP based start routine to filter the inTab (source package) with a filter condition that cannot applied in the DTP filter settings.

Figure 4.7: AMDP Start Routine Sample
The second use case for an ABAP start routine is not a recommended practice in the context of a push down approach. Remember that the data in a push down scenario is not processed row by row. In a push down approach the data are processed in blocks. Therefore we do not recommend to use a field routine to read data from a local table like we do in ABAP. Further on the logic of an AMDP field routine differs from an ABAP based field routine, see paragraph 4.2.5 »Field-Routine«. The better way in a push down scenario is to read data from an external source using a JOIN in a routine
4.2.5 Field-Routine
A field routine can typically be used if the business requirement cannot be implemented with standard functionalities. For example if you want to read data from an additional source such as an external (non BW) table. Or you want to read data from a DataStore-Object but the source doesn’t provide the full key information which prevents the usage of the standard DSO read rule.
Figure 4.8 shows the necessary steps to create an AMDP Script based field routine. Keep in mind that AMDP based routines can only be created in the Eclipse based BW and ABAP tools. The first step to create an AMDP Script based field routine is the same as for an ABAP based field routine, see (1). If you select the rule type ROUTINE a popup dialog asks for the processing type, see (2). Choose AMDP script to create an AMDP script based field routine. The BW Transformation framework opens the Eclipse based ABAP class editor. For this an ABAP project is needed, see (3). Please note that the popup dialog sometimes opens in the background. The popup lists the assigned ABAP projects. If there is no project you can use the New… button to create one. After selecting a project the AMDP class can be adjusted. Enter your code for the field routine in the body of the method PROCEDURE, see (4).

Figure 4.8: Steps to create an AMDP Script based field routine
The SQL script based field routine processing is different from the ABAP based routine. The ABAP based routine is processed row-by-row. The SQL script based routine on the other hand is only called once per data package, like all the other SQL script based routines.
Because of this all values of the adjusted source fields are available in the inTab. For all source field values the corresponding RECORD and the SQL_PROCEDURE_SOURCE_RECORD information are available in the inTab.
For SQL Script based field routines the following points need to be considered:
- The target structure requires for each source value exactly one value.
- The outTabinTab sort order may not be changed.
- The result value must be on the same row number as the source value
In case of using a join operator pay attention that inner join operations could lead in a subset of rows.
4.2.6 End-Routine
Typical ABAP use cases for an end routine are post transformation activities, such as:
- Delete rows which are obsolete after the data transformation, for example redundant rows
- Line cross-data check
- Discover values for a specific column based on the transfer result
From the development perspective the end routine is quite equal to the start routine. Only the time of execution differs. The start routine is before the transformation and the end routine afterwards.
4.3 Error Handling
In previous BW 7.50 SP’s switching on error handling in a DTP prevented a SAP HANA push down. As of BW 7.50 SP4 this is no longer the case and enabling error handling in a DTP will not prevent a SAP HANA push down.
A DTP with enabled error handling processes the following steps:
- Determine erroneous records
- Determine semantic assigned records to:
- The new erroneous records
- The erroneous records in the error stack
- Transfer the non-erroneous records
Therefore it is necessary to call the transformation twice. The first call will determine the erroneous records (1. Step) and the second call transfers the non-erroneous records (3. Step).
The error handling is only available for data flows with DataSource (RSDS), DataStore-Object classic (ODSO) or DataStore-Object advanced (ADSO) as source object and DataStore-Object classic (ODSO), DataStore-Object advanced (ADSO) or Open Hub-Destination (DEST) as target object.
