
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- A Guide to Advanced RAG Techniques for Success in ...
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Product and Topic Expert
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
12-22-2023
12:05 PM
INTRODUCTION
In the dynamic landscape of Artificial Intelligence (AI), the intersection of Retrieval Augmented Generation (RAG) and Large Language Models (LLMs) has become a strategic linchpin for organizations seeking value out of Generative AI. This symbiotic relationship has propelled businesses, including those rooted in the data & process rich SAP ecosystem, to new heights of innovation. As organizations across the globe adopt RAG and LLMs for Generative AI use cases, it is imperative to delve into advanced techniques that not only enhance the quality of generated content but also align with the cost-conscious facet of enterprises. Within the SAP community, where precision and efficiency are paramount, understanding and implementing these advanced RAG methods can be the key to unlocking great capabilities while optimizing fiscal responsibility.
PUBLISHED USE CASES
Within our organization, we have successfully implemented some impactful use cases utilizing RAG. One instance involves the development of an intelligent engine to synthesize JSON payloads and ancillary information for an event-driven orchestration framework, called Events-to-Business (E2B), on SAP BTP for the execution of SAP business workflows triggered by events coming from SAP, non-SAP or 3rd party IoT devices. We were able to successfully feed the RAG engine with raw API data and retrieve necessary fields, relative paths, etc for a given use case definition. Moreover, we enabled action chaining wherein the main action accompanied by a pre-action and post-action was generated by a single user query. Please refer to this blog for more details. The architecture diagram is given in Figure 1.

Figure 1: E2B Architecture
Another interesting use case is the GenAI Mail Insights which is a sample solution offering sophisticated mail insights and automation within a comprehensive, (multitenant) SAP BTP solution enriched with advanced AI features. Leveraging LLMs through the generative AI hub in SAP AI Core, the solution analyses incoming mails, providing services such as categorization, sentiment analysis, urgency assessment, and extraction of key facts to imbue a personalized touch. It uses RAG with mails as embeddings. This feature enhances the solution's ability to identify similarities in requests, incorporating confirmed responses as additional context to mitigate hallucinations and ensure consistent service quality. Beyond this, the solution extends its capabilities to summarize and translate simple mail inquiries. This comprehensive suite of functionalities positions the GenAI Mail Insights solution as an indispensable tool for optimizing customer support processes and delivering a consistently high level of service. Please read this blog for more information. The architecture diagram for multi-tenant BTP apps using generative AI hub is shown in Figure 2.

Figure 2: GenAI Mail Insights Architecture
UNDERSTANDING RAG
RAG is a nuanced natural language processing approach that synergizes information retrieval and generative models. In a typical RAG setup, a retriever model fetches relevant information from a knowledge base, serving as input for a generative model that refines and generates responses. This dual-model strategy combines the precision of retrieved knowledge with the creative capabilities of generative models, proving effective in tasks requiring factual accuracy and creative generation. RAG finds applications in question-answering systems, content creation, and dialogue systems, showcasing its versatility in optimizing generative model outputs through context integration. Figure 3 gives a pictorial understanding of the method.
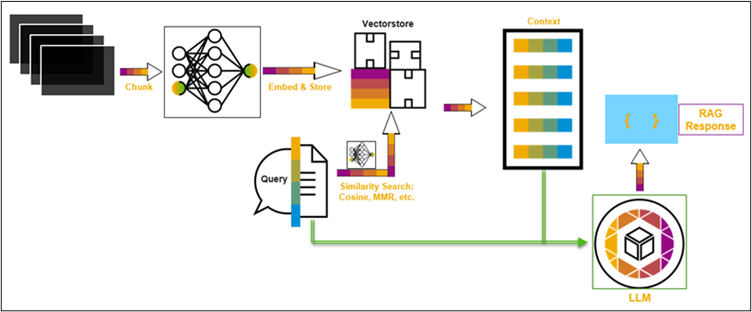
Figure 3: Concept of RAG
RAG is of great value in business as it circumvents the need to fine-tune LLMs, which albeit effective, is not cost efficient. With RAG all the users must do is add the custom knowledge to the existing base of the LLM. But it comes with its own share of downsides, like inability to handle ambiguous user queries which might trigger over dependency on the LLM’s training knowledge base rendering the custom data infusion in vain. On the contrary, there are also cases wherein the over-reliance is seen on the retrieved information. Personal experience with RAG also shows its tendency to hallucinate. RAG is very sensitive to a few hyper-parameters like the number of documents selected after similarity search and embedding dimensionality.
RAG stands as a significant asset in business applications, offering an efficient alternative to the process of fine-tuning LLMs, which, though effective, proves to be less cost-efficient. RAG streamlines user involvement by the addition of custom knowledge to the existing LLM base. However, it introduces challenges, such as:
- Limited capacity to handle ambiguous user queries. This constraint may result in an overreliance on the LLM's training knowledge base, potentially undermining the efficacy of custom data infusion.
- Conversely, instances of overdependence on the retrieved information have been observed. Personal experiences with RAG also reveal a tendency for hallucination, where the model generates content not grounded in factual knowledge.
- RAG exhibits sensitivity to specific hyperparameters, like the number of documents selected after similarity search and embedding dimensionality.
- Similarity search requires embeddings, creating and storing which can often be a time-consuming affair.
Addressing these challenges requires a nuanced approach that also does vigilant token management making RAG substantial. On exploring advanced methods for RAG, business landscapes can benefit from the full potential of generative AI. Two of the most cutting-edge and popular methods of RAG are Sentence Window Retrieval (SWR) and Auto Merging Retrieval (AMR) which will be discussed below. Both methods have shown to produce better results all the while optimizing token usage, and the time consumed in conducting the similarity search in vector databases. They rely on simple reasoning and straightforward techniques.
SENTENCE WINDOW RETRIEVAL
The philosophy behind SWR is to retrieve, based on the query, pointed context from the custom knowledge base and use a broader version of the same for a more grounded generation. In this process, a limited set of sentences are embedded for retrieval. The additional context surrounding the said sentence, or "window context", is stored separately, linked to these sentences. After identifying top similar sentences, this context is reattached just before those sentences are sent to the LLM for generation, enhancing the overall contextual understanding. By narrowing the focus to a specific window of sentences, this approach seeks to enhance the precision and relevance of information extracted facilitating expansive synthesis of text. Figure 4 explains the concept.

