
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- Import data from files to SAP HANA Cloud
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
former_member43
Contributor
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
10-27-2020
11:52 AM
In this blog I will introduce how to import data from flat files to SAP HANA Cloud.
There are several methods you can use, depending on your requirements and the data size.
Overall, I would recommend to use DBeaver to manually import CSV files up to ~1GB.
Use the "IMPORT FROM" SQL statement to import larger files from Amazon S3, Azure storage, Alibaba Cloud OSS and Google Cloud Storage.
If you need to import files other than CSV or to pre-process your data, Python is the most versatile tool.
If you need to import many files based on a pattern and/or at repeated intervals, use the SAP HANA Smart Data Integration File adapter.
1. hdbtabledata
As said in this blog, when the import of the data is connected to modelling tasks in SAP Web IDE Full-Stack or SAP Business Application Studio, you can insert test small files up to 10MB directly in your database projects. Place files you want to import directly into the design-time definition of the HDI container and define the import via an .hdbtabledata HDI artefact.
This approach only supports .csv files.
Keep attention when working with Git. Most Git repositories have size limits. It is not a good practice to check in large files in a Git repository, nor to put it into a project in SAP Web IDE.
Find .hdbtabledata loading samples on Github.
2. SAP HANA Database Explorer
Learn more about the HANA Database Explorer through the official tutorial.
You can use the data import function of the SAP HANA Database Explorer to import CSV files up to 1GB as well as ESRI shapefiles from your local PC.
From the Database Explorer, you can also import CSV, PARQUET and Shapefile files from Amazon S3, Azure storage, Alibaba Cloud OSS and Google Cloud Storage.
Access the database explorer from your SAP HANA Cloud instance on the SAP Cloud Platform Cockpit.

Within the Database explorer, you can access all your HDI containers. Right click on the database/HDI container in which you want to import data, and select "Import Data".

You first need to choose the import type : Data (CSV) or ESRI Shapefile.

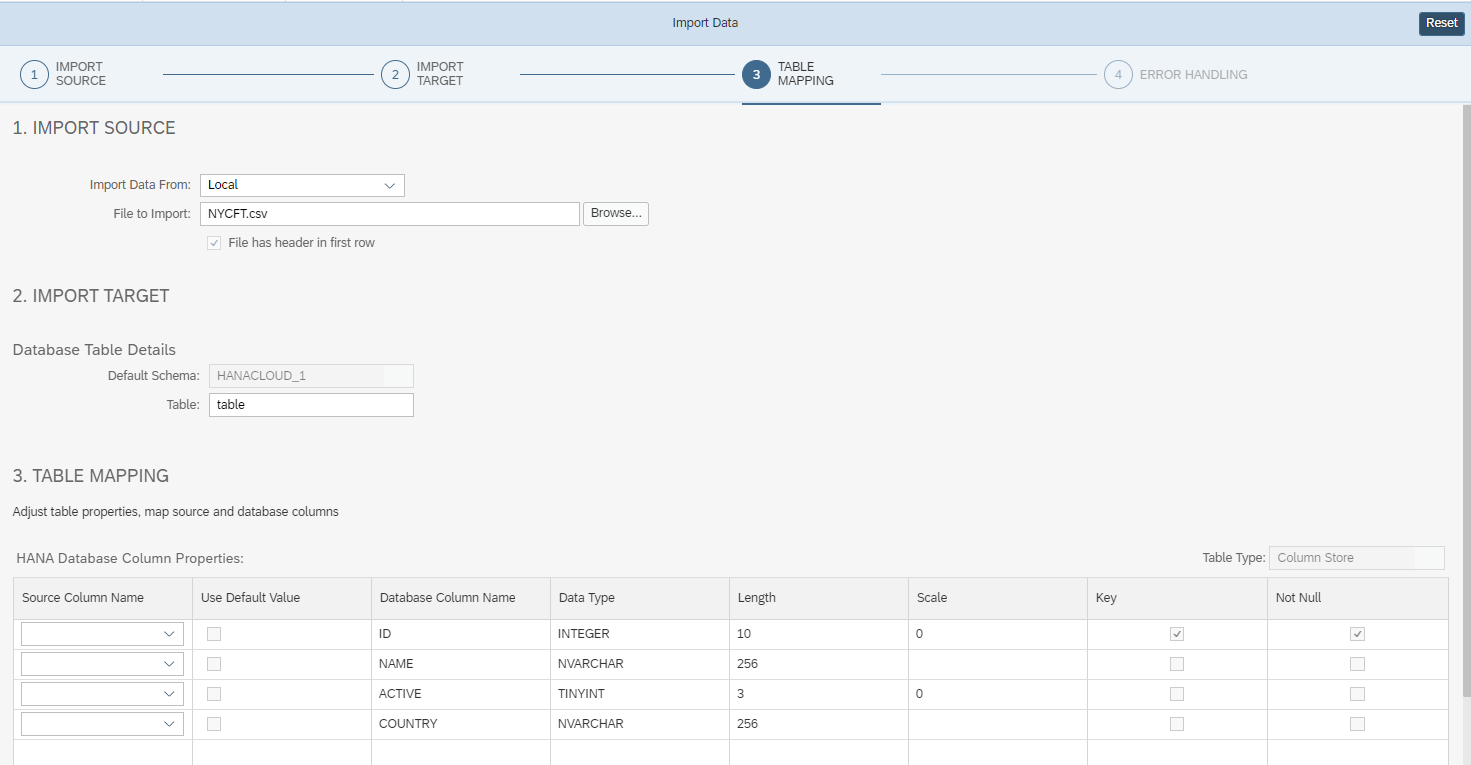
If you choose "Import Data", the "Import Data" wizard will open up. You can select the CSV file, then your import target table.
If you want to import files directly from Amazon S3 or Azure, you need to register the IaaS certificate into SAP HANA Cloud first. For details, refer to section '5. "IMPORT FROM" SQL statement' of this blog.
If you choose Amazon S3 as the import source in the UI, you need to set the S3 region and the S3 path, made of your IAM user access key and secret key, as well as your bucket name and object ID. Just enter them as requested by the UI.
Select the table where you want to import data.

