This blog explains replication from SAP HANA Platform on-premises to SAP HANA Cloud only. If your interest is more about general replication with various SAP solutions and external data, please check out the
Data Intelligence Cloud as part of our Data Manatement Portfolio
In my previous blog
Replication Service to easily setup replication from SAP HANA on-premise to SAP HANA Cloud, I’ve shown how tables can be easily replicated from an SAP HANA Platform on-premises to SAP HANA Cloud using Replication Service.
Since then we now support
- HANA native replication using remote table replication.
If the source SAP HANA Platform is 2.0 SPS05 or higher, native RTR is used for replicating data. The details of remote table replication is described in A new approach for replicating tables across different SAP HANA systems by my colleague Lee, Seungjoon and a step by step tutorial.
- Replicate calculation views with a few simple clicks.
When a calculation view is selected for replication, the runtime metadata is extracted from the source system and parsed to get the definition of the calculation view and retrives all dependent objects. This can be other nested calculation views, hierarchy information and tables. For nested calculation views, the metadata is again extracted and parsed until all dependent objects have been identified as tables. The tables will be replicated in real-time or loaded once based on the schedule settings. The calculation view runtime objects will be built from bottom up until the final selected calculation view is built on the target side.
One point that needs to be emphasized is that only the runtime objects of the calculation view are being replicated and not the design time. The runtime is the column view that are accesible using SQL while design time is the artifact stored in the repository (XSC) or github (XSA). So, any design changes that is needed for the calculation view needs to be done at the source side which is on-premises and replicated again after the changes. For details of how to update an existing calculation view please check out the details in
SAP Note 3133975.
If the replicated calculation view needs to be extended to create another calculation view in SAP HANA Cloud, the replicated calculation view can be referenced as column view consumed as a synonym inside a HDI container.
The benefits of replicating a calculation view runtime is
- Easy to extend an existing analytical workload running on-premises to the cloud with a few simple clicks
- Offload workload dynamically to any region running SAP HANA Cloud on demand
- Replicate to multiple regions extending global reach
- Expand existing workloads with latest features available with every SAP HANA Cloud enhancement releases

Replication Service
Now lets go over the steps on how we can replicate a calculation view.
Pre-requisites for technical user for source system
- A technical user for running replication setup. This user should not be the owner of the schema being replicated but a technical user without being an owner.
- For replicating calculation views, runtime metadata is extracted from the source system.
- SYSTEM user is mandatory for SAP HANA 2.0 SPS05 Rev59 or lower
- Apply the workaround mentioned in SAP Note 3133975. to use a technical user other than SYSTEM for higher than SAP HANA 2.0 SPS05 Rev59
- CATALOG READ
- SELECT privilge
- SCHEMA (XSC based tables and calculation views)
- HDI Container Schema (XSA based tables and calculation views)
- Objects to be replicated
Steps to replicate a calculation view
- Logon to SAP HANA Cockpit and goto Replication Service card found under Monitoring and select Create Replication

- For creating a New Connection, there are 2 options to select from SAP HANA 2.0 SPS05 or SPS04 or lower. The difference between the 2 is SPS05 or higher uses the native data replication called remote table replication while earlier version requires SDI to be used. I will use the SPS05 or higher

- Create a remote source using SAP with Cloud Connector selected. The Location ID is optional based on the cloud connector. This is normally set when multiple cloud connector is used and each defined with a different location id. Using the cloud connector allows SAP HANA Cloud connect to the SAP HANA Platform on-premises using SDA connection which is mandatory for remote table replication.