Figure 4: SWR
An important consideration here is the size of context window, i.e., how many sentences before and after the embedded sentence will be ushered in the LLM for generation. This method enhances several aspects of traditional RAG.
- Increased Precision: Narrowing the search to a specific sentence or set of sentences can increase the precision of information retrieval. It filters out unnecessary information which could potentially dilute the relevance of the results.
- Efficiency: It’s quicker as it minimizes the amount of text to be processed or read while looking for specific information. It avoids searching through long documents and makes information retrieval more efficient.
- Flexibility: The technique allows researchers to adjust the size of the window of text around their keywords, offering greater flexibility in their searching strategy.
It is observed that since SWR focuses on specific sentences that contain relevant information, the token usage is reduced. But there is a trade-off in the form of a possibility that pivotal chunks of text might not be embedded and can slip into the surrounding context. It becomes important to identify the right context window hyperparameter to overcome the issue.
RERANKING
To further improve the performance of SWR, a method called reranking is used after the first set of most similar embedded chunks are retrieved. The idea here is to refine the search results and further optimize token consumption. It acts as another layer of protection before the final generation step. The concept is explained in Figure 5.

Figure 5: Reranking in Retrieval
The reranker is mostly a Natural Language Processing (NLP) transformer which is trained (or fine-tuned) for the specific task. The model that is responsible for re-evaluating and reordering the retrieved information based on its relevance to the given task or query. Some of the most popular rerankers in use are:
- BAAI-bge-reranker family (on HuggingFace)
- Cohere reranker (on LangChain)
- bert-multilingual-passage-reranking (on HuggingFace)
These models are mostly based on neural network architecture and work with embeddings to evaluate numerical quantification of similarity between query and given chunk embedding. These are optimized to carry out computations in orders or few milliseconds per query and so are computationally feasible.
BUSINESS VALUE
SWR as an approach in RAG introduces noteworthy value to the ERP domain as well as the broader business landscape. This is particularly evident given the typical construct of business documents. Often, these documents comprise core, high-impact sections with critical data, supplemented by ancillary contextual information. Implementing SWR also addresses another practical problem in enterprise document management the occurrence of sparse yet vital context within vast documents. Instead of diluting the model's focus across expansive documents, SWR-based RAG pipeline can be deliberately deployed on parts of documentation characterized by context sparsity. This tactic enables businesses to extract the most consequential information, even from the most informally structured or textually lean documents. Blending SWR into the larger RAG model requires careful segregation of the instances and a nuanced understanding of the dataset to appropriately set the window boundaries.
Reranking as a method holds immense business value as well. They are based on an advanced level of sophistication, going beyond simply matching search terms to data points through cosine similarity, geometric distances, etc. They operate by strategically ordering retrieved documents or data, according to their relevance to the search input. Another advantage of reranking is its potential for cost optimization. By effectively prioritizing the most relevant documents and reducing the context size, reranking empowers businesses to make more efficient use of computational resources. One of the most compelling aspects of reranking frameworks is their inherent “plug-and-play” nature. They can be seamlessly integrated into existing RAG pipelines, enhancing the effectiveness of search and retrieval without disrupting current workflows.
AUTO MERGING RETRIEVAL
In a conventional RAG setup, the process of dividing information into chunks can inadvertently lead to the extraction of fragmented sentences. These bits and pieces, when used for retrieval, may affect the quality and coherence of the final output. For instance, consider a scenario where, instead of retrieving diverse pieces of information from across the document, three or four chunks are yielded from the same section. This could impede the overall effectiveness of the retrieval pipeline, making it less diverse and representative of the information within the document. Lack of assurance about the sequence in which these chunks are retrieved could potentially disrupt the logical flow and narrative continuity during the generation step.
Considering business documents like financial statements, sales reports, customer reviews, or product details, relevant data is often cross-linking. SWR, despite its utility, remains confined within its set parameters and might overlook crucial snippets of information lying outside its purview. This could result in incomplete analysis or context misalignment, which are downsides when dealing with complex business document analysis. To solve for these issues, AMR was introduced. AMR with its ability to dynamically identify and piece together relevant information across databases, offers an integrated overview. This enables businesses to leverage their resources efficiently and build RAG pipelines for inter-meshing data streams.
AMR works by creating a hierarchy of smaller leaf chunks that link up to the so-called parent chunks. In the retrieval step, if the number of retrieved leaf chunks are greater than a set threshold, all the leaves are replaced with their parent chunk, giving a broader context. There can be intermediate chunks that would behave in the same manner. Figure 6 explains the concept.

