
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- The fastest way to load data from HANA Cloud, HANA...
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
former_member22
Explorer
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
03-08-2022
9:23 PM
This is part of the HANA Data Strategy series of BLOGS
https://blogs.sap.com/2019/10/14/sap-hana-data-strategy/
Overview
Recently as customers are moving larger and larger tables from HANA into HANA Data Lake, I am being asked what the fastest way is to move data from HANA to HANA Data Lake. Or more precisely I am asked if there is a faster way then doing a simple HANA INSERT into a HANA Data Lake virtual table.
You may be asking why customers are moving large tables from HANA to HANA Data Lake (HDL) and the most popular use case for this is an initial materialization of a large datasets or archiving older data to HDL. Most of these customers are using HANA Smart Data Integration (SDI) to do this materialization and often using the same interface for change data capture using SDI Flowgraphs or SDI real-time replication to keep these tables up to date.
See these BLOGs for more detail on HANA SDI:
HANA Data Strategy: Data Ingestion including Real-Time Change Data Capture
https://blogs.sap.com/2020/06/18/hana-data-strategy-data-ingestion-including-real-time-change-data-c...
HANA Data Strategy: