
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- SAP Data intelligence - Extracting data from an EC...
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Advisor
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
02-14-2023
2:53 PM
Hello everyone,
Again another request from one of my customer, actually from several of my customers. How can you extract data from an ECC system or an S/4HANA system into Google Big Query with delta load? As you’ll see, this is very simple and straightforward using SAP Data Intelligence, you can perform Intial load, delta loads or replication(Intial Load and Delta loads). For one customer, the target was actuallly Google Cloud Storage, in this case it is even easier and you can rely on the SAP Data Intelligence RMS feature and directly connect your source to the target with replication.
In any case, enough talking, look at the following video and I will demonstrate how you can quickly this set up. Of course, you will need acces to an ECC or S/4HANA system with SLT or the DMIS addon installed and a Google Cloud account for Google Big Query and Google Cloud Storage(needed for staging the data). Please note that I will not go in the details of the configuration of the SLT. I'd like to take the time to give credit to abdelmajid.bekhti, he was the one who showed me how to do this and provided me with all his systems and gave me access. I wouldn't be able to show you anything without his help and knowledge.
Ok, now let's get started! 🙂
First you need to configure your connections to your systems in SAP Data intelligence. We need to configure the SLT, ECC (or S4/HANA), Google Cloud Storage and Google Big query connections. For that click on the connections tab.

Let's start with the SLT connection.


As you can see here, we're using the SAP Cloud Connector to connect to our On Premise SLT system.
Then let's have a look at our connection to Google Big Query.

And we also need to create a connection to our Google Cloud Storage (SAP Data Intelligence will Google Cloud Storage as a staging table before delta loading into Google Big Query).
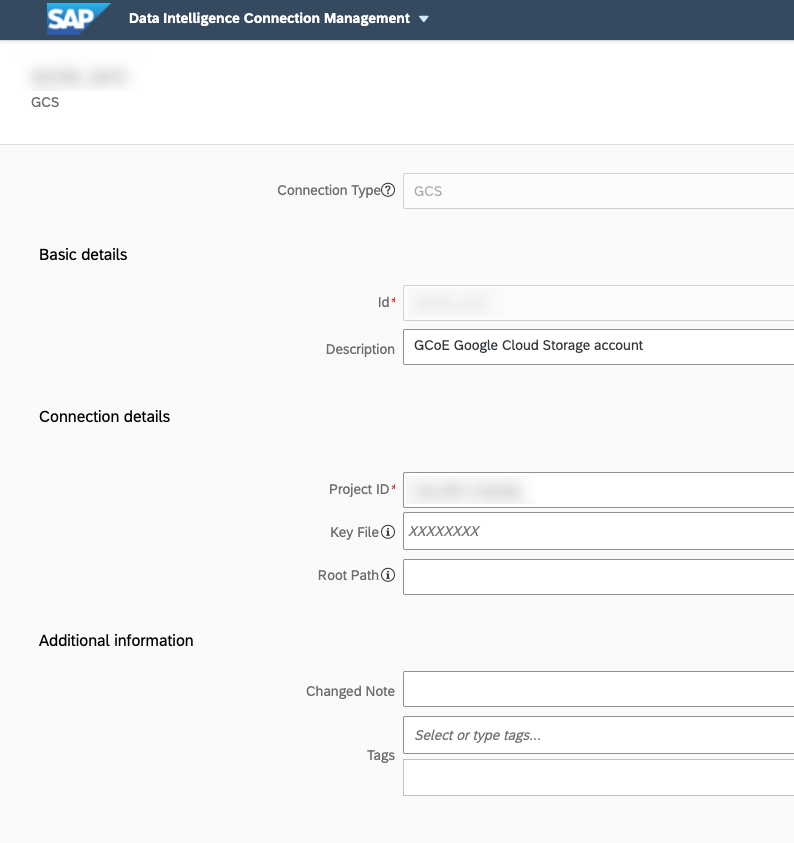
Once all these connections are correctly set up. We are going to have a look at the SLT configuration. We are going to connect to our SLT box and launch transaction LTRC (SAP LT Replication Server Cockpit).

