
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- A future-proof Big Data Architecture
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
werner_daehn
Active Contributor
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
10-10-2017
8:58 PM
Setting the stage
In my previous post, Hitchhiker's guide to Big Data, we explored the differences and similarities of Big Data versus Business Intelligence and why both are orthogonal to each other.
Based on this knowledge, this post proposes developing an architecture which suits the majority of the use cases. It puts emphasis on flexibility, but also considers cost of development and operations.
The hallmark diagram of the Big Data space is FirstMark's "Big Data Landscape" (below). It lists all the major players in the various aspects of the Big Data space. (Full text is found here)
This overview leaves it to us to understand all the tools - their individual pros and cons and challenges - and then figure out which to use when and how to combine them.

To begin tackling this landscape, let's first narrow down some terminology.
Reporting - Data Warehouse - Data Lake
Analyzing data is, mathematically speaking, nothing more than taking a set of data from the source, applying a function and visualizing the result: y=f(x).
Example: The dataset "x" shall be sales data in the ERP database. The function: a sum, grouped by customer's region and the result "y" visualized as a bar chart.
This is pretty much what happens in reporting - with one important issue: The ERP system gets new data - fine - but data is updated frequently as well. My classic example is when a customer moves from one region to another and suddenly the entire past(!) sales revenue is attributed to the new region. Not a good thing when two reports of the same data show different results.
[caption id="attachment_1012806" align="alignright" width="353"]
 Data Warehouse as a well structured ledger[/caption]
Data Warehouse as a well structured ledger[/caption]The solution is to build a Data Warehouse, where the data is maintained and historically correct, thus there would be two versions of the customer record with valid-from-to-dates. One positive side effect of copying the data is, the function f() can be split: Into a common part that is used always and a visualization-specific part. An example could be the calculation of sales revenue. Why would every single query execute the if-then-else decision tree to figure out what contributes to sales revenue, what does not? Much better to store the sales revenue as additional value, then the BI query is just a sum(revenue). Another advantage, although a purely technical one, is that a Data Warehouse can have a simplified data model to improve query speed. The data is well structured, easy to find (thanks to the simplified data model), fast to query and queries do not slow down the ERP system as they run on a different server.
That is the value proposition of a Data Warehouse and it is still valid.
Both of these approaches assume that the source dataset "x" is known upfront and its structure does change only a little over the years. While this assumption is valid for databases, in the grand scale of things this is a severe limitation. Starting with Excel sheets that should match but don't. Ending at completely unstructured text where everything is different. In the Reporting and Data Warehouse world, somebody has to create a common and agreed-on data model and then the data is squeezed into - semantics first and content later.
[caption id="attachment_1012805" align="alignright" width="300"]
 Data Lakes are very muddy[/caption]
Data Lakes are very muddy[/caption]The approach of a Data Lake is the reverse, first the content and then apply semantics to it. Or in more practical terms, store the raw data and provide tools for the users to play around with it.
In practice, due to the large number of information types, the large volumes and the number of rules to be known to each consumer of the data, many Data Lakes are more an accumulation of mud. Of course there is gold buried somewhere deep inside and of course any tool can be used, but finding it requires a lot of digging.
This does not necessarily mean that a Data Lake is a failed proposition, though it does require more resources. It needs more metadata to guide the user to the interesting places, more powerful tools, more knowledge and overall experience by the consumer. Not to mention, more processing power as both content and structure transformations are done at query time. In short, a Data Lake is typically for the Data Scientists out there, rather than the average user.
Another difference is the cost of storage between the two - storing a TB of data in a Data Warehouse database is way more expensive. And storing a PB of data is virtually impossible. No problem for a Big Data system, however.
Adding the fact that even Data Warehouse systems often have a staging area, thus combining the Data Warehouse as a Business Intelligence platform with the Big Data storage as Data Lake resp. the DWH Staging area makes sense.
