
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- Setup an AI Vector Database using the PostgreSQL o...
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Product and Topic Expert
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
08-30-2023
9:24 PM
ImportantFollowing the recent TechEd 2023 announcement of the SAP HANA Cloud Vector Engine, our architectural guidance for AI solutions on the SAP Business Technology Platform (BTP) emphasizes a strategic alignment with SAP HANA Cloud, particularly in terms of vector functionalities. Utilizing the pgvector extension for storing vectors should be regarded as a transitional solution, recommended until the corresponding SAP HANA Cloud features become generally available in Q1 2024. Please also refer to the official reference architecture for Retrieval Augmented Generation with GenAI on SAP BTP. |
SummaryUse the Extension API to enable pgvector within your SAP BTP PostgreSQL service instance. 1. Entitle the Service in your landscape: Entitle your subaccount for PostgreSQL on SAP BTP with the Hyperscaler Option for your vector database needs. 2. Create Service Instance and Credentials: Set up a service instance with the appropriate configurations. Ensure you're using PostgreSQL version 13 (engine_version) or higher. Generate a Service Key or Binding that contains the necessary details for accessing the service. 3. Invoke the Extension API: Call the Extension API using dedicated endpoints and authentication approaches for Kyma and Cloud Foundry. API Endpoint https://api-backing-services(-k8s).<Region>.data.services.cloud.sap/v1/postgresql-db/instances/<Post... In Kyma, please add the -k8s suffix to the API Endpoint as depicted above. CURL HTTP Call curl -X PUT 'API_ENDPOINT_URL' \ --header 'Content-Type: application/json' \ --data-raw '{"database": "DATABASE_NAME"}' \ Cloud Foundry --header 'Authorization: bearer BEARER_TOKEN' Kyma --cert client-cert.pem \ --key client-key.pem In Kyma, you'll need a client certificate and key for authentication. In Cloud Foundry, get a Bearer token by calling cf oauth-token. Other details can be found in the Service Key/Binding. |
Dear community,
The buzz around Artificial Intelligence (AI) is everywhere, and SAP is fully on board, investing heavily in AI solutions. When we were developing a reference architecture for AI-based scenarios on the SAP Business Technology Platform, we hit a roadblock: we needed a vector database to store our embeddings. Today, I'm excited to walk you through the process of setting up a vector database using the current SAP BTP Service Offerings! 🌐

For our specific situation, we opted for the PostgreSQL on SAP BTP with the Hyperscaler Option. You can find more details in the SAP Discovery Center (click here). This choice was easy because this service allows us to enable the necessary pgvector extension we need.
In this blog post, I'll show you how to activate this extension on your own Free Tier service instance, and the best part? It only takes a few minutes! ⏲️
So, let's jump in and see how you can get a Vector Database based on PostgreSQL up and running in your own SAP BTP landscape. 🚀
Given that the free service plan is (as of today) accessible only within AWS regions, our walkthrough will center around this particular setting. If you are using the Cloud Foundry runtime and you find yourself gravitating towards Azure or Google Cloud Platform, this is also a valid and equally powerful option for scenarios beyond free tier service plan usage.
If you choose to go with Azure or GCP, please conduct a brief examination to confirm the availability of pgvector extension with the existing PostgreSQL service offerings, as we have not tested the setup in these environments yet (Important - based on recent feedback - see comments - the availability for Azure regions is planned for Q4/23).
