
- SAP Community
- Groups
- Interest Groups
- Application Development
- Blog Posts
- ABAP to the future – my version of the BOPF chapte...
Application Development Blog Posts
Learn and share on deeper, cross technology development topics such as integration and connectivity, automation, cloud extensibility, developing at scale, and security.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
former_member18
Active Participant
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
07-27-2015
8:59 AM
8.2.5 Determinations
Up to now, we’ve been interacting with a Business Object solely as a consumer. It’s now time to move to the other side and provide some business logic.
We already know associations and nodes as the entities of the static behavior. Expressed in UML, Nodes are classifiers (such as classes in ABAP OO) and as such, they are also the anchor for behavior: While object oriented languages differentiate behavior based on their visibility (private, protected, public methods), BOPF also differentiates semantically (determinations, actions, validations). What this all is and how this relates to known concepts, we’ll look at in a practical example starting with determinations.
Determinations are implicitly executed data manipulation which the framework triggers on a modeled interaction with a business object. They can’t be explicitly invoked by a consumer and thus are comparable to non-public methods in a UML class model which are executed as some kind of side-effect. This side-effect should somehow be relevant to business logic (and not solely be derived in order to be presented on a UI). Whether the result is persisted or only transiently available until the end of the transaction does not matter to how the business logic is implemented.
The most important and sometime tricky decision you need to make is to which node the determination shall be assigned to. The answer is simple remembering that a BO node corresponds to a UML class: At the node which represents the entity at which you would implement the private method in a domain model. Well, this might not have helped you much if you’ve been more focused on coding instead of modeling yet, but I hope the next hint should help you more: At runtime, the instances of the assigned node are passed into the determination. So usually it makes sense to assign the determination at the node where the attributes reside which are going to be manipulated by the determination. Or more general: Choose the assigned node as the topmost node from which all information required within the determination is reachable. A sample further down should explain this aspect easily.

Figure 32 – Creating a determination. Note the link to the System-Help!
Three aspects are relevant to determinations:
- Which interaction makes the system trigger
- What business logic and
- When this logic is being executed.
While the “what” is being coded in ABAP as a class implementing a determination interface, trigger and execution time can be modeled.
Triggers can be any of the CRUD-services which are requested at a BO node. A trigger for a determination can also be a CRUD-operation on a node which is associated to the assigned node (e. g. a subnode).
In order to understand the options for the execution time it is essential to understand the phase-model of a BOPF-transaction and this would be a chapter on its own. Anyway, only set of combinations of triggers and execution times makes sense and SAP has thus enhanced the determination creation wizard (compared to the previous releases and the full-blown BOBF modeling environment): The wizard in the BO builder (transaction BOB) offers a selection of usecases for a determination. In the BOBX trigger and determination time can be modeled explicitly. We’ll focus on the patterns offered in BOPF as they provide the meaningful combinations of trigger and execution time.
Derive dependent data immediately after modification
Trigger: Create, update, delete of a node; execution time: “after modify”. Immediately after the interaction (during the roundtrip), the determination shall run. This is by far the most often required behavior. Even if no consumer might currently request this attribute (e. g. as it’s not shown on the UI), most calculated attributes shall be derived immediately, as other transactional behavior might depend on the calculation’s result.
The following screenshots illustrate the chosen triggers and time points for this type of determinations.

Figure 33 - The most common usecase: A determination derives persistent data after modification
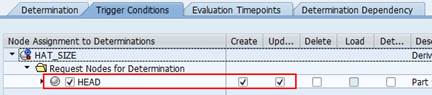
Figure 34 - Trigger usually is the create and update of the node. Delete is usually not necessary, as on delete, there would be no basis for the derivation anymore.

Figure 35 - The derivaiton shall be performed immediately after modifying the request-nodes (triggers)
Derive dependent data before saving
Trigger: Create, update, delete of a node; execution time: “before save (finalize)”. Each modification updates the current image of the data. However not all of these changes which might represent an intermediate state need to trigger a determination, but only the (consistent) state before saving is relevant to the business. Popular samples are the derivation of the last user who changed the instance, the expensive creation of a build (e. g. resolving a piece-list) or the interaction with a remote system.