As you can see we are replicating table MARA from our ECC system. And this is done in real time.

Once again, I will not through the details of setting up SLT. But everything is done correctly and we can proceed. As you saw, in this demo, we are going to replicate table MARA. The next step is to create a target table in Google Big query, for this you need to extract the data structure of the table you wish to replicate from your ERP system. You can refer to this blog to see how to extract this table structure. Downloading Data Dictionary Structure into local file
In my case, I used DD03VT in SE11 to extract table MARA. I didn't make exactly the same data structure with the exact types, and just used strings and had to modify some of the names as I could not create fields with '/' in their names in Google Big Query tables.
Now let's look at the pipeline. As you will see, it is incredibly simple... We are using Generation 2 operators, with Generation 1, the data pipeline would be more complex. Just to explain, SAP Data Intelligence Generation 2 operators are based on Python 3.9 whereas Generation 1 operators using Python 3.6.
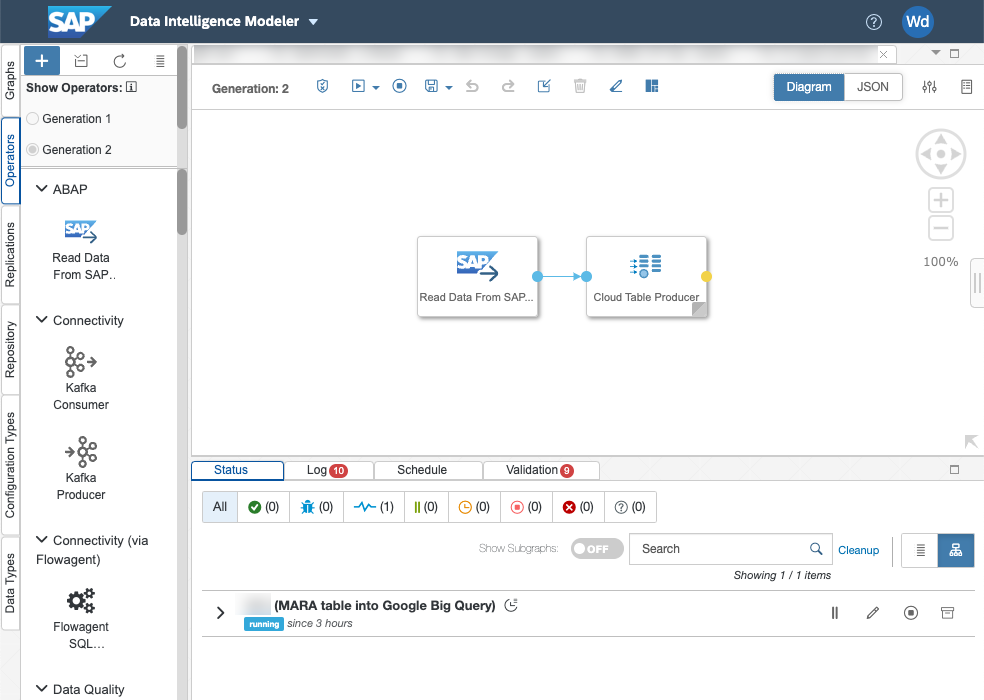
We are using the "Read Data from SAP System" operator to connect to SLT and the Cloud Table Producer operator to connect to Google Big Query (this operator can connect to Google Big Query or Snowflake).
Let's look at the configuration of our Read Data from SAP System operator.

Choose the correct connection, in our case the SLT connection shown earlier. And then click on object Name to select the Mass Transfer ID and table you want to replicate.