- Once the remote source is created, SAP HANA Cloud connects to the HANA on-premises through the cloud connector and gets the list of schemas or HDI containers that the technical user have been granted in the pre-requisites. I have created SLPADM for schema based calculation views and SALES for HDI based.
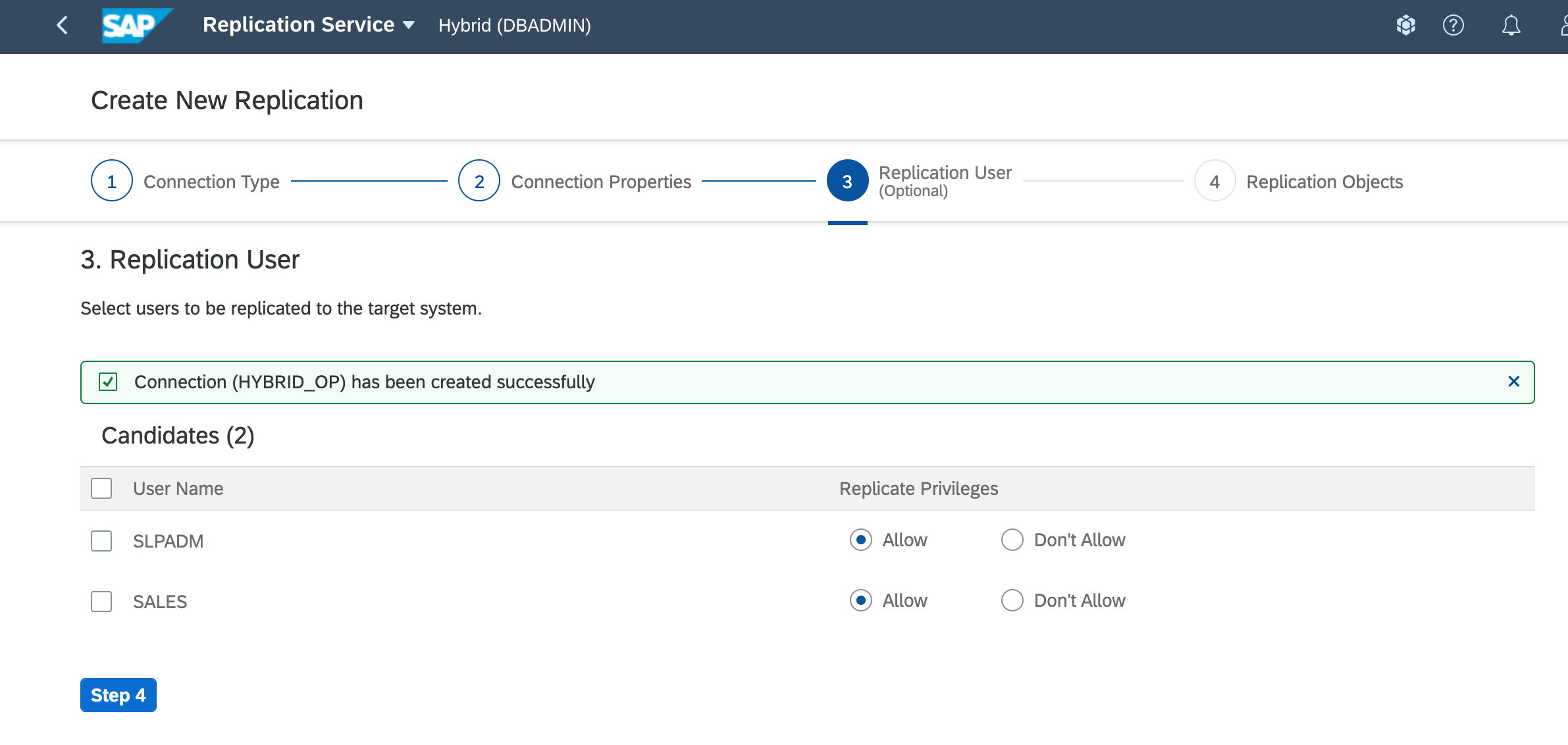
- First, lets step through how a schema (XSC) based calculation view can be replicated by selecting SLPADM. As the password is secured for SLPADM user and cannot be extracted, we need to initialize the password to be used in SAP HANA Cloud.