The configuration is the same as the same as the previous one except that it’s triggered “before save (finalize)” instead of “after modify”.
Fill transient attributes of persistent nodes
Trigger: Load, create, update of a node; execution times: “after loading” and “after modify”. Transient attributes need to be updated once the basis for the calculation changes as well as when reading the instance for the first time.
Assuming that the head-count of the monster was not persisted but would be always derived on the fly, the determination configuration would look like this:

Figure 36 – By modelling the determination as transient, BOPF will not lock the node instance.

Figure 37 - As the implementation is based on the existence of the subnode "head", the trigger needs to be the create and delete of the subnode. In addition to that, loading the root-node needs to trigger the determination for the first time.

Figure 38 - Transient determinations need to be triggered on the first loading and usually after something has changed again
Please note: Transient data in a BO node should be relevant to a business process. Texts are not. Deriving texts (such as it’s done in A2ttF) should not be part of the model. However, you could of course derive a classification (A/B/C-Monsters) based on some funky statistical function of the current monster-base or from a ruleset. The texts (“A” := “very scary monster”) should be added on the UI layer. Other samples for transient determinations which I have seen in real life: Totals, Count of subnodes, converted currencies, age (derived from a key-date, temporal information is tricky to persist, serialized form of other node-attribute.
In (almost) every case, you could as well persist the attribute instead of calculating it on request. In many cases, a node attribute which was transient in the first step got persisted after some time (due to performance or since some user wanted to search for it). In this case, you simply need to change the configuration of the determination to “Derive dependent data immediately after modification”, but not change the implementation!
Create properties
Trigger: The core-service “retrieve_properties” on the assigned node; execution time “before retrieve”. Properties are bits (literally) of information which inform the consumer which interactions with parts of the instance are possible (see next chapter 8.2.6) – if the consumer wants to know that! One usecase of properties is to mark node attributes as disabled, read-only or mandatory. But also actions can carry properties about being enabled or not.

Figure 39 - Property-determinations are always transient

Figure 40 - The trigger is always the (retrieve) on the technical _PROPERTY-subnode
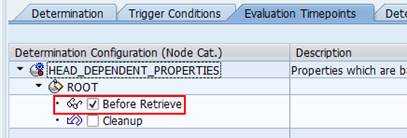
Figure 41 - Before retrieving this node, the determination calculates the node instances
Derive instance of transient node
Trigger: The resolution of an association to the assigned node. Execution time: “before retrieve”. In BOPF it is also possible to create nodes which are fully transient – including their KEY. If a node is modeled as transient, this determination pattern is getting selectable. The implementation has to ensure that the KEY for the same instance is stable within the session. As this is a quite rare-usecase, I’ll not go into the details about it (we might have a sample in the actions chapter later on).
Determination dependencies are the only way to control in which order determinations are being executed in. If one determination depends on the result of a second one, the second determination is a predecessor of the first one. If you need lots of determination dependencies, this is an indicator for a flaw in either the determination- or the BO-design: This brings us to another question: What shall be the scope of a determination? There might be different responses to this question. I prefer to have one determination per isolated business aspect. If you for example derive a hat-size-code and a scariness-classification, they are semantically not interfering. Thus, I advise to create two determinations in this case, even if both are assigned to the same node, have got the same triggers and the same timepoint (after modify). You could argue that then, two times the same data (monster header) is being retrieved (in each of the determinations), but the second data retrieval will hit the buffer and thus has very limited impact on performance. The benefits are – imho – much bigger: Your model will be easier to read and to maintain (many small chunks which can also be unit-tested more easily). Also, it might be the case that throughout the lifecycle of your product, one aspect of the business logic changes and makes new triggers necessary (e. g. the scariness could be influenced by the existence of a head with multiple mouths in future). If you don’t separate the logic, your additional trigger would also make the business logic execute which is actually independent of it. I our sample, the determination of the scariness would have to be executed on CUD of a HEAD-instance while the hat-size-code still depends on changes of the ROOT.