Then you need to choose the replication mode, either Initial Load, Delta Load or Replication (both initial and delta loads)
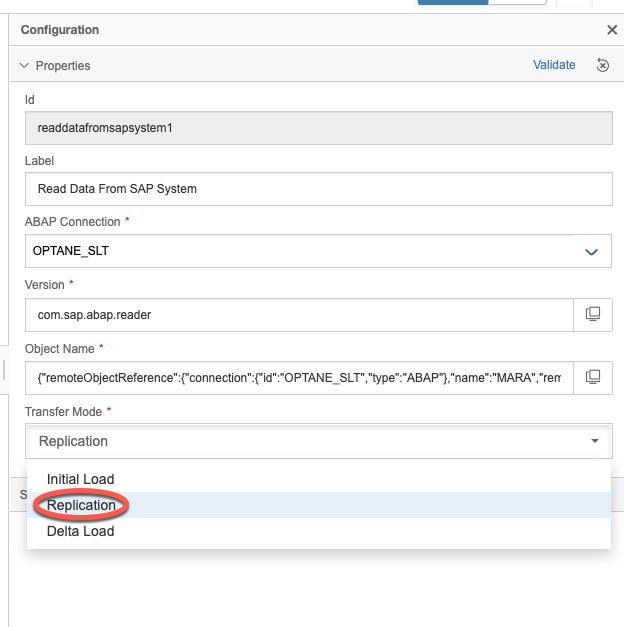
In our case, we chose Replication. Now to the Cloud table Producer Operator. Click on the configuration.

Click on the Target.

Now we need to configure all the information here. For the service, this is a Google Big Query (other option is snowflake). For the connection ID, choose your Google Big Query Connection, for the target the table that you created in your Google Big Query System.
For the staging connection ID, choose your Google Cloud Storage connection. For the staging Path, simply choose where the staging table will be created.
In the target columns, you can perform an autocompletion of the mapping by clicking on the button indicated below. For fields that have different names, you have to do the mapping by hand.

Now we need to save and start our data pipeline. Click on "Run as"