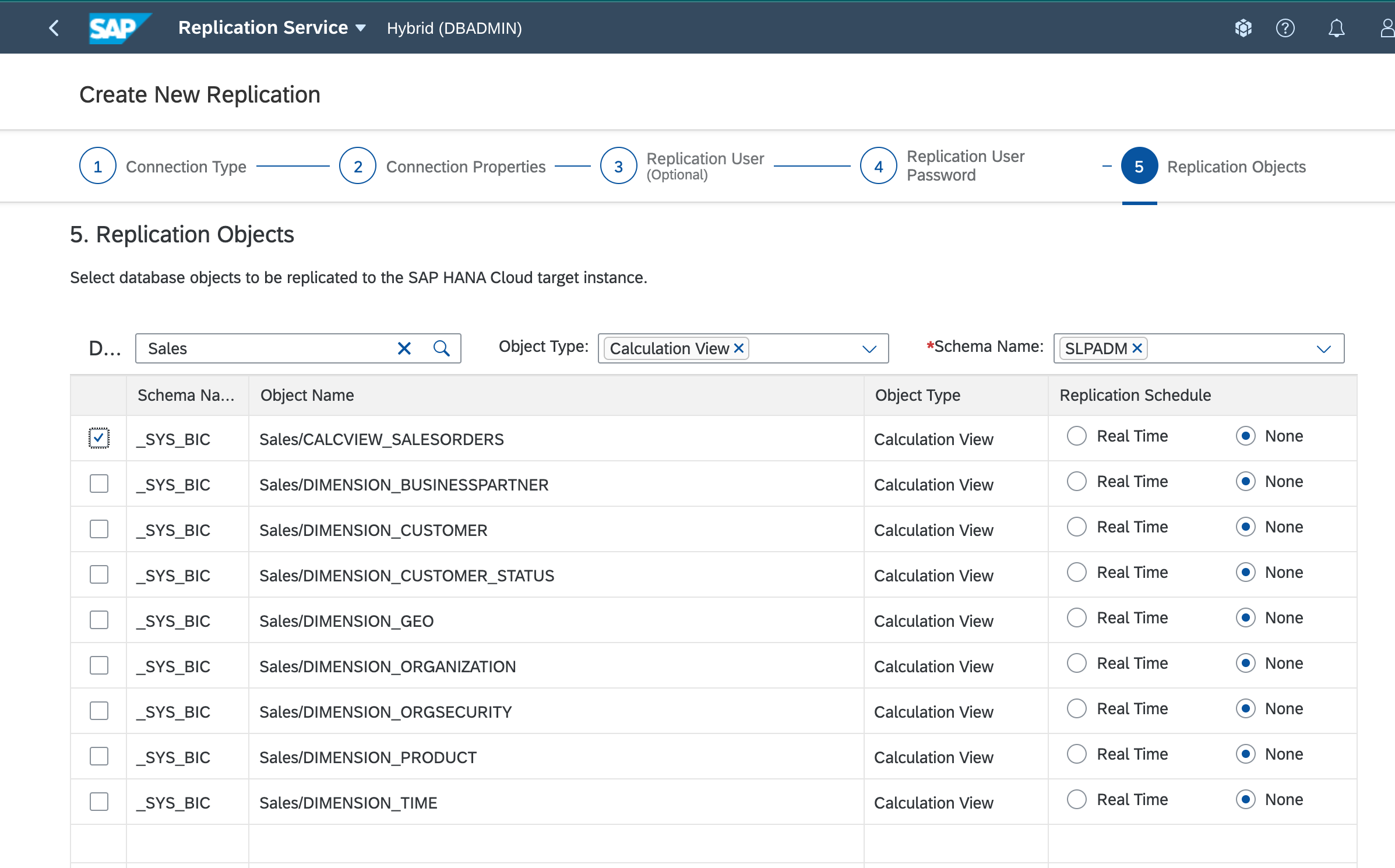
- Once the target schema is created in SAP HANA Cloud, it will retrieve all the objects of the selected schema. The following is a list of calculation views that can be replicated and will select the top most calculation view Sales/CALCVIEW_SALESORDERS as others are nested CVs which gets automatically replicated as it is a dependent object of the selected CV.
- It will now connect to SAP HANA Platform on-premises and retrieve the metadata of the calculation view by importing the BIMC data

- Then retrieves metadata of all dependent objects
- After the initial replication is done, the hierarchy of the dependent objects can be checked with the hierarchy icon

- The dependency objects are all listed which includes tables, hierarchy and other nested calculation views.

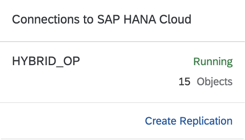
- Once the replication is running the status can be check from the main service card grouped for each remote source
We will now try to add a new calculation view replication based on HDI container schema by on selecting SALES in step 4 above.
- The selected HDI container schema SALES will be created as a normal schema in SAP HANA Cloud and not a HDI container. So, the password needs to be initialized as well.

- Once the target schema is created, the list of objects in the HDI container is extracted. The object name is prefixed “Sales::” whereas it was “Sales/” for normal schema based calculation views

- The calculation view dependent objects in HDI container is replicated. (Currently, we have found an issue when the dependent object is a synonym which will be resolved soon)

We have gone through how we can replicate a calculation view from SAP HANA Platform on-premises to SAP HANA Cloud with just a few simple clicks. The calculation view replication works for both XSC and HDI based without any migration efforts. For 2022, we are planning to close the gaps by supporting replication of Analytic Privilege and how to support calculation views referencing table functions.
We will also publish a detailed easy to follow step by step tutorial extending the existing table replication
tutorial.
The official documentation for Replication Service can be found
here.
There are some limitations which we currently have as mentioned in
SAP Note 3133975 . We will update this SAP Note as we resolve the limitations.