Alright, with all this being said/written, let’s have a look at how to actually implement a determination. As we are getting close to the code, I will have to comment on the samples and advice given in the book. One major benefit using BOPF is that these styles are getting more and more alike since there are some patterns / commands which just make sense while others don’t :wink:
Excursus: Dependency inversion and the place for everything
In A2tF, the determination chapter also includes an architectural advice about providing a technology independent implementation of business logic. I don’t agree with the advice given there and wanted to explain why I believe that the BOPF-pattern to delegate to classes implementing a dedicated interface actually fulfills the requirements of loose coupling better than utilizing a “model class”.
First of all, I would like to address an aspect which Paul also pointed out (and which consists of two parts. “This example is a testimony to the phrase ‘A place for everything and everything in its place.’ Instead of lumping everything in one class, it’s better to have multiple independent units”. I could not more agree to that – and I could not contradict more to his conclusion drawn: “For that reason, this example keeps the determination logic in the model class itself and that logic gets called by the determination class”. With a BOPF model in place, this model is becoming “the place for everything”.
Even if the (BOPF BO) model is not represented by one big class-artifact or an instantiated domain-class at runtime, this model exists. I don’t think that when you model your business in BOPF, you are getting stuck on the current stack: The BOPF designtime is the tool with which this model is technically described, but the model exists also without BOPF. In natural language, I can easily describe aspects of my model as well: “As soon as the hat-size of my monster changes, I want to calculate the hat-size-code”. Having a determination after modify with trigger CUD on the ROOT of monster is only a structurally documented form. As thereis also an interface for reading this model, you can even think of compiling some other languages’ code based on the model.
Whatever technical representation you are choosing for your model (BOPF BO-model, GENIL-component-representation or a plain ABAP domain class), it’s good style not to implement all behavior only in one single artifact (e. g. in methods of a class). Let’s stick to the sample of the two derivations given. In a plain ABAP-class, you could have methods defined similar to this:
METHOD derive_after_root_modification.
me->derive_hat_size( ).
me->classify_scariness( ).
ENDMETHOD. “derive_after_root_modification.
This is the straight-forward-approach, but ill will become clumsy as your models grow. Also, re-use is limited with respect to applying OO-patterns and techniques on the behavioral methods (e. g. using inheritance in order to reduce redundancy). Thus, I like the composite-pattern with which we’ll create small classes implementing the same interface:
INTERFACE zif_monster_derivation.
METHODS derive_dependent_stuff
IMPORTING
io_monster TYPE zcl_monster.
ENDINTERFACE.
METHOD derive_after_root_modification.
DATA lt_derivation TYPE STANDARD TABLE OF REF TO zif_monster_derivation WITH DEFAULT KEY.
INSERT NEW zcl_monster_hat_size_derivation INTO TABLE lt_derivation.
INSERT NEW zcl_monster_scariness_derivation INTO TABLE lt_derivation.
LOOP AT lt_derivation INTO DATA( lo_derivation ).
lo_derivation->derive_dependent_stuff(me).
ENDLOOP.
ENDMETHOD. “derive_after_root_modification.
Having applied this pattern, you are much more flexible when adding new business logic (or when deciding to execute the same logic at multiple points in time, for example). And you are much closer to the implementation pattern chosen in BOPF. The only difference being that you don’t need the model class (as I wrote previously). The instantiation of the framework for your BO at runtime will do exactly the same job.
So what about dependency inversion and the flexibility of your code if BOPF is not state-of-the-art anymore? It’s all in place already. Let’s have a look at the following sample implementation of the hat-size-derivation:
CLASS zcl_monster_hat_size_derivation DEFINTION.
INTERFACES /BOBF/IF_FRW_DETERMINATION.
PROTECTED SECTION.
METHODS get_hat_size_code
IMPORTING iv_hat_size TYPE zmonster_hat_size
RETURNING VALUE(rv_hat_size_code) TYPE zmonster_hat_size_code.
ENDCLASS.
METHOD get_hat_size_code.
* We classify the hat size. The hat size code is getting translated to its code-values by the UI-layer
* (If for example you use a drop-down-list-box in the FPM, the UI
* will automatically translate the code to its text if the domain is
* properly maintained with either fixed values or a value- and text-table).
IF iv_hat_size > 100.
rv_hat_size_code = zif_monster_constants=>head-hat_size_code-very_big_hat.
ELSEIF iv_hat_size > 50.
rv_hat_size_code = zif_monster_constants=>head-hat_size_code-big_hat.