Give a name to your graph, click on Capture snapshot in order to have snapshot every x second in case of a problem. You can then choose to have an automatic recovery or manual recovery. Click on OK and launch the graph.
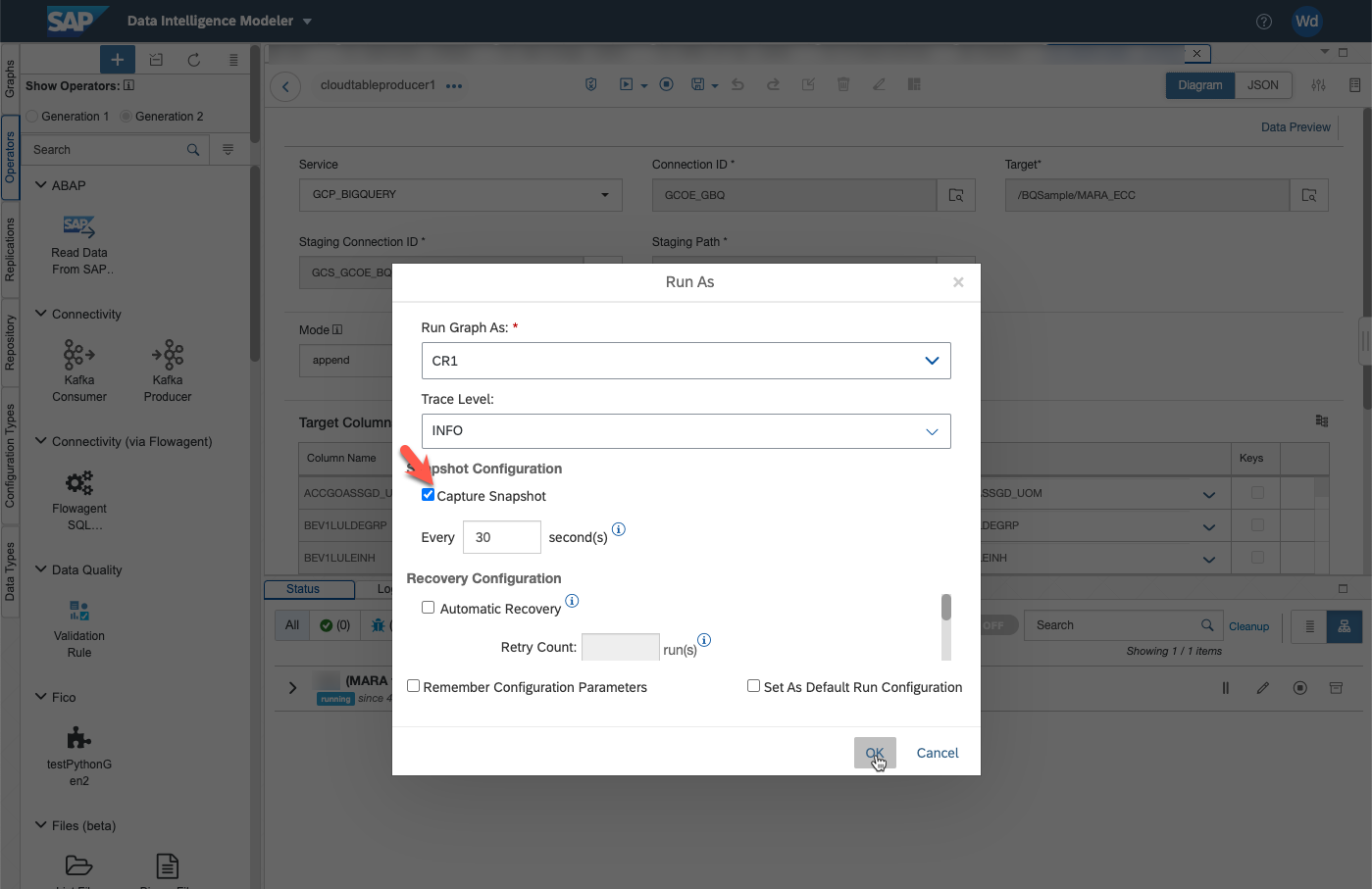
Your pipeline should be up and running in a minute or so.