It's worth noting that if you're using Kyma, as of today, the PostgreSQL on SAP BTP, Hyperscaler Option is only available in AWS regions. 🌍
Set up the Service Instance
Let's transition from the pleasantries and dive right in. First things first, ensure that you've successfully entitled the relevant free PostgreSQL service plan within your Subaccount entitlements. If your aspirations lean toward configuring a setup that's geared for productive utilization, I recommend opting for one of the alternative plans at your disposal. Don't forget to factor in the inclusion of a regular or high availability storage option if you're following this path. However, please take a moment to assess the associated costs before you proceed! 💼

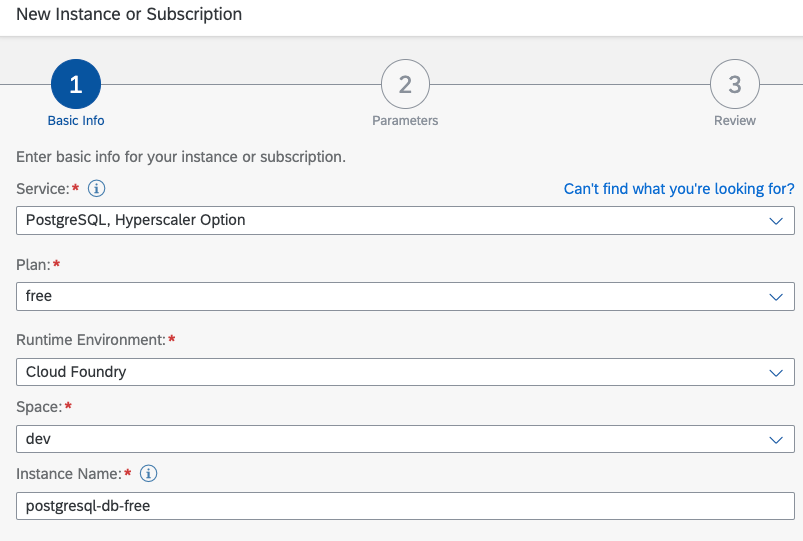
Now that entitlement is sorted, your subsequent task entails generating a service instance. Choose the free service plan to align with our sample scenario requirements. Should you find yourself navigating in the Kyma environment, be mindful to replicate this procedure there as well. However, within the Kyma context, please use the Advanced configuration tab, as its significance will become apparent in the subsequent step. 🛠️🔍
 Kyma |  Kyma |
Now, pay close attention to this step. It's of paramount importance to modify the engine_version to 13. This is crucial, especially on AWS like in our scenario, where the pgvector extension gains compatibility starting from version 13.