ELSEIF iv_hat_size < 10.
rv_hat_size_code = zif_monster_constants=>head-hat_size_code-small_hat.
ELSE.
rv_hat_size_code = zif_monster_constants=>head-hat_size_code-normal_hat.
ENDIF.
ENDMETHOD.
Let’s see how this technology-independent business logic is getting integrated into the BOPF interface methods.
METHOD /BOBF/IF_FRW_DETERMINATION~EXECUTE.
DATA lt_head TYPE ZMONSTER_T_HEAD.
io_read->retrieve(
exporting
iv_node = zif_monster_c=>sc_node-head
it_key = it_key
it_requested_attributes = value #( ( zif_monster_c=>sc_node_attribute-head-hat_size ) )
importing
et_data = lt_head ).
LOOP AT lt_head REFERENCE INTO DATA(lr_head).
* Here comes the actual business logic
lr_head->hat_size_code = me->get_hat_size_code( lr_head->hat_size ).
io_modify->update(
iv_node = zif_monster_c=>sc_node-head
iv_key = lr_head->key
is_data = lr_head
it_changed_attributes = value #( ( zif_monster_c=>sc_node_attribute-head-hat_size_code ) ) ).
ENDLOOP.
ENDMETHOD.
Note that the signature of the actual business logic (get_hat_size) is absolutely independent of BOPF. The determination class simply offers an interface (literally) to the framework. If you switched to another framework, you could implement asecond interface in which method implementation you also call the “business logic”.
I sincerely hope I could address the concerns I’ve got about using a model class and that you also come to the conclusion, that with many atomic classes in place and the BOPF model described in the system, there is no need for a model-class. Why I’m so opposite to such an entity is a major flaw in the way this is usually being used and which brings a terrifying performance penalty. We’ll come to that in the next paragraphs.
The determination interface methods
Paul has explained the purposes of the interface methods nicely in A2tF. You can also have a look at the interface-documentation in your system.
Above I wrote that with BOPF in place, the implementations are getting harmonized within a development team. I would therefore like to explain the basic skeletons and DOs and DON’Ts within the implementation of those methods.
Checking for relevant changes
METHOD /bobf/if_frw_determination~check_delta.
* First, compare the previous and the current (image-to-be) of the instances which have changed.
* Note that this is a comparatively expensive operation.
io_read->compare(
EXPORTING
iv_node_key = zif_monster_c=>sc_node-head
it_key = ct_key
iv_fill_attributes = abap_true
IMPORTING eo_change = DATA(lo_change) ).
* IF lo_change->has_changes = abap_true. ... This is unnecessary, as we'll get only instances passed in ct_key which have changed.
* io_read->retrieve( ... ) ... this is usually not necessary in check_delta, as we're only looking for the change, not for the current values (this, we'll do in "check")
lo_change->get_changes( IMPORTING et_change = DATA(lt_change) ).
LOOP AT ct_key INTO DATA(ls_key).
* Usually the last step in check and check-delta: Have a look at all the instances which changed
* and sort those out which don't have at least one attribute changed upon which our business logic depends on.
* Note, that determinations are mass-enabled. If you see INDEX 1 somewhere in the code, this is most probably
* a severe error or at least performance penalty!
READ TABLE lt_change ASSIGNING FIELD-SYMBOL(<ls_instance_changes>)
WITH KEY key1 COMPONENTS
node_key = zif_monster_c=>sc_node-head
key = ls_key-key.
CHECK <ls_instance_changes>-change_mode = /bobf/if_frw_c=>sc_modify_update.
"Also creates might trigger the determination! But this is not relevant for check_delta
* CHECK sy-subrc = 0. "This is not necessary as the instance got passed to the determination
"as it has changed (assuming that the trigger was the assigned node of course).
"If you want to program so defensively that you don't trust the framework fulfilling
"its own contract, use ASSERT sy-subrc = 0.
READ TABLE <ls_instance_changes>-attributes TRANSPORTING NO FIELDS WITH KEY table_line = zif_monster_c=>sc_node_attribute-head-hat_size.
IF sy-subrc = 0.
* A relevant attribute changed => don't exclude the instance from being processed
CONTINUE.
ENDIF.