Data Warehouse Architecture
[caption id="attachment_1012807" align="alignright" width="435"]
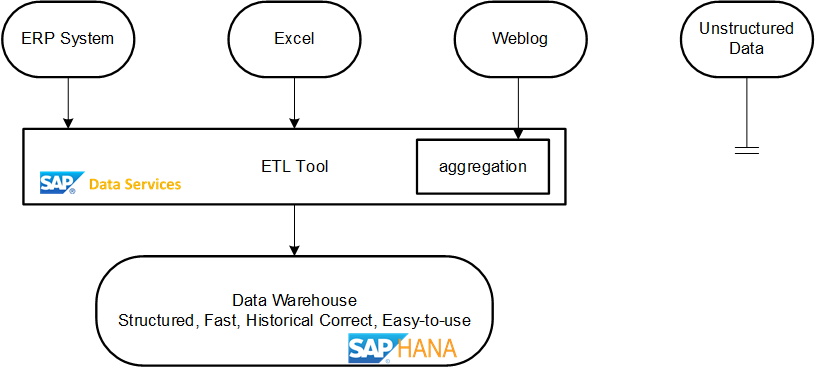 Classic Data Warehouse architecture[/caption]
Classic Data Warehouse architecture[/caption]To recap, in a classic Data Warehouse architecture there would be structured data sources like the ERP system, Excel sheets and more. This data is read on a daily basis from the source systems by an ETL tool, transformed into the Data Warehouse model to gain all the advantages of a DWH. Sources where the data volume would be too large - web logs as an example - are aggregated by a predefined logic and this data is stored as well in the DWH.
Unstructured data is usually not loaded. If there are predefined rules, e.g. source is a web forum and the text analytics process extracts the sentiment in combination with a dictionary, then no problem. On the other hand, if the text analytics configuration or its dictionary has to be changed to suit individual queries better, this cannot be achieved.
Evolution 1 - Big Data as Staging Area
[caption id="attachment_1012808" align="alignright" width="474"]
 Big Data Architecture 1st evolution[/caption]
Big Data Architecture 1st evolution[/caption]The next logical step is to preserve all the data and make it available. Here, all sources contribute their data into the Data Lake - including the weblog and unstructured data - and there are two consumers: the Data Warehouse and the Data Scientist.
Note: The Data Lake is not a copy of the source systems, it always appends to data. Hence it is historically correct as well.
The Data Lake contains the historical data and the Data Warehouse can be completely rebuilt from that. In that sense, the Data Warehouse somewhat resembles a Data Mart. An example would be deleting a customer in the ERP system. This information would be added/inserted into the Data Lake by adding the record and an additional column holds the delete flag. To be more precise, for each record there should be two additional columns, the change_timestamp (=timestamp when the data was received by the Data Lake) plus the change_type (=deleted yes/no).
To transform the data into easier-to-understand Data Warehouse structures, we can, of course, use the same ETL tool. But assuming the Data Scientist finds interesting algorithms, it would be beneficial to be able to also use these algorithms when loading the Data Warehouse. The current go-to tool for this chosen by Data Scientists is Apache Spark (not as user friendly as ETL tools very powerful), hence this architecture diagram assumes it is used for both. But everything is possible here and should be decided on a case by case basis.
As reminder, an ETL tool is about Extraction and Transformation. So its "E" part could be used to extract the change data from the source system and write it into the Data Lake. This data would then be read from the Data Lake and the regular Data Warehouse transformation would happen.
Evolution 2 - Big Data with Real-time
Another limitation of the classic Data Warehouse approach is its inherent batch-orientated thinking. While this does have upsides - some say that a Data Warehouse has to be loaded once a day only so users get the same data when refreshing the query - there are some obvious limitations as well. Either way, in today's fast paced world, real-time is key. The term "real-time" is used here as a synonym for "low latency", meaning the time between a change in the source to this change being visible in the Data Lake and Data Warehouse should be seconds (or less).
From a technical point of view this has a couple of issues. In the Data Lake...