For those navigating the Kyma environment, remember to furnish the appropriate configuration within the Instance Parameters as a JSON string when initiating the service instance setup. This attention to detail will ensure seamless progress. 🛠️🧐
 Cloud Foundry | 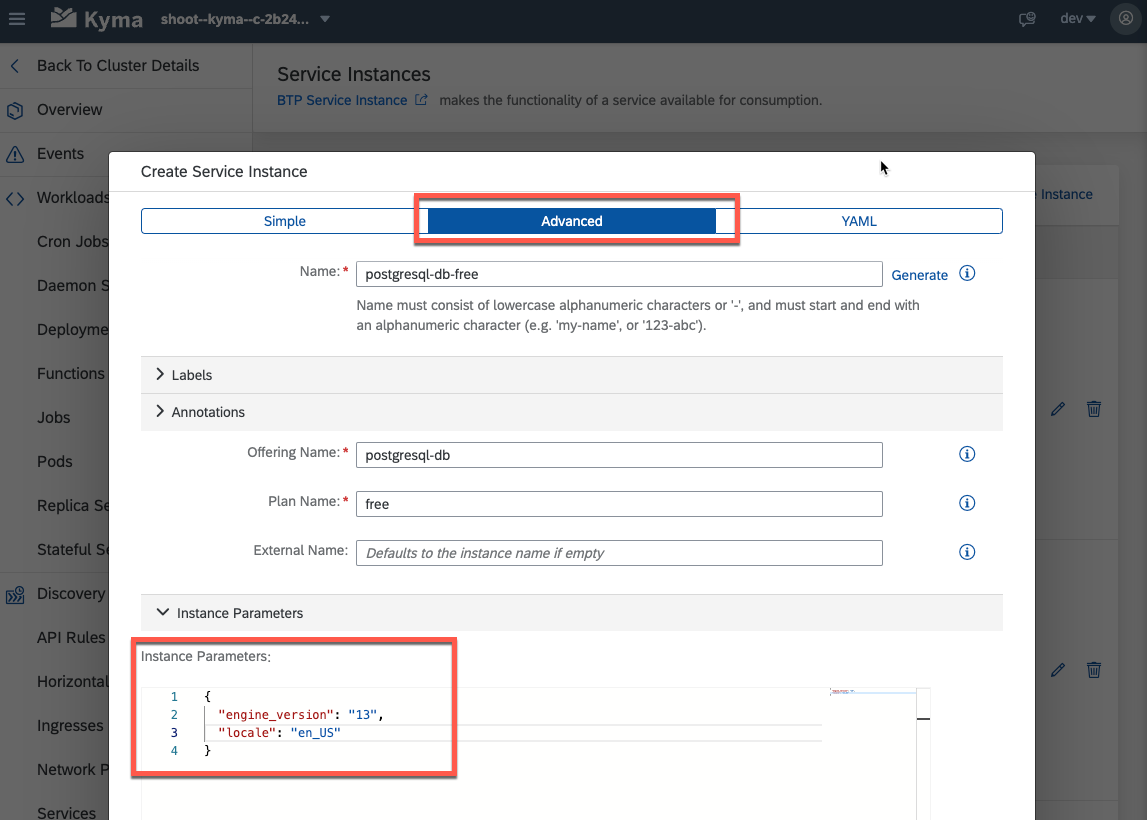 Kyma |
Following the successful deployment of the service instance, the next course of action involves generating a new Service Key. Alternatively, if you're working within the Kyma framework, the equivalent procedure would be to establish a Service Binding, resulting in the creation of a correspondingly named Secret. These client credentials hold significant importance, as they will play a crucial role in enabling the pgvector extension in the subsequent step. 🗝️🔐
 Cloud Foundry | 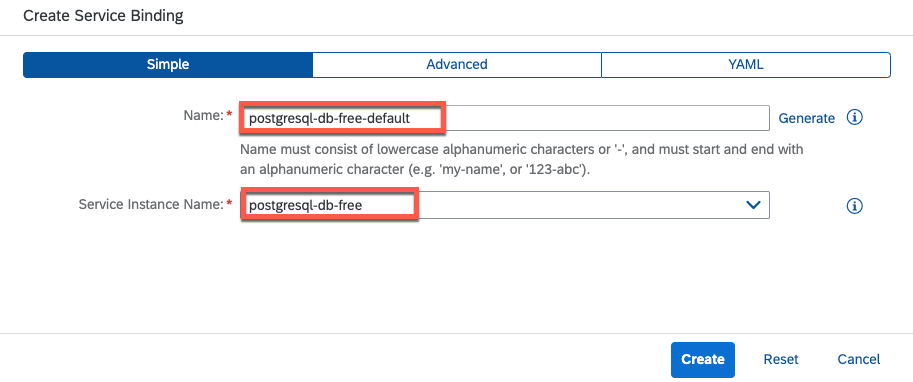 Kyma |
Enable the Extension
To enable the pgvector extension, your next course of action involves making use of the Extension API, an endpoint offered by the PostgreSQL on SAP BTP, Hyperscaler Option service. For comprehensive details, SAP Help provides an exhaustive documentation.
Using the ‘PostgreSQL, hyperscaler option’ Extension APIs
Using the ‘PostgreSQL, Hyperscaler Option’ Extension APIs for Kyma
In essence, you are required to invoke specific endpoints based on your runtime environment. The extension you wish to activate is integrated into the URL path. In order to enable the pgvector extension, ensure that the designated path culminates with "/extensions/vector" – and not "pgvector", as one might intuitively surmise.