DELETE ct_key.
ENDLOOP.
ENDMETHOD.
Checking for relevant values
METHOD /bobf/if_frw_determination~check.
* Get the current state (precisely the target state to which the modification will lead) of all the instances which have changed.
DATA lt_head TYPE zmonster_t_head. "The combined table type of the node to be retrieved
io_read->retrieve(
EXPORTING
iv_node = zif_monster_c=>sc_node-head
it_key = ct_key
it_requested_attributes = VALUE #( ( zif_monster_c=>sc_node_attribute-head-wears_a_hat ) )
IMPORTING
et_data = lt_head ).
LOOP AT lt_head ASSIGNING FIELD-SYMBOL(<ls_head>) WHERE
hat_size IS INITIAL. "check the content of some attribute of the node which makes the derivation logic unnecessary.
* You could also very well loop at ct_key, in order to make sure you process every instance.
* This makes sense if you don't retrieve all the instances in the first step.
DELETE ct_key WHERE key = <ls_head>-key. "exclude the instance from further processing
ENDLOOP.
ENDMETHOD.
Executing the actual calculation
METHOD /bobf/if_frw_determination~execute.
DATA lt_head TYPE zmonster_t_head.
io_read->retrieve(
EXPORTING
iv_node = zif_monster_c=>sc_node-head
it_key = it_key
it_requested_attributes = VALUE #( ( zif_monster_c=>sc_node_attribute-head-hat_size ) )
IMPORTING
et_data = lt_head ).
LOOP AT lt_head REFERENCE INTO DATA(lr_head).
* The actual business logic resides in a stateless method which is not
* bound to be used only in the BOPF context
lr_head->hat_size_code = me->get_hat_size_code( lr_head->hat_size ).
io_modify->update(
iv_node = zif_monster_c=>sc_node-head
iv_key = lr_head->key
is_data = lr_head
it_changed_fields = VALUE #( ( zif_monster_c=>sc_node_attribute-head-hat_size_code ) ) ).
ENDLOOP.
ENDMETHOD.
So far, so good. I hope you agree that the command pattern has the benefit of being very verbose in combination with the constant interface. Coding for example
io_modify->update(
iv_node = zif_monster_c=>sc_node-head
iv_key = lr_head->key
is_data = lr_head
it_changed_fields = VALUE #( ( zif_monster_c=>sc_node_attribute-head-hat_size_code ) ) ).
is in my eyes very close to writing a comment “Update the hat-size-code of the monster’s head”.
Architectural aspects
Some final words on why I don’t like to delegate further from a determination class to a model-class. What is so “wrong” about lo_monster_model = zcl_monster_model=>get_instance( ls_monster_header-monster_number)?
There are some things which may happen delegating to an instance of a model-class which absolutely contradict the BOPF architectural paradigms which all arise due to the conflict of a service-layer-pattern used in BOPF (you talk to a service providing the instances you are operating with) versus a domain-model-pattern common in Java and alike (each instance of the class represents an instance of a real-world-object):
- Own state
In BOPF, the state is kept in the buffer class of each BO node. This buffer is accessed by the framework. Based on the notifications of this buffer, the transactional changes are calculated and propagated to the consumer. This is not possible if other non-BOPF-buffers exist. But actually, this is the paradigm of a domain-model: Each instance shall hold the state of the real-world-representation. So what to do? Whenever you implement business logic in BOPF, the actual logic needs to be implemented stateless. There must not be any member accessed, neither at a third-party-model-class nor at the determination class itself! - Reduction of database access
Considering the latency of the various memories, DB access is one thing which really kills performance. Thus, BOPF tries to reduce the number of DB interaction: A transparent buffer based on internal tables exists for each node and all interfaces are mass-enabled which allows having a SELECT INTO TABLE instead of a SELECT SINGLE. When using a domain model pattern, the factory needs to provide a mass-enabled method in order to achieve the same (which I have rarely seen). Also, as BOPF has already read the data from the DB, the factory should also allow to instantiate with data (and not only with a key). The code samples in the book also imply, that within the get_instance( monster_number ), a query is being used in order to translate the semantical into the technical key. As the query always disregards the transactional buffer, not only an unnecessary data access is being made: the instance could not be created for a monster which has just been created. - Lazy loading
Usually, if you create a BOPF model, each BO node has its own database table with the technical KEY being the primary key of the database. If this is the case, each node can (and shall) be separately loadable. This means that all subnodes of a node are only being read from the DB if the node is explicitly requested (either by a direct retrieve or most likely with a retrieve by association from the parent node). Using a domain model, you also have to implement this kind of lazy loading which is a bit tricky and honestly, I have not seen in in action properly yet. - Mass-enabling
As written above, BOPF minimizes the number of DB accesses. But also thinking about ABAP, it is optimized for performance. Data redundancy (and copying) is minimized by transporting data references (to the buffer) through the interface-method-signatures. Furthermore, it uses and enforces modern ABAP performance tweaks such as secondary keys on internal tables. Last but not least ABAP can handle internal tables of structured data very well, while the instantiation of ABAP classes is comparatively expensive. - Dependency injection
As you probably noticed, BOPF injects the io_read and io_modify-accessors into the interface-methods. This not only ensures that the proper responsibilities are being adhered to (e. g. a validation, which shall only perform checks does not get a chance to change data, as there’s no io_modify), but it also simplifies mocking when it comes to unit-testing.