- The data should be put into query optimized structures, e.g. Parquet Files. Parquet is a compressed and column orientated file format where single rows cannot be added to later. Storing each change as a new Parquet file would turn column & compression useless.
- Cluster processing (Map Reduce, Spark) is all about immutable files. But when a file cannot be changed, messages cannot be appended. The result is many files. Imagine as many files as there are change messages - millions per day - impossible to handle.
- Getting the changed data for loading it into the Data Warehouse is simple, thanks to the insert only into the Data Lake and the added change_time column. But the Data Warehouse is not loaded in realtime but batch then. Increased latency and higher resource consumption as consequence.
- This does solve the structured data, but not the unstructured image and text files. Okay, a new file was put in the Big Data storage but nobody knows about it?
[caption id="attachment_1012813" align="alignright" width="517"]
 Big Data Architecture with Realtime[/caption]
Big Data Architecture with Realtime[/caption]This is where Apache Kafka comes into the picture. Kafka is not so much a messaging system, not even a queuing system but best described as a distributed transaction log. Databases also have transaction logs but they are neither distributed nor easy to be consumed. Their use case is totally different: Databases use transaction logs for the strong transactional guarantees and for recovery, hence they cannot be distributed.
In Kafka, incoming data is stored to disk in a distributed manner and consumers can decide to either read through all changes of the last days, read from the last successful read onward or to subscribe to new incoming data and be notified within sub seconds. Because of the data distribution, the update frequency can be higher by factors, millions of change messages per second in fact, compared to databases. But there are limitations in payload size - say one message should be less than 1MB. With the combination of Kafka and the Data Lake, the best of both worlds can be combined, eliminating each other's downsides of the other.
The architecture diagram asks all sources to push their data to a central http endpoint which delegates the data. Structured data is validated and put into Apache Kafka and therefore offered to all consumers immediately. Files with unstructured data are put into the Data Lake and the file metadata also goes into Kafka. For example, a .jpeg file is uploaded and stored at a certain path in a Data Lake directory. The file location plus image metadata like width and height is put into Kafka. Therefore consumers would know right away when a new file was uploaded and its location. And in addition queries like "only large files" can be executed.
One Kafka consumer is the Data Lake writer, materializing all Kafka data into the Data Lake as the long term persistent store.
The consumers of data have the option to read the raw data from the Data Lake for batch orientated processing. And can register themselves to listen on Kafka messages to get notified about changed data right away. In the case of the Data Warehouse loader, the initial load would be done from the Data Lake reading its tables. And the program would listen on changes on the various Kafka messages to incorporate them into the Data Warehouse.
With this combination of Kafka and Hadoop, the above four problems are solved without doing much. The files in the Data Lake are large because the individual messages are collected in Kafka and written to the Data Lake only once per day or whenever there is enough data. This also solves the problem of immutable files as no changes need to be merged into existing data. And the file count remains low - one file per day in worst case. The change_time and change_type column is added by the http endpoint, hence its timestamp is strictly ascending - no side effects from delayed commits in databases.
Not to mention, it works for structured and unstructured data as both are offered in real-time. And large files do not pollute the Kafka transaction logs as the Kafka message contain the file location but not the file's binary content.
Active or Passive Data Lake storage - which to use?
How would the perfect Data Lake system look like? Coming from the relational world, the answer seems to be obvious. It would be some sort of a database where data is inserted, updated or deleted. For every type of information there is a table with well defined structures. In other words, there is an active process controlling the table structure, the data consistency and the data distribution. Some common downsides of databases are:
- Higher cost of storage
- The potential of database processes failing
- Less flexibility on the data structures as tables are fixed
In contrast, the Data Lake is simply a large file system, where none of the above problems come into play. All that's required is that each file contains the table structure and indexing internally, because then query performance will be database-like. There is no write concurrency as the file never changes, no data dictionary is needed as each file contains the table structure itself and no indexes are needed as the file is indexed internally. So by giving up on the insert/update/delete functionality and supporting insert only - something needed for historical data anyhow - the overhead of an active database can be avoided without giving up anything else.