In the import options, you can choose the file format (CSV, PARQUET), you can choose whether to use the first row as column names, delimiters and date formats.
Set the error handling, and you can start importing your file !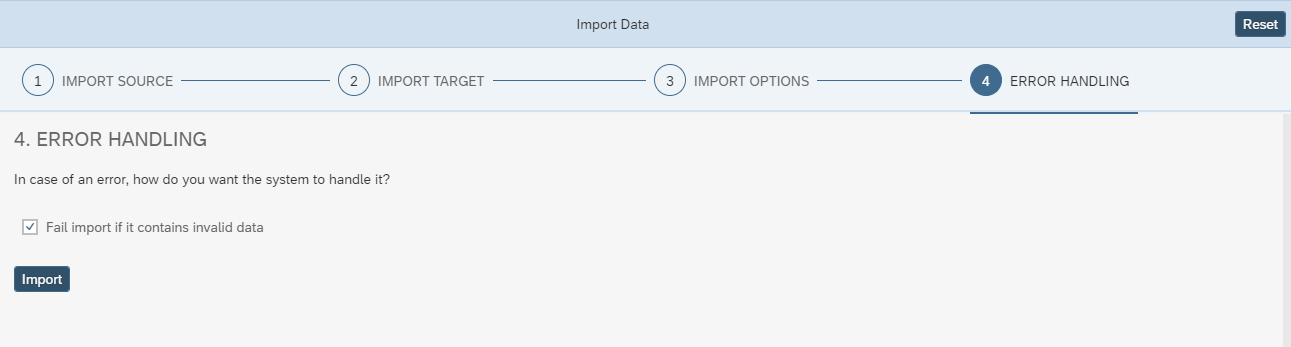
3. DBeaver
If you use SAP HANA Cloud as a datawarehouse, I definitiely recommed DBeaver to manage your data. DBeaver has a very intuitive data import function which lets users import data from CSV files.
First, establish a secure connection from DBeaver to SAP HANA Cloud. Then, right-click on the schema where you want to import data and select "Import data".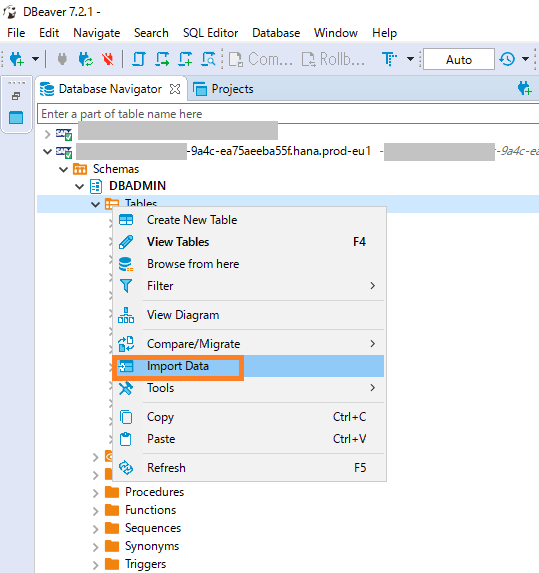
Follow the wizard to choose the data to import.
In this example I use a 100MB sample dataset from Kaggle with 1019925 records.
Set the importer settings.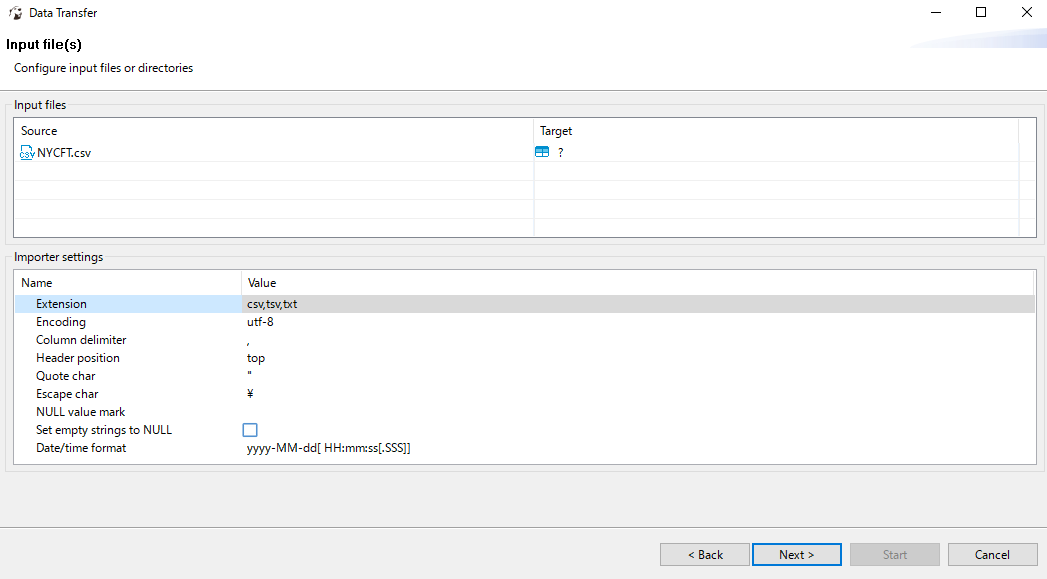
You can manually set the table mapping, or leave it as default. The importer is able to create automatically a new table in SAP HANA Cloud for you.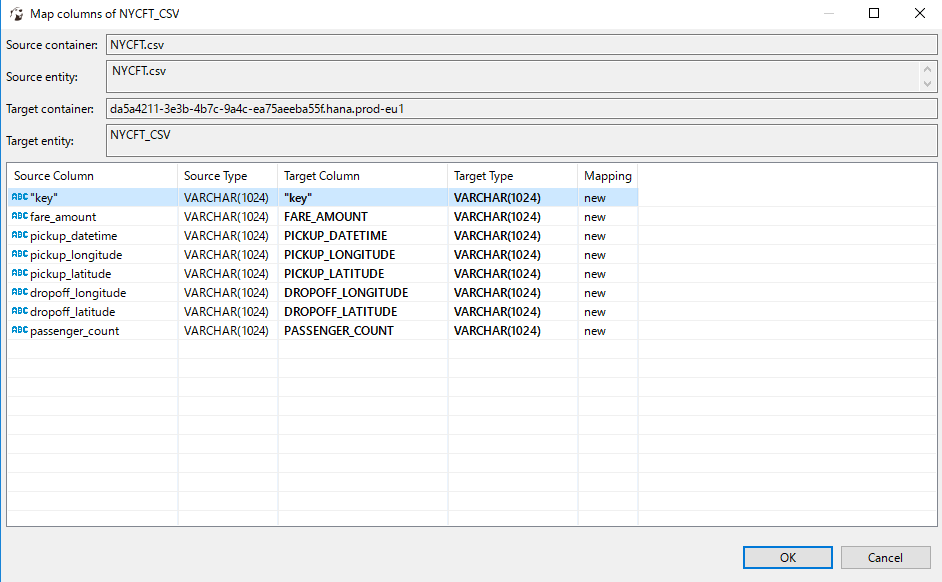
