
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- Smart Document Extraction using SAP Intelligent RP...
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
former_member65
Explorer
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
10-01-2021
7:00 AM
Introduction
One of the most important aspect of automating the business processes is to extract data reliably from documents such as Invoices, Purchase Orders, Payment Advices or other custom documents. In a traditional workflow, information trapped in such documents has to be read and understood manually in a tedious manner affecting time and cost for any organization.
One of such example is shown below where John who manages the accounts has to manually go through the hustle of downloading, reading and storing the invoice data into system.
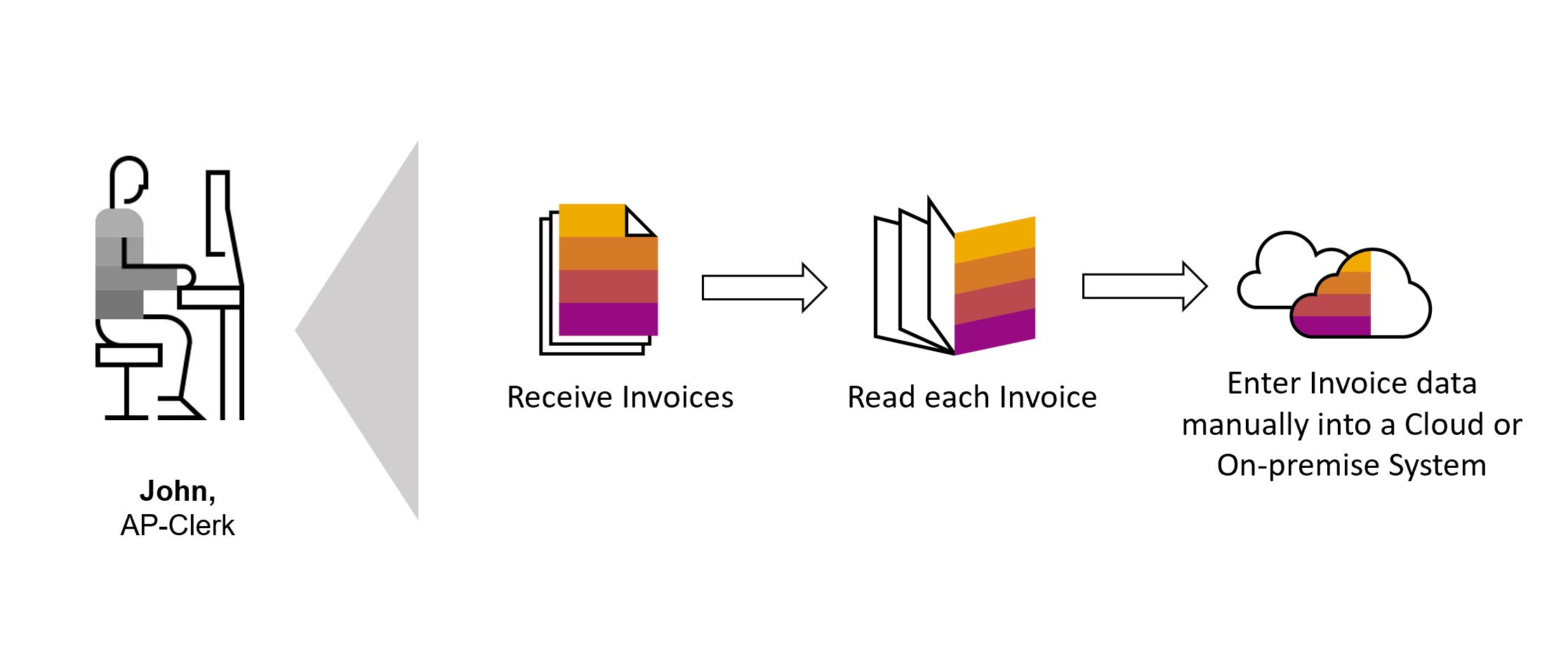
With the integration of SAP Intelligent RPA with Document Information Extraction service, John can now relax and perform the tedious and hectic tasks by click of a button as shown in the picture below.

Document Information extraction service from SAP is part of SAP AI Business Services portfolio offering. Being a pre-trained service, it leverages deep-learning algorithms to extract structured semantical information from unstructured documents, at the same time, specialized models are available for the most common document types to provide even better extraction results and additional capabilities.
What makes it smart and easy ?
SAP Intelligent RPA allows you to extract data from scanned documents, images in a user-friendly and Low Code-No Code manner with the help of dedicated activities.
John has some questions regarding the data extraction from documents. Let's have a look to those questions:
Q1. I have multiple invoices in multiple languages or structure and generic fields such as Invoice Number, Purchase Order Number, Date, amount and so on.. which needs to be extracted. Can you extract these fields with just specifying the Document Type and Document path ?
The answer is YES. We have an activity which can be used by just doing a drag and drop from the activities list.

Extract data without template activity will provide an output with all the generic data which is extracted using the global ML model of Document Information Extraction service. The output data can be used as shown in the image below where all the generic fields are listed. Value as well as the confidence score obtained from the ML approach is also available to create a logic around it.

Q2. I am able to extract the fields using the above approach, but the Receiver Name of the invoice is not extracted. Is there a way that I can annotate just one field and others get extracted automatically?
The answer is YES. We have a convenient way of declaring fields which cannot be extracted by the global model and needs user annotations to recognize for the further documents. This can be done by first declaring a Document Template which is shown below:

Provide the sample document along with few other parameters to start the annotations. After pressing the create button, it will jump to an annotations UI as shown below where you can annotate the fields which you think cannot be extracted automatically.

In the above example, only one field is annotated and other fields fields will be extracted automatically using the Global ML approach. Once the annotations are done, this template can be used in the automations by doing a drag and drop of another convenient activity as shown below:

Select the document template from the list of available template and provide document path to extract the data.
Q3. I have some random documents other than Invoice, Purchase Order or Payment Advice and would like to extract the text. Do you support text extraction is such case and provide activities to fetch the information from such documents?
The answer is YES. We have a dedicated activity which is an alternative to the existing activity called "Open PDF". Previously the text operations can only be performed on machine readable PDF's but with the help of new activity called "Open Document (Online OCR)", any scanned document, images are also supported. These activities can be seen under the PDF SDK module.
License
Document Information Extraction feature in SAP Intelligent RPA is available for all the customers without additional costs or license.
This feature is already available as part of 2109 release.
What's next?
With the help of Document Information Extraction, SAP Intelligent RPA will provide a set of convenient activities to enrich the information extracted from documents with your own master data records.
Thanks for reading and feel free to leave a comment with questions or feedback 🙂
More Detailed Blog Posts
Text Operations to Ease Data Extraction - Using Online OCR
Automatic business documents extraction – Using Pre-Trained AI Model
Custom documents extraction - Using Templates
Master Data Matching – Data Enrichment Activities
Labels:
5 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,658 -
Business Trends
116 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
75 -
Expert
1 -
Expert Insights
177 -
Expert Insights
357 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
GraphQL
1 -
Kafka
1 -
Life at SAP
780 -
Life at SAP
14 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,575 -
Product Updates
398 -
Replication Flow
1 -
REST API
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,871 -
Technology Updates
493 -
Workload Fluctuations
1
Related Content
- Expert Systems in AI: Bridging Human Expertise and Machine Intelligence in Technology Blogs by SAP
- 10+ ways to reshape your SAP landscape with SAP BTP - Blog 7 Interview in Technology Blogs by SAP
- Datasphere – Delta Extraction in Technology Blogs by Members
- 10+ ways to reshape your SAP landscape with SAP Business Technology Platform – Blog 7 in Technology Blogs by SAP
- Explore the SAP HANA Cloud vector engine with a free learning experience in Technology Blogs by SAP
Top kudoed authors
| User | Count |
|---|---|
| 20 | |
| 11 | |
| 8 | |
| 8 | |
| 7 | |
| 7 | |
| 7 | |
| 6 | |
| 6 | |
| 6 |