4.3.1 Error handling background information
Here is some general background information about the technical runtime objects and the runtime behavior.
| DTP with error handling and the associated CalcScenario |
|---|
| In the blog HANA based Transformation (deep dive) in paragraph 2.1 » Simple data flow (Non-Stacked Data Flow)« I’ve explained that the DTP in case of an non-stacked data flow reuses the CalculationScenario from the BW transformation. If the error handling is switched on in the DTP, the BW Transformation Framework must enhance the CalculationScenario for the error handling. Therefore it is necessary to create an own CalculationScenario for the DTP. The naming convention is the same as for a DTP for a stacked data flow. The unique identifier from the DTP is used and the DTP_ is replaced by TR_. |
| Difference regarding record collection between HANA and ABAP |
|---|
The HANA processing mode collects all records from the corresponding semantic group in the current processing data package where the erroneous record belongs to and writes them to the error stack, see Figure 4.9. All records with the same semantic key in further processing data packages are also written to the error stack. The ABAP processing mode writes only the erroneous record for the current processing package to the error stack. Further packages are handled in the same way as in the HANA processing mode. All records with the same semantic key are also written to the error stack. |
4.3.1.1 Find the DTP related error stack
The related error stack (table / PSA) for a DTP can be found by the following SQL statement:
SELECT "TABNAME"
FROM "DD02V"
WHERE "DDTEXT" like '%<<DTP>>%';
4.3.2 Error handling in a standard BW transformation
Fundamentally, the error handling in the execution mode SAP HANA behaves very similar to the execution mode ABAP. There are some minor topics to explain regarding the SAP HANA processing of artefacts like runtime and modelling objects. In the next section we will also discuss differences in how the error handling is executed.
Figure 4.9 provides an example how error handling works in a BW transformation with standard transformation rules (meaning: no customer SQL script coding).
The business requirement for the BW transformation is to ensure that only data with valid customer (TK_CUST) is written in the target. Valid customer means, for the customer master data is available. This means the flag Referential Integrity is set for the TK_CUST transformation rule.
| Semantic Groups |
|---|