Now let's go to our ECC system and launch transaction MM02 to change our material numbers. I'll change material number 1177.
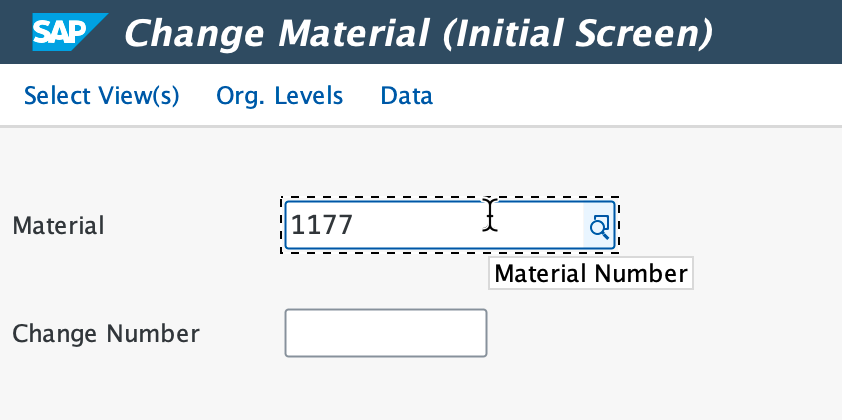
Select both Basic Data 1 & 2 and continue.
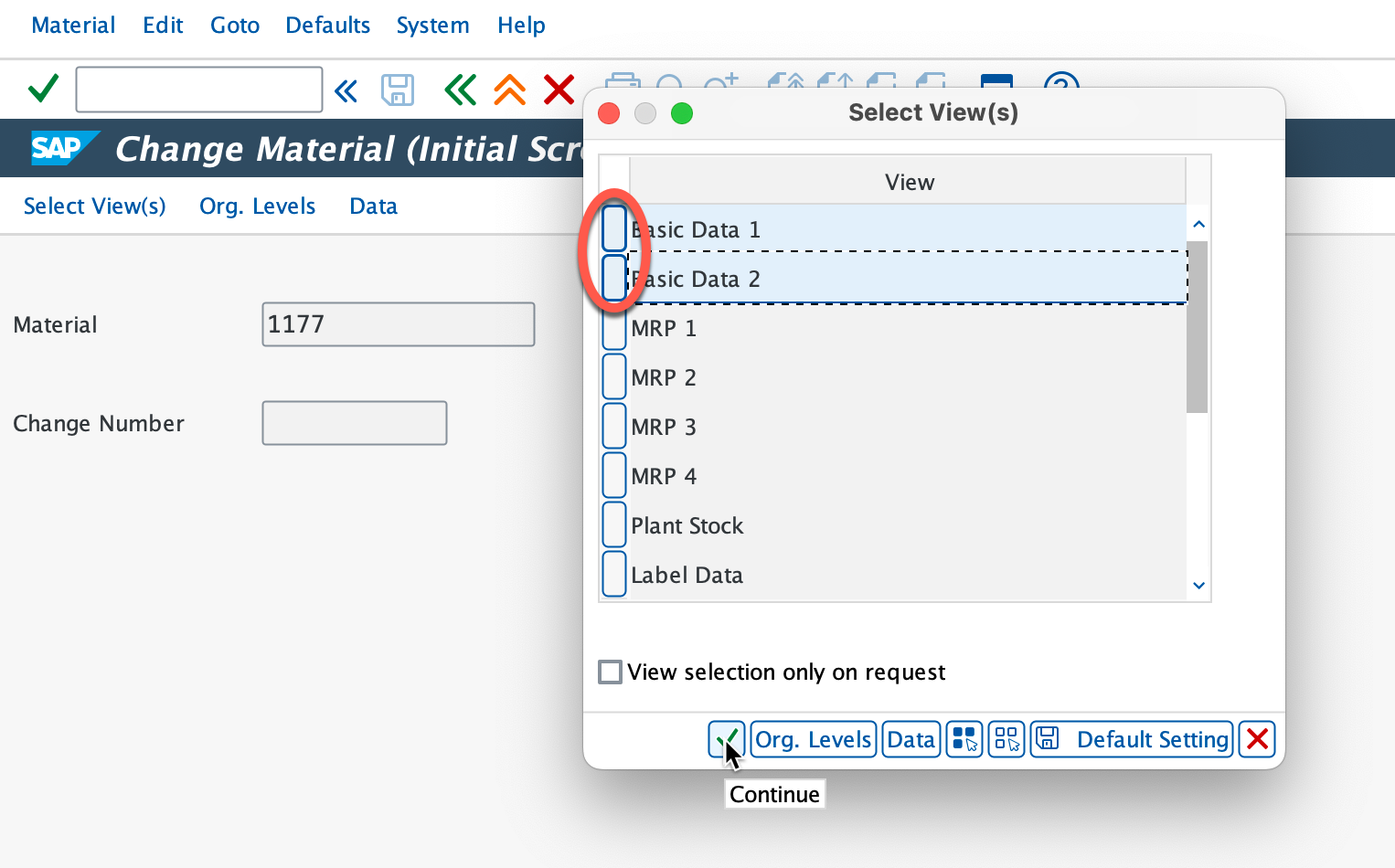
Now we're going to modify the old material number.

