
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- SAP Data Intelligence Cloud : How to use R Kernel ...
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Product and Topic Expert
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
12-14-2020
12:38 PM
You might already know that you can build complex Machine Learning scenarios as part of your Data Value Journey with SAP Data Intelligence . If not then look at the blog post by andreas.forster and ingo.peter on how to create your first ML scenario in SAP Data Intelligence using Python & R :
SAP Data Intelligence: Create your first ML Scenario
In this blog post you will learn how to start R Kernel inside Notebook in SAP Data Intelligence Cloud to perform Data exploration and Free-Style Data Science and also to test R code before using it in the R Operator available in pipeline modeler.
Although R Kernel is not yet officially available in SAP Data Intelligence Cloud notebook (as of version 2010.29.9) , this blog post will guide you to install one using "conda" on python and will also present a way to load data sets stored in DI DATA LAKE using R library - "reticulate".
Launch a Notebook session inside your ML Scenario:
Select Python 3 Kernel :
Use below "Conda" command to install the R-Kernel :
Note -y option here is for the silent install. (else we get prompted to enter "y"/"yes" to begin the install)
All required/dependent packages will be installed and the final summary is as below :
Before you begin using the newly installed R kernel, remember that the base R install won't have all packages that you need ,for example look at below R code snippet requiring dplyr, sqldf,readxl etc
Let's first learn how to install such R packages.
Execute below command in the python 3 kernel notebook session (same as the one on which we installed R-kernel) to install "dplyr" and this is same as doing install.packages("dplyr") on the R kernel :
Follow the same for other required packages:
Select the Newly installed R-Kernel:
Or use the Launcher to create a new notebook with R kernel :
Let's follow the IRIS R Example to use the R Kernel :
Load the Data:
A basic Filter:
Loading Data from a local CSV ( CSV uploaded in the Jupyter lab session) :

SFO landings Data Reference: https://data.sfgov.org/Transportation/Air-Traffic-Landings-Statistics/fpux-q53t
We will make use of R library "reticulate" (library(reticulate)) to access artifacts stored in DI DATA LAKE using a python script , again this is a workaround which lets us access the shared artifacts.
First install the R reticulate library using the python 3 kernel with conda as below :
Create a new Text file to create a python script and insert below code cell which imports python packages ( sapdi , pandas) , and further defines a function to read a file from DI data lake :
Now Open the Notebook with R-kernel ,Restart the R Kernel before running below commands.
use below commands to load the Data :
Refer Ingo's Blog post and for Dataset use the blog post : SAP Data Intelligence: Create your first ML Scenario
Its often a need in projects to quickly test R Code snippets before we can use them in Data Pipelines, so I hope that above workaround to have a working R kernel in Notebook within SAP Data Intelligence will be helpful.
I would also reiterate that the solution above serves as a workaround to test some of the R code snippets in notebook in SAP DI, and that the R SDK for SAP DI is not yet available ( unlike Python SDK for SAP DI) hence the artifacts stored in SAP DI data lake cannot be directly referenced using R kernel among other limitations( e.g. as is done using "sapdi" python library in SAP Data Intelligence)
Please follow the tag SAP Data Intelligence to get notified on latest updates, or visit the SAP Community page for SAP Data Intelligence to keep learning more: https://community.sap.com/topics/data-intelligence
SAP Data Intelligence: Create your first ML Scenario
SAP Data Intelligence: Create your first ML Scenario with R
In this blog post you will learn how to start R Kernel inside Notebook in SAP Data Intelligence Cloud to perform Data exploration and Free-Style Data Science and also to test R code before using it in the R Operator available in pipeline modeler.
Although R Kernel is not yet officially available in SAP Data Intelligence Cloud notebook (as of version 2010.29.9) , this blog post will guide you to install one using "conda" on python and will also present a way to load data sets stored in DI DATA LAKE using R library - "reticulate".
Launch Notebook inside your ML SCENARIO
Launch a Notebook session inside your ML Scenario:
Select Python 3 Kernel :

Install R Kernel
Use below "Conda" command to install the R-Kernel :
Note -y option here is for the silent install. (else we get prompted to enter "y"/"yes" to begin the install)
!conda install -y -c r r-irkernel
All required/dependent packages will be installed and the final summary is as below :

Install Required R Packages
Before you begin using the newly installed R kernel, remember that the base R install won't have all packages that you need ,for example look at below R code snippet requiring dplyr, sqldf,readxl etc
library("sqldf")
library("dplyr")
library("cluster")
library("tidyverse")
library("reshape2")
library("excel.link")
library("RODBC")
library("randomForest")
library("car")
Let's first learn how to install such R packages.
Execute below command in the python 3 kernel notebook session (same as the one on which we installed R-kernel) to install "dplyr" and this is same as doing install.packages("dplyr") on the R kernel :
conda install r-dplyr
Follow the same for other required packages:
conda install r-reshape2
conda install r-RODBCLaunch a New Notebook with R Kernel