These are the default columns created for my CSV file.
In the data transfer option, you can decide how often the imported data should be committed. This has an impact on the import time for large files.
Confirm that everything is correct, then start the import.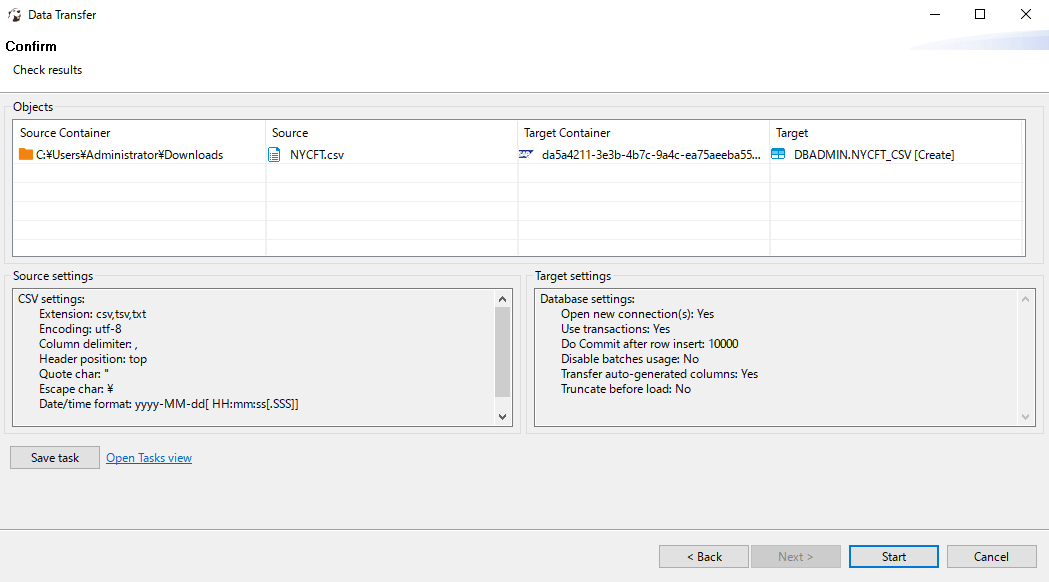
I was able to import a 100MB CSV file from my client to SAP HANA Cloud in 4 minutes with DBeaver.
As a reference, importing that same file to a SAP HANA 2.0 SPS05 instance located on my local network takes 12 seconds with DBeaver.
4. Python
If you need to pre-process data before inserting it into SAP HANA Cloud, Python offers a powerful and flexible environment.
I used the same 100MB CSV file as in the DBeaver example to compare import performance.
I started by creating a new Jupyter notebook in the directory where my CSV file is located.
In the notebook, start by importing the hana_ml library,
establish the connection to SAP HANA Cloud,
read your CSV file with pandas,
create a dataframe in the SAP HANA Cloud database containing your data,
and finally close the connection.

