With the release of SAP Web IDE SPS07 and HANA 2.0 SPS07, new features in the area of calculation view modeling will become available that had only been released in SAP HANA Cloud before.
Below is a short description of newly released features. For examples of the individual features have a look at the respective project "SPS07_Selected_Calculation_View_Modeling_Features" that can be found
here.
Comments in Expressions
Use comments in expressions to better document the intention behind expressions. This will help during later refactoring and improve collaborative working.
Comments can be entered using one of the two styles:
/* comment */
-- comment

Comments in calculated columns

Comments in filter expressions
Calculation View Snapshots
In tab “Snapshots” you can define individual queries for calculation views. Based on these queries procedures are generated that create, drop and insert into snapshot tables:
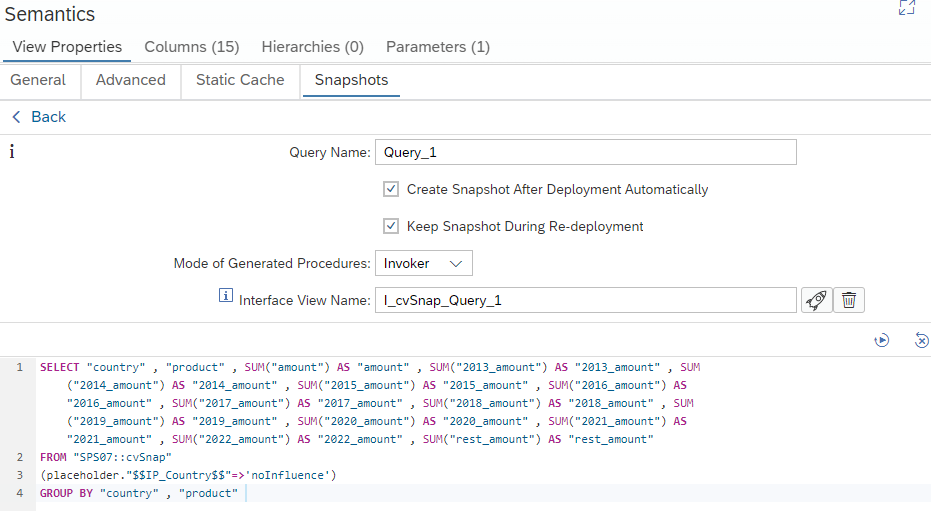
Define a snapshot query
This provides a flexible means to store the results of a query at a certain point in time. The life-cycle of these procedures is controlled by the calculation view.
In addition, a calculation view can be generated to easily toggle between online and snapshot data:

Generate Interface View

Interface View that implements constant union pruning
With snapshots an easy and flexible option exists to reduce resource consumption and to speed up queries if slightly outdated data are acceptable. See the
modeling guide and
performance guide for developers for more information.
Median Aggregation
Median aggregations provide statistics that are more robust against outliers than statistics such as Average. The aggregation type Median is now available for measures and calculated measures.
Mask columns based on session user
Masking of columns can be done based on the user who is calling the calculation view which contains the mask definition or based on the session user which is running the SQL query.
In a stacked scenario, the calling user will be the owner of the including calculation view while the session user will be the user who runs the SQL query.
To switch between the different modes, use the view-global setting Mask Mode:
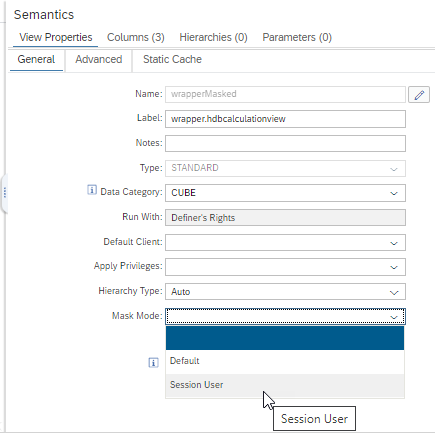
session user masking
With the new option to mask based on the session user, masking in stacked scenarios becomes significantly easier.
System-Versioned and Application-Time Tables
When using system-versioned or application time-period tables in calculation views, the resulting data can be filtered by certain timestamps or time periods. The relevant selection criteria can be defined for each individual data source using constants, expressions, or input parameters.
This simplifies time-traveling analytics with focus on data as of a certain time-point or period.

example of Temporal Source setting
The settings for individual data sources can be overwritten in the Semantics:
Pressing the Apply button here will set the displayed value for the matching entry fields of all temporal sources of the current calculation view.
Fill time tables using SQL statements
Gregorian date and time information could be generated for a specific time period by invoking the "Maintain Time Tables" dialog in the past:
These data can be used for example, to find out which week-day a certain date is, or to join to an interval of days, or to map between different date representations.
However, sometimes, e.g., in productive systems no development environment is connected.
With procedure
UPDATE_TIME_DIMENSION in schema "SYS", time tables can now be filled using SQL only. This makes also scheduling of regular updates easier.
For example, the following statements when executed with e.g., database user SYSTEM would create a table "DAY_GRANULARITY_2018_2025" in schema "TIMEDATA" that contains data between 2018 and 2025 at the granularity of days:
CREATE SCHEMA TIMEDATA;
CALL SYS.UPDATE_TIME_DIMENSION('DAY',2018,2025,0,'TIMEDATA','DAY_GRANULARITY_2018_2025',?);
A similar procedure can be used to fill the fiscal calendar: SYS.
UPDATE_FISCAL_CALENDAR.