Select the Newly installed R-Kernel:

Or use the Launcher to create a new notebook with R kernel :

Let's follow the IRIS R Example to use the R Kernel :

Load the Data:
library(datasets)
data(iris)
summary(iris)names(iris) <- toupper(names(iris))
library(dplyr)
A basic Filter:

setosa <- filter(iris, SPECIES == "setosa")
head(setosa)
sepalLength5 <- filter(iris, SPECIES == "setosa", SEPAL.LENGTH > 5)
tail(sepalLength5) Loading Data from a local CSV ( CSV uploaded in the Jupyter lab session) :
SFO landings Data Reference: https://data.sfgov.org/Transportation/Air-Traffic-Landings-Statistics/fpux-q53t
Loading Data from SAP DI Data Lake
We will make use of R library "reticulate" (library(reticulate)) to access artifacts stored in DI DATA LAKE using a python script , again this is a workaround which lets us access the shared artifacts.
First install the R reticulate library using the python 3 kernel with conda as below :
conda install r-reticulate
Create a new Text file to create a python script and insert below code cell which imports python packages ( sapdi , pandas) , and further defines a function to read a file from DI data lake :
import pandas as pd
import sapdi
def read_FILE_DL():
ws=sapdi.get_workspace(name='Air_Traffic_SFO')
dc=ws.get_datacollection(name='LANDINGS')
with dc.open('Air_Traffic_Landings_Statistics.csv').get_reader() as reader:
landings = pd.read_csv(reader)
return landings

Now Open the Notebook with R-kernel ,Restart the R Kernel before running below commands.
use below commands to load the Data :
library(reticulate)
source_python("load_data.py")
landings <- read_FILE_DL()
landings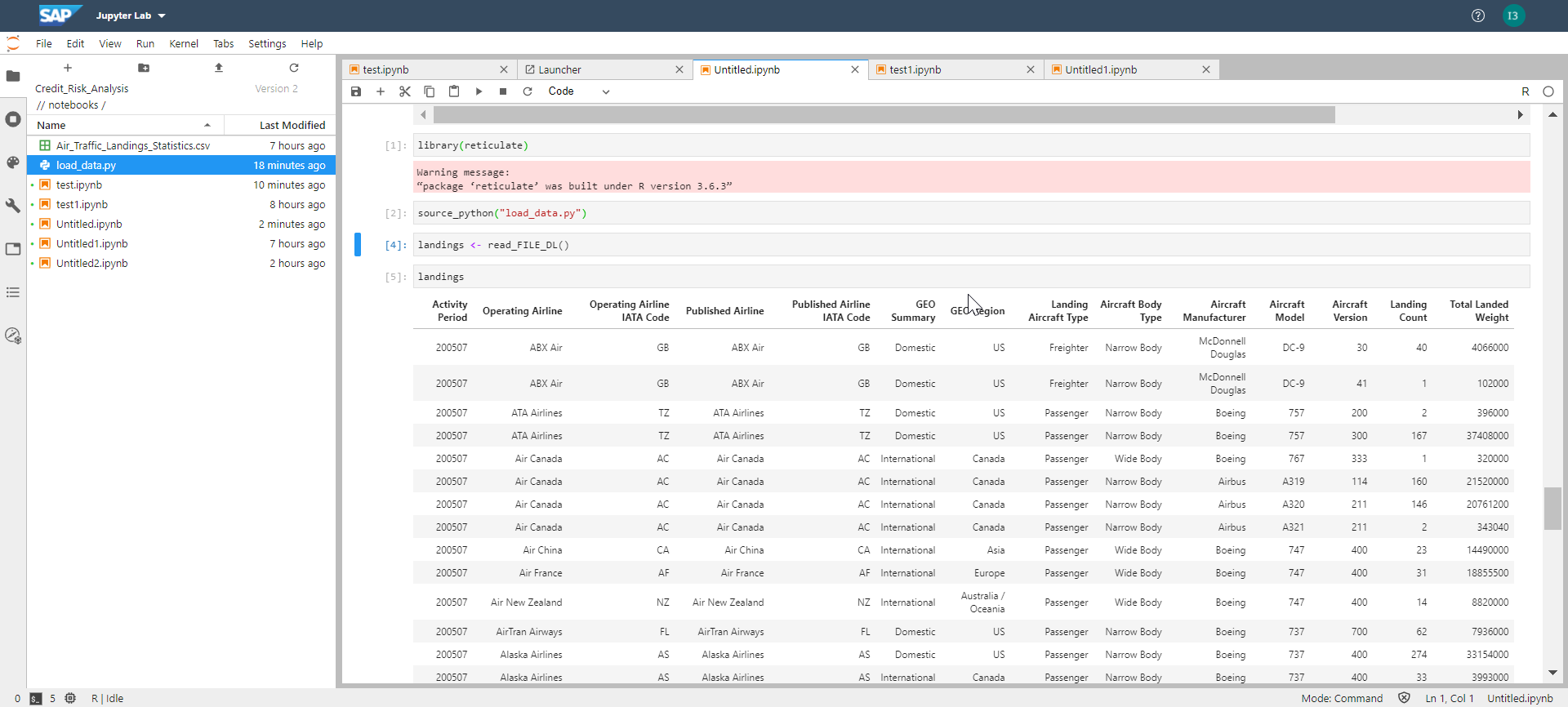
Using the "MARATHON" dataset example
Refer Ingo's Blog post and for Dataset use the blog post : SAP Data Intelligence: Create your first ML Scenario
df_train <- read.csv(file="RunningTimes.txt", header=TRUE, sep=";")
head(df_train)
ID HALFMARATHON_MINUTES MARATHON_MINUTES
1 73 149
2 74 154
3 78 158
4 73 165
5 74 172
6 84 173
str(df_train)
'data.frame': 117 obs. of 3 variables:
$ ID : int 1 2 3 4 5 6 7 8 9 10 ...
$ HALFMARATHON_MINUTES: int 73 74 78 73 74 84 85 86 89 88 ...
$ MARATHON_MINUTES : int 149 154 158 165 172 173 176 177 177 177 ...
lm.fit<-lm(MARATHON_MINUTES~HALFMARATHON_MINUTES,data=df_train)
str(lm.fit)
List of 12
$ coefficients : Named num [1:2] -6.01 2.25
..- attr(*, "names")= chr [1:2] "(Intercept)" "HALFMARATHON_MINUTES"
$ residuals : Named num [1:117] -9.18 -6.43 -11.43 6.82 11.57 ...
..- attr(*, "names")= chr [1:117] "1" "2" "3" "4" ...
$ effects : Named num [1:117] -2361.82 294.44 -9.94 8.49 13.21 ...
..- attr(*, "names")= chr [1:117] "(Intercept)" "HALFMARATHON_MINUTES" "" "" ...
$ rank : int 2
$ fitted.values: Named num [1:117] 158 160 169 158 160 ...
..- attr(*, "names")= chr [1:117] "1" "2" "3" "4" ...
$ assign : int [1:2] 0 1
$ qr :List of 5
..$ qr : num [1:117, 1:2] -10.8167 0.0925 0.0925 0.0925 0.0925 ...
.. ..- attr(*, "dimnames")=List of 2
.. .. ..$ : chr [1:117] "1" "2" "3" "4" ...
.. .. ..$ : chr [1:2] "(Intercept)" "HALFMARATHON_MINUTES"
.. ..- attr(*, "assign")= int [1:2] 0 1
..$ qraux: num [1:2] 1.09 1.18
..$ pivot: int [1:2] 1 2
..$ tol : num 1e-07
..$ rank : int 2.
///