Here is the python code I used. The HANA ML dataframe allows developers to use data in HANA as a pandas dataframe. This means you can prepare the data to fit your needs. Learn more about an actual use case in this blog by Andreas.
!pip install hana_ml
import hana_ml
print(hana_ml.__version__)
import hana_ml.dataframe as dataframe
# Instantiate connection object
conn = dataframe.ConnectionContext(address = 'hostname.hanacloud.ondemand.com',
port = 443,
user = 'user',
password = 'password',
encrypt = 'true'
)
# Send basic SELECT statement and display the result
sql = 'SELECT 12345 FROM DUMMY'
df_remote = conn.sql(sql)
print(df_remote.collect())
import pandas as pd
df_data = pd.read_csv('NYCFT.csv', sep = ',')
df_data.head(5)
df_remote = dataframe.create_dataframe_from_pandas(connection_context = conn,
pandas_df = df_data,
table_name = 'NYCFT_PYTHON',
force = True,
replace = False)
conn.close()The data import finished in 9 minutes. This confirms the results of Lars Breddermann that DBeaver is around twice as fast as Python regarding data import to SAP HANA Cloud.
I used the hana_ml library to import data the simplest way I could, but you can also use other libraries such as SQL Alchemy.
5. "IMPORT FROM" SQL statement
Finally, if you have a very large dataset, the fastest way to import data to HANA Cloud is to use the built-in "IMPORT FROM" SQL statement.
Follow the official documentation to enable data import directly from your IaaS platform. For this guide, I used AWS.
First, you will need an AWS account, with S3 enabled and your files need to be uploaded to S3. I used the same file as in the DBeaver and Python examples to compare performance.