In the context of SAP HANA processing semantics groups are not supported! The error handling defines an exception for this limitation. The semantic group in combination with the error handling is used to identify records that belong together. You cannot use the error handling functionality to work around the limitation and artificially build semantic groups for SAP HANA processing. That means the processing data packages are not grouped by the defined semantic groups. The data load process ignores the semantic groups. |
The logic implemented in the sample data flow in Figure 4.9 writes only data for a Sales Document (DOC_NUMER) to the target if all Sales Document Items (S_ORD_ITEM) are valid. This means in case one item is not valid all items for the related Sales Document should be written to the error stack. Therefore I chose Sales Document (DOC_NUMER) as semantic group.
In the source is one record with an unknown customer (C4712) for DOC_NUMER = 4712 and S_ORD_ITEM = 10. The request monitor provides some information how many records are written to the error stack. The detail messages provides more information about the reason.
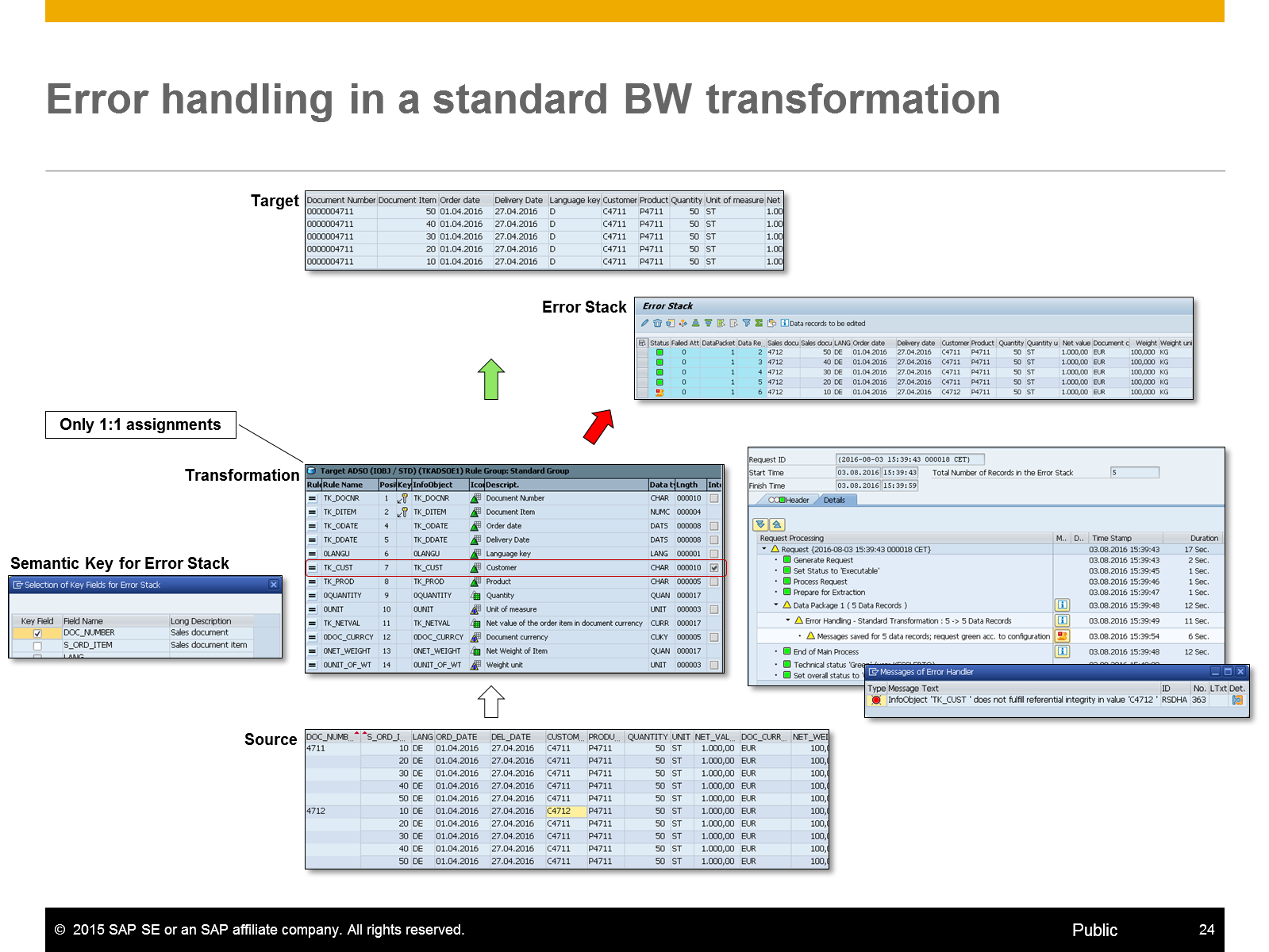
Figure 4.9: Error handling in a standard BW transformation
The initial erroneous record of a group is marked in the error stack. The erroneous data can be adjusted and repaired within the error stack, if possible. If the transaction data or master data are corrected the data can be loaded from the error stack into the data target by executing the Error-DTP.
4.3.3 Error handling and SQL Script routines
In case of using SQL script routines within a BW transformation the BW transformation framework sets a flag to identify which processing step 1st or 3rd is currently being processed. Therefore all SQL script procedure (AMDP method) declarations will be enhanced, see paragraph 4.2.2 »Routine Parameter«. The following parameters are related to the error handling:
- I_ERROR_HANDLING
The indicator is set to ‘TRUE’ when the BW transformation framework executes step 1, otherwise the indicator is set to ‘FALSE ‘.
In this case the BW transformation framework expects only the erroneous records in the output parameter errorTab.
- errorTab
The output table parameter can be used to handover erroneous records during the 1st call.
The error table structure provides two fields:
- ERROR_TEXT
- SQL__PROCEDURE__SOURCE__RECORD
- SQL__PROCEDURE__SOURCE__RECORD
- SQL__PROCEDURE__SOURCE__RECORD
The data input structure (inTab) is enhanced by the field SQL__PROCEDURE__SOURCE__RECORDfor all routines (Start-, Field-, End- and Expert routine).
The data output structure (outTab) for the Start-, End- and Expert routine is also enhanced by the field SQL__PROCEDURE__SOURCE__RECORD.
The field SQL__PROCEDURE__SOURCE__RECORDis be used to store the original record value from the persistent source object. For more information see paragraph 4.2.2.1 »Field SQL__PROCEDURE__SOURCE__RECORD«.