I hope you can now share my enthusiasm about the architectural patterns used in BOPF and may understand my skepticism about a “model-class".
- SAP Managed Tags:
- ABAP Development
14 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
A Dynamic Memory Allocation Tool
1 -
ABAP
9 -
abap cds
1 -
ABAP CDS Views
14 -
ABAP class
1 -
ABAP Cloud
1 -
ABAP Development
5 -
ABAP in Eclipse
2 -
ABAP Keyword Documentation
2 -
ABAP OOABAP
2 -
ABAP Programming
1 -
abap technical
1 -
ABAP test cockpit
7 -
ABAP test cokpit
1 -
ADT
1 -
Advanced Event Mesh
1 -
AEM
1 -
AI
1 -
API and Integration
1 -
APIs
9 -
APIs ABAP
1 -
App Dev and Integration
1 -
Application Development
2 -
application job
1 -
archivelinks
1 -
Automation
4 -
B2B Integration
1 -
BTP
1 -
CAP
1 -
CAPM
1 -
Career Development
3 -
CL_GUI_FRONTEND_SERVICES
1 -
CL_SALV_TABLE
1 -
Cloud Extensibility
8 -
Cloud Native
7 -
Cloud Platform Integration
1 -
CloudEvents
2 -
CMIS
1 -
Connection
1 -
container
1 -
Customer Portal
1 -
Debugging
2 -
Developer extensibility
1 -
Developing at Scale
3 -
DMS
1 -
dynamic logpoints
1 -
Dynpro
1 -
Dynpro Width
1 -
Eclipse ADT ABAP Development Tools
1 -
EDA
1 -
Event Mesh
1 -
Expert
1 -
Field Symbols in ABAP
1 -
Fiori
1 -
Fiori App Extension
1 -
Forms & Templates
1 -
General
1 -
Getting Started
1 -
IBM watsonx
2 -
Integration & Connectivity
10 -
Introduction
1 -
JavaScripts used by Adobe Forms
1 -
joule
1 -
NodeJS
1 -
ODATA
3 -
OOABAP
3 -
Outbound queue
1 -
ProCustomer
1 -
Product Updates
1 -
Programming Models
14 -
Restful webservices Using POST MAN
1 -
RFC
1 -
RFFOEDI1
1 -
SAP BAS
1 -
SAP BTP
1 -
SAP Build
1 -
SAP Build apps
1 -
SAP Build CodeJam
1 -
SAP CodeTalk
1 -
SAP Odata
2 -
SAP SEGW
1 -
SAP UI5
1 -
SAP UI5 Custom Library
1 -
SAPEnhancements
1 -
SapMachine
1 -
security
3 -
SM30
1 -
Table Maintenance Generator
1 -
text editor
1 -
Tools
18 -
User Experience
6 -
Width
1
Top kudoed authors
| User | Count |
|---|---|
| 4 | |
| 3 | |
| 3 | |
| 2 | |
| 2 | |
| 2 | |
| 1 | |
| 1 | |
| 1 | |
| 1 |