I'll change it to 1216. Let's save and head to the Google Big Query.
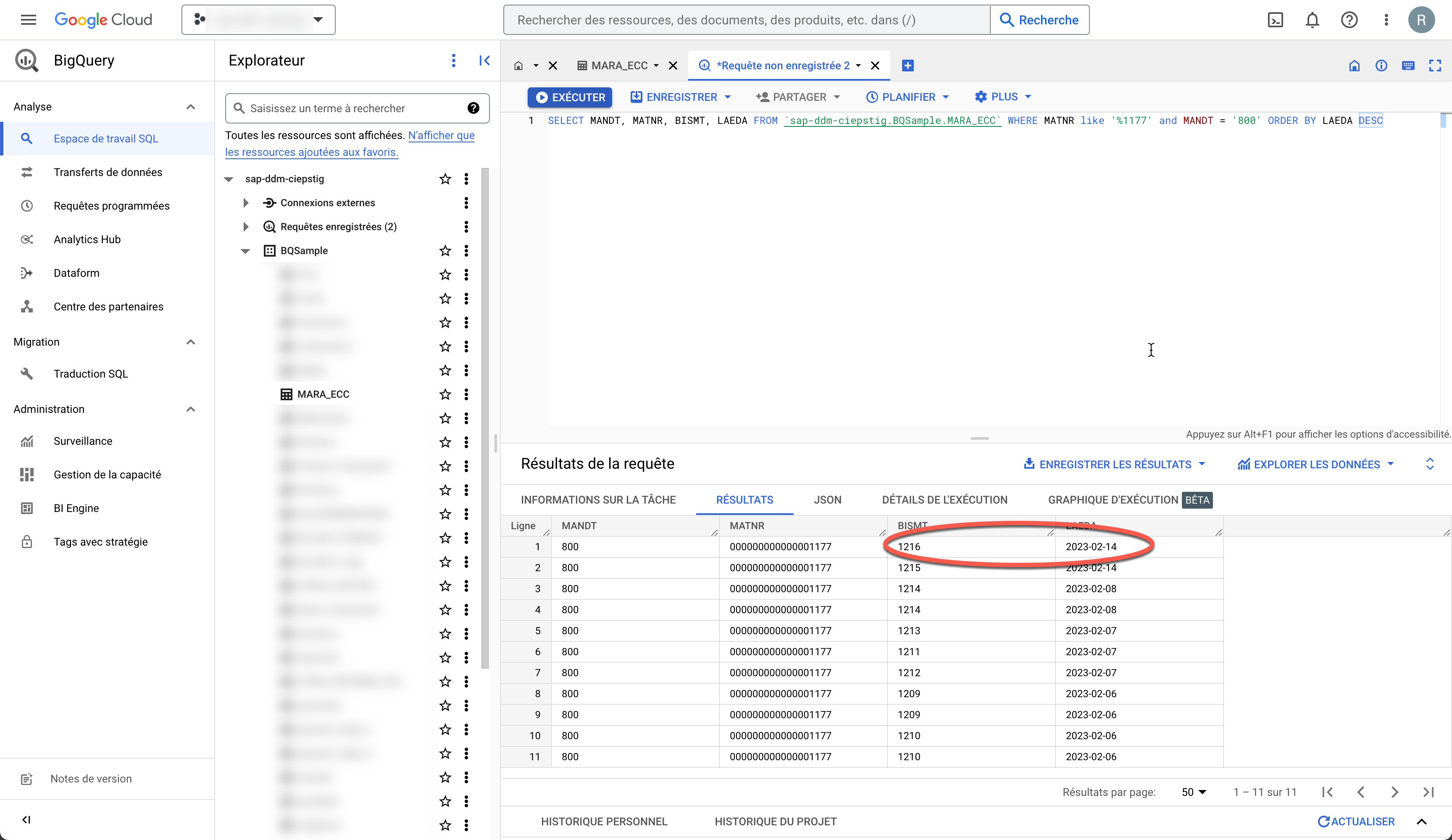
The Old material Number was modified and pushed to Google Big Query.
As you can see, this was very easy to set up. Once again, I have done this with a ECC system but this could also be done with an S4/HANA system just as easily. Again, thank you abdelmajid.bekhti for your systems and your help in configuring this.
I hope this blog was useful to you. Don’t hesitate to drop a message if you have a question.
Labels:
11 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,658 -
Business Trends
102 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
69 -
Expert
1 -
Expert Insights
177 -
Expert Insights
320 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
GraphQL
1 -
Kafka
1 -
Life at SAP
780 -
Life at SAP
13 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,576 -
Product Updates
367 -
Replication Flow
1 -
REST API
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,873 -
Technology Updates
453 -
Workload Fluctuations
1
Related Content
- SAP Datasphere + SAP S/4HANA: Your Guide to Seamless Data Integration in Technology Blogs by SAP
- Vectorize your data for Infuse AI in to Business using Hana Vector and Generative AI in Technology Blogs by Members
- Up Net Working Capital, Up Inventory and Down Efficiency. What to do? in Technology Blogs by SAP
- New Machine Learning features in SAP HANA Cloud in Technology Blogs by SAP
- Harnessing the Power of SAP HANA Cloud Vector Engine for Context-Aware LLM Architecture in Technology Blogs by SAP
Top kudoed authors
| User | Count |
|---|---|
| 21 | |
| 11 | |
| 8 | |
| 8 | |
| 7 | |
| 7 | |
| 6 | |
| 6 | |
| 6 | |
| 6 |