Next I’ll explain the individual steps how a BW transformation is processed using an example. As mentioned before, the following steps are processed in case the error handling is used:
- Determine erroneous records
- Determine semantic assigned records to:
- The new erroneous records
- The erroneous records in the error stack
- Transfer the non-erroneous records
Only step 1 and 3 must be considered in the SQL script implementation. Step 2 and the sub steps are processed internally from the BW transformation framework.
Figure 4.10 provides an overview how the error handling will be processed. To illustrate the runtime behavior I keep the logic to identify the erroneous records quite simple. The source object contains document item data for two documents (TEST100 and TEST200) for the first one five and for the second one four items are available. The record TEST100, Document Item 50 contains a not valid customer C0815, see (1). To ensure that only document information are written into the target if all items for the document are valid I set the semantic key to document number (/BIC/TK_DOCNR), see (2). The procedure coding contains two parts. The first part supplies the data for the errorTab and the second part the data for the outTab, see (3). The procedure is called twice during the processing. The first call is to collect the erroneous records, see Figure 4.11. Based on the errorTab result the BW transformation framework determines the corresponding records regarding the errorTab and the semantic key. The collected records are written to the error stack see (4). The second procedure call is to determine the non-erroneous records. As a result the collected erroneous records will be removed from the inTab before the second call is executed, see Figure 4.12. The outTab result from the second call is written into the target object, see (5).

Figure 4.10: Error handling with SQL script
Figure 4.11 shows the procedure from the sample above in the debug mode during the first call to determine the erroneous records. The parameter I_ERROR_HANDLING is set to TRUE , see (1). Only the first statement to fetch the result for the output parameter errorTab is relevant for this step, see (2). In my coding sample the second SELECT statement will also be executed but the result parameter outTab is not used by the caller. For simplicity I have kept the logic here as simple as possible, but note that from a performance perspective there are better options. The result from the SELECT statement to detect the erroneous records is shown in (3). Based on the SQL_PROCEDURE__SOURCE_RECORD ID the BW transformation framework determines the corresponding semantic records from the source and writes them to the error stack.

Figure 4.11: Error handling with SQL script – Determinate erroneous records
The next step is to transfer the non-erroneous records. The BW transformation framework calls the SQL script procedure a second time, see Figure 4.12. Now the parameter I_ERROR_HANDLING is set to FALSE , see (1). From the coding perspective, see (2), only the second part to get the outTab result is relevant. The inTab , see (3), now contains only source data which can be transferred without producing erroneous result information.

Figure 4.12: Error handling with SQL script – Transfer the non-erroneous records
- SAP Managed Tags:
- BW Data Modeling (WHM),
- BW Data Staging (WHM),
- BW SAP HANA Data Warehousing
Labels:
132 Comments
- « Previous
- Next »
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,658 -
Business Trends
107 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
72 -
Expert
1 -
Expert Insights
177 -
Expert Insights
340 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
GraphQL
1 -
Kafka
1 -
Life at SAP
780 -
Life at SAP
14 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,575 -
Product Updates
384 -
Replication Flow
1 -
REST API
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,872 -
Technology Updates
472 -
Workload Fluctuations
1
Related Content
- What’s New in SAP Datasphere Version 2024.10 — May 7, 2024 in Technology Blogs by Members
- SAP BTP FAQs - Part 1 (General Topics in SAP BTP) in Technology Blogs by SAP
- B2B Business Processes - Ultimate Cyber Data Security - with Blockchain and SAP BTP 🚀 in Technology Blogs by Members
- Terraform Provider for SAP BTP version 1.3.0 - what’s new in Technology Blogs by SAP
- SAP Datasphere News in April in Technology Blogs by SAP
Top kudoed authors
| User | Count |
|---|---|
| 17 | |
| 14 | |
| 12 | |
| 10 | |
| 9 | |
| 8 | |
| 7 | |
| 7 | |
| 6 | |
| 6 |