With the basic idea set, let's delve into the operational aspect. We're about to explore how to invoke the endpoints for both a PostgreSQL instance in a Cloud Foundry and a Kyma environment. 🚀
Cloud Foundry
For Cloud Foundry, the Extension API endpoint to activate the pgvector extension is as follows:
https://api-backing-services.<CloudFoundryRegion>.data.services.cloud.sap/v1/postgresql-db/instances...Ensure to incorporate potential extension landscapes such as eu10-004 or us10-001 when indicating the Region. When employing curl, your HTTP call will resemble the following example (you can also add a schema value to your payload if required):
curl -X PUT 'https://api-backing-services.us10-001.data.services.cloud.sap/v1/postgresql-db/instances/5daa99f0-3f01-40e8-99e8-b175255046eb/extensions/vector' \
--header 'Authorization: bearer vxkxwymVFh' \
--header 'Content-Type: application/json' \
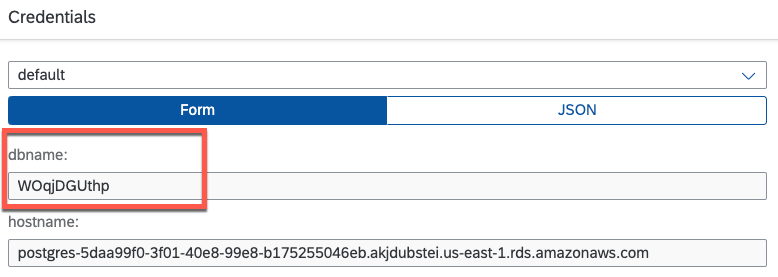
--data-raw '{"database": "WOqjDGUthp"}'You can retrieve the PostgreSQL Service Instance ID from the SAP BTP Cockpit, within the Service Instance details section. 📊
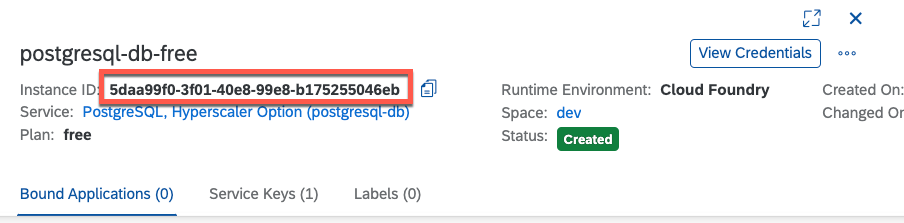
The database value that needs to be included in the JSON body of your request can be directly copied from your Client Credentials section within your Service Key. 🗄️
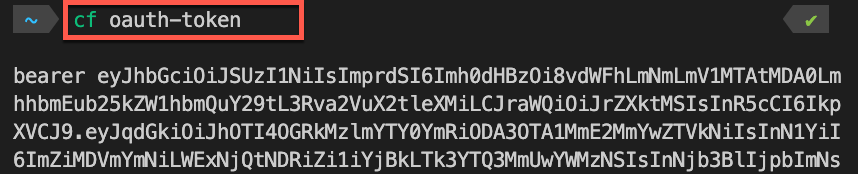
To obtain the required Authorization value, execute cf oauth-token from your local command line. Ensure you have the Cloud Foundry CLI installed and that you are authenticated to the Org and Space where your PostgreSQL service instance resides. Please note, your user account must hold Space Developer permissions at a minimum. 🛠️🔒
Kyma
For Kyma, the Extension API endpoint to activate the pgvector extension is as shown below:
https://api-backing-services-k8s.<KymaRegion>.data.services.cloud.sap/v1/postgresql-db/instances/<Po...In the context of Kyma, it's important to note that the appropriate Region should be the central region like eu10 or us10, as opposed to the extension regions as may be the case in Cloud Foundry. When utilizing curl, your HTTP call will resemble the following illustrative sample (you can also add a schema value to your payload if required):
curl -X PUT https://api-backing-services-k8s.us10.data.services.cloud.sap/v1/postgresql-db/instances/5daa99f0-3f01-40e8-99e8-b175255046eb/extensions/vector" \
--cert client-cert.pem \
--key client-key.pem \
--header 'Content-Type: application/json' \
--data-raw '{"database": "WOqjDGUthp"}'
In a similar vein, for Kyma, the PostgreSQL Service Instance ID and the database can be extracted directly from your Client Credentials within your Service Binding. 🗃️

In Kyma, an authentication method relying on certificates comes into play. The Client Certificate and Client Key essential for this purpose can be derived from the Service Binding (or respectively the associated generated Secret) you've crafted within Kyma. 📜🔑

Take the clientcert and clientkey values and create new files on your local device. It's crucial to ensure that you accurately reference these files within your curl command. To access the content, make sure you expand the Service Binding details from your Kyma Dashboard before copying. 📂🔍

With all the necessary components in place, it's time to execute the curl command from this directory. This action will trigger the enabling of the pgvector extension. 🚀🛠️
Test the extension
After successfully enabling the pgvector extension, you can validate its functionality through either of these methods:
- Cloud Foundry - Establish a connection to your PostgreSQL instance using an SSH tunnel (click here and click here for further details)
- Kyma - Include your current device's IP address within the allow_access instance parameter (click here for further details)
For a more comprehensive understanding of these scenarios, you can delve into the dedicated blog posts that cover each in detail. 🕵️♂️🌐
After setting up either the SSH tunnel or IP whitelisting, you'll be all set to utilize tools like the psql command line tool or other administration user interfaces such as PgAdmin. These will grant you access to connect with your PostgreSQL instance seamlessly. 🛠️🔌
SAP Cloud Foundry, SSH Tunnel
(! use localhost and port defined in cf ssh command!)