SUMMARY
Its often a need in projects to quickly test R Code snippets before we can use them in Data Pipelines, so I hope that above workaround to have a working R kernel in Notebook within SAP Data Intelligence will be helpful.
I would also reiterate that the solution above serves as a workaround to test some of the R code snippets in notebook in SAP DI, and that the R SDK for SAP DI is not yet available ( unlike Python SDK for SAP DI) hence the artifacts stored in SAP DI data lake cannot be directly referenced using R kernel among other limitations( e.g. as is done using "sapdi" python library in SAP Data Intelligence)
Please follow the tag SAP Data Intelligence to get notified on latest updates, or visit the SAP Community page for SAP Data Intelligence to keep learning more: https://community.sap.com/topics/data-intelligence
- SAP Managed Tags:
- SAP Data Intelligence
Labels:
5 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,658 -
Business Trends
96 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
68 -
Expert
1 -
Expert Insights
177 -
Expert Insights
312 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
GraphQL
1 -
Kafka
1 -
Life at SAP
780 -
Life at SAP
13 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,576 -
Product Updates
356 -
Replication Flow
1 -
REST API
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,873 -
Technology Updates
444 -
Workload Fluctuations
1
Related Content
- New Machine Learning features in SAP HANA Cloud in Technology Blogs by SAP
- Augmenting SAP BTP Use Cases with AI Foundation: A Deep Dive into the Generative AI Hub in Technology Blogs by SAP
- ML Scenario Implementation (Logistics Regression Model) using SAP Data Intelligence in Technology Blogs by Members
- SAP IQ NLS-The Cold Storage Solution for SAP BW/4HANA in Technology Blogs by Members
- Consume Machine Learning API in SAPUI5, SAP Build, SAP ABAP Cloud and SAP Fiori IOS SDK in Technology Blogs by Members
Top kudoed authors
| User | Count |
|---|---|
| 18 | |
| 15 | |
| 11 | |
| 9 | |
| 9 | |
| 8 | |
| 8 | |
| 8 | |
| 7 | |
| 7 |