Figure 6: AMR
We see that the parent chunk with N tokens is split into three child (here, intermediate) nodes with N/3 tokens, each further divided into five leaf nodes. For the leaf node level, we set the threshold to two, meaning if the number of selected leaf nodes for a given intermediate node is greater than two, we end up selecting the intermediate node (or the parent node in case of depth level of one). For the middle level, the threshold is one. In case the number of intermediate nodes selected were greater than one, we would then send the parent node with N tokens to the LLM as context.
To streamline AMR, only the leaf nodes are embedded and then provided to the similarity search algorithm. This reduces the computational load and makes the operation more efficient. Meanwhile, all the parent and intermediate nodes are stored separately in a dedicated document store, or docstore for short. What the docstore essentially does is provide a faster way to reference these parent and intermediary nodes connected to a specific leaf node. Additionally, to conserve the pipeline's utilization of tokens, reranking is carried out at various levels of the document's chunk tree. For instance, following the similarity search with the leaf nodes, suppose we have fifteen intermediate nodes that serve as the context. Reranking would filter these down to say the top ten nodes.
BUSINESS VALUE
AMR is of tremendous value for ERP and business documents in general. ERP systems and business documents often involve dealing with high-dimensional data. AMR can handle data from multiple, diverse sources effectively. Often for information belonging to say given business process, the pertinent scrapes of data can be present in multiple other systems or documents. Crafting a chunk tree structure with subsequent AMR can result in accentuated content generation. AMR can handle large volumes of data spread across diverse business functions and sources, making it highly scalable. As the business grows and more data is added, AMR can be scaled up to match these growing requirements thereby enabling dynamism of data. The manually set threshold for conversion to parent node is an important hyperparameter but is easily tweaked by evaluating relative performance. Considering these technical advantages, AMR offers a great way to unify and optimize the process of data retrieval in complex business and ERP scenarios.
CONCLUSION
To conclude, the exploration of RAG, SWR, reranking, and AMR has revealed the significant potential and evolution of these techniques in the realm of business data analytics and ERP ecosystems. Their applicability and effectiveness in diverse business scenarios, such as those seen throughout the organization's case studies, have underscored their critical role in improving data retrieval and processing. While traditional RAG has delivered value, SWR and AMR emerges as a game-changer, overcoming key limitations and enhancing the accuracy and coherence of retrieved information. They pioneer a more dynamic and comprehensive manner of analyzing voluminous and complex data enabling strong adoption of Generative AI for business processes.
For more information about this topic or to ask a question, please contact us at paa_india@sap.com
- SAP Managed Tags:
- Artificial Intelligence,
- SAP AI Services
Labels:
6 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,658 -
Business Trends
103 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
69 -
Expert
1 -
Expert Insights
177 -
Expert Insights
322 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
GraphQL
1 -
Kafka
1 -
Life at SAP
780 -
Life at SAP
13 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,576 -
Product Updates
367 -
Replication Flow
1 -
REST API
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,873 -
Technology Updates
454 -
Workload Fluctuations
1
Related Content
- revamped SAP First Guidance Collection in Technology Blogs by Members
- SAP Datasphere News in April in Technology Blogs by SAP
- Unlocking the Potential of Signavio Collaboration Hub – Variant Management in Technology Blogs by SAP
- Threat Actors targeting SAP Applications in Technology Blogs by Members
- Second time a Leader in the Gartner® Magic Quadrant™ for Process Mining in Technology Blogs by SAP
Top kudoed authors
| User | Count |
|---|---|
| 24 | |
| 9 | |
| 8 | |
| 7 | |
| 7 | |
| 6 | |
| 6 | |
| 6 | |
| 6 | |
| 6 |