psql postgres://username:password@localhost:port/database
SAP Kyma, IP Whitelisting
(! use url and port from client credentials !)
psql postgres://username:password@url:port/database
Subsequently, you can proceed to execute the following SQL command. This will allow you to verify whether the (pg)vector extension has been effectively enabled on your database instance. Just check the list of extensions for the vector extension.
SELECT * FROM pg_extension;Taking the next step, you can create your first sample table tailored to store vectors. This can be achieved by executing the subsequent SQL commands. Should you seek more details, the official pgvector GitHub documentation stands as a valuable resource (click here).
CREATE TABLE items (id bigserial PRIMARY KEY, embedding vector(3));
INSERT INTO items (embedding) VALUES ('[1,2,3]'), ('[4,5,6]');To put the vector feature to the test, execute the following SQL command. This will prompt the retrieval of the nearest neighbor.
SELECT * FROM items ORDER BY embedding <-> '[3,1,2]' LIMIT 5;And there you have it! You've achieved the successful activation of the pgvector extension within your PostgreSQL on SAP BTP, Hyperscaler Option service instance. With this accomplished, you're now ready to seamlessly integrate it into your SAP BTP AI endeavors. 🎉🚀
Further information
For further information, please consult the following resources.
- SAP Help - PostgreSQL on SAP BTP, Hyperscaler Option
- SAP Community Blog Posts - PostgreSQL
- pgvector GitHub Repository
Conclusion
In conclusion, our journey led us to successfully enable the pgvector extension within SAP BTP's Hyperscaler Option for PostgreSQL. By navigating service instances, configuring extensions, and client credentials, we've unlocked the potential of pgvector. Armed with this setup, you're now ready to seamlessly integrate this extension into your SAP BTP AI projects, enriching your AI-driven scenarios.
Last but not least, a heartfelt acknowledgment goes out to my teammate kay_ and our exceptional colleagues from the PostgreSQL on SAP BTP, Hyperscaler Option team! Your contributions have been invaluable. 🙌🌟
Labels:
12 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,658 -
Business Trends
93 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
67 -
Expert
1 -
Expert Insights
177 -
Expert Insights
305 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
GraphQL
1 -
Kafka
1 -
Life at SAP
780 -
Life at SAP
13 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,576 -
Product Updates
348 -
Replication Flow
1 -
REST API
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,873 -
Technology Updates
434 -
Workload Fluctuations
1
Related Content
- IoT - Ultimate Data Cyber Security - with Enterprise Blockchain and SAP BTP 🚀 in Technology Blogs by Members
- Trustable AI thanks to - SAP AI Core & SAP HANA Cloud & SAP S/4HANA & Enterprise Blockchain 🚀 in Technology Blogs by Members
- PostgreSQL on SAP BTP, hyperscaler option - Credentials for db owner in Technology Q&A
- SAP Datasphere - Space, Data Integration, and Data Modeling Best Practices in Technology Blogs by SAP
- Redis on SAP BTP, Hyperscaler Option Now Available for Customers on BTP@China! in Technology Blogs by SAP
Top kudoed authors
| User | Count |
|---|---|
| 27 | |
| 19 | |
| 12 | |
| 11 | |
| 9 | |
| 9 | |
| 9 | |
| 8 | |
| 8 | |
| 7 |