To be more precise, in Hadoop/Spark a single table is represented by a directory(!), and not a single Parquet file. The table structure is the summary of all file structures.
Example: In Spark the user would execute a query select firstname, lastname, newfield from /home/data/customer_master;. The columns of this directory are the union of all file structures, e.g. customer_master_2017_10_01 has firstname and lastname but the customer_master_2017_10_02 file also has the column newfield, hence the directory has all three fields. Only that the newfield is null for the older files. See schema evolution for this feature.
This gives the best of both worlds - no active database process is needed and adding columns is as simple as writing a new file into that directory.
How does the SAP Leonardo IoT offering look like?
To validate the above thoughts, a quick look into the current IoT Reference Architecture might be interesting.
[caption id="attachment_1012826" align="alignright" width="585"]
 SAP IoT Reference Architecture[/caption]
SAP IoT Reference Architecture[/caption]The ultimate source here is a device, a Thing shown at the very left side. This sensor data is preprocessed by an Edge Component, that is a computing device responsible for all its local sensors, e.g. all sensors of a windmill. The goal here is twofold:
- Each sensor can use a short range communication channel like LAN or ZigBee. The Edge Component handles the more expensive Internet communication.
- To compress the data prior to sending it over the Internet. Compress in the sense of reducing the data in size but not in information - like a temperature sensor sending either 60 times a 20°C message per minute versus a single temperature change message: Just now this millisecond the temperature changed from 20°C to 22°C.
This Edge Component usually implements a MQTT communication protocol which the cloud (https) endpoint (=Device Connectivity) understands. It persists the data immediately in a Message Broker, which is Apache Kafka in SAP IoT.
For Kafka, two Consumers are defined. First the Stream Processor which materializes the data in the Data Lake in different formats for different use cases. The Raw Data is the original message received, the Time Series data does optimize the raw data for better querying, e.g. it receives an event timestamp but stores a valid-from-to timestamp. And it loads something we would have called a Data Warehouse with aggregated data.
The second consumer (=Real-Time Processing) is for events to show alarms right away and the such.
The only difference to the above architecture is that the Data Lake is not a file system with Parquet files but an active database from the Big Data space. And that Apache Spark is used internally but not made available to a Data Scientist (as of today).
Summary
- The combination of cheap storage in a Big Data filesystem (Hadoop HDFS or AWS S3), with Apache Kafka as realtime persistence with SAP HANA as Data Warehouse combines all advantages and eliminates each others disadvantages.
- Especially if SAP HANA's Smart Data Access feature is used in combination with Hadoop, the end result looks like one solution.
- Powerful, easy enough to manage, well established technologies, a logical architecture.
- SAP Managed Tags:
- SAP Datasphere,
- Big Data
Labels:
1 Comment
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,658 -
Business Trends
117 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
75 -
Expert
1 -
Expert Insights
177 -
Expert Insights
358 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
GraphQL
1 -
Kafka
1 -
Life at SAP
780 -
Life at SAP
15 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,575 -
Product Updates
398 -
Replication Flow
1 -
REST API
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,871 -
Technology Updates
493 -
Workload Fluctuations
1
Related Content
- AI@FRE (Part 1) - Enabling Enterprise AI Adoption through the BTP FRE Engagement Model in Technology Blogs by SAP
- Develop with Joule in SAP Build Code in Technology Blogs by SAP
- Enabling In-Order processing with SAP Integration Suite, advanced event mesh Partitioned Queues in Technology Blogs by SAP
- Unlocking the Potential of Business AI: Engineering Best Practices in Technology Blogs by SAP
- Integrating SAP S/4HANA with Kafka via SAP Advanced Event Mesh: Part1 – Outbound connection in Technology Blogs by Members
Top kudoed authors
| User | Count |
|---|---|
| 20 | |
| 8 | |
| 8 | |
| 7 | |
| 6 | |
| 6 | |
| 5 | |
| 5 | |
| 5 | |
| 4 |