In the IAM section, create a user with API access. You will receive an Access key ID and Secret access key.

Grant the necessary access permissions to your IAM user. I granted the AmazonS3ReadOnlyAccess policy to my user, which gives access to all files on S3 for my account. You can also give a more granular access if necessary.

Now you must register the certificates necessary for the SSL connection to S3.
REST API-based adapters communicate with the endpoint through an HTTP client. To ensure secure communication, the adapters require client certificates from the endpoint services. Connections to an SAP HANA Cloud instance, which are based on the hanaodbc adapter, also require an SSL certificate.
Here are the two necessary certificates to connect to AWS S3 :
Amazon Root CA
Digicert Baltimore CyberTrust Root CA (download PEM):
Amazon Root CA
Digicert Baltimore CyberTrust Root CA (download PEM):
Copy each root certificate text and create a certificate from this text which can be saved in a personal security environment (PSE).
Execute these SQL statements towards your SAP HANA Cloud database :
- Create a PSE.
create pse HTTPS;- Create a certificate.
CREATE CERTIFICATE FROM '
-----BEGIN CERTIFICATE-----
...
-----END CERTIFICATE-----
' COMMENT <comment>; The created certificate is now contained in the CERTIFICATES system view and can be added to a PSE store.
- Add the certificate created above to the PSE:
SELECT CERTIFICATE_ID FROM CERTIFICATES WHERE COMMENT = '<comment>';
ALTER PSE <pse_name> ADD CERTIFICATE <certificate_id>;- Set the purpose of the newly created PSE to REMOTE SOURCE:
SET PSE <pse_name> PURPOSE REMOTE SOURCE;This makes the usage of the certificates in the PSE store available to all remote sources.

Now that the Personal Security Environments are set up, you can import data from AWS S3.
IMPORT FROM CSV FILE 's3-<region>://<access_key>:<secret_key>@<bucket_name>/<object_id>.csv' INTO <TARGET_TABLE_NAME> [with options];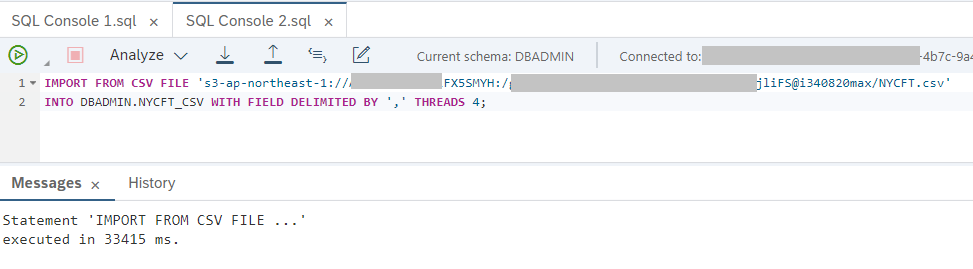
For my 100MB CSV file, the command took 34 seconds to execute.
Learn how to leverage the IMPORT FROM command from a front-end application on this blog by Naoto Sakai : Import data from Object Store to SAP HANA Cloud.
There are other methods which I did not explore to import data to SAP HANA Cloud, such as SAP HANA Smart Data Integration File adapter, hdbsql, or the JDBC/ODBC drivers.
The SAP HANA SDI File adapter is particularly useful for these use cases :
- SharePoint access
- SharePoint on Office365
- Pattern-based reading; reading multiple flies in a directory that match a user-defined partition
- Real-time file replication (only APPEND)
Learn how to Use the SDI FileAdapter to write to Azure file share in Sohit's blog.
In conclusion, each file import has its merits depending on your use case. Find the method which fits your needs.
Thank you for reading,
Maxime SIMON
Special thanks to Daisuke Ikeguchi for his support in writing this blog.
- SAP Managed Tags:
- SAP HANA Cloud
Labels:
7 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,658 -
Business Trends
107 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
72 -
Expert
1 -
Expert Insights
177 -
Expert Insights
340 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
GraphQL
1 -
Kafka
1 -
Life at SAP
780 -
Life at SAP
14 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,575 -
Product Updates
384 -
Replication Flow
1 -
REST API
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,872 -
Technology Updates
472 -
Workload Fluctuations
1
Related Content
- First steps to work with SAP Cloud ALM Deployment scenario for SAP ABAP systems (7.40 or higher) in Technology Blogs by SAP
- SAP CAP - Access HDI in a different cloud foundry space: Deployment Error (Invalid Role Name) in Technology Q&A
- Import Data Connection to SAP S/4HANA in SAP Analytics Cloud : Technical Configuration in Technology Blogs by Members
- Exploring ML Explainability in SAP HANA PAL – Classification and Regression in Technology Blogs by SAP
- Automated check for SAP HANA Cloud availability with SAP Automation Pilot in Technology Blogs by SAP
Top kudoed authors
| User | Count |
|---|---|
| 17 | |
| 14 | |
| 12 | |
| 10 | |
| 9 | |
| 8 | |
| 7 | |
| 7 | |
| 6 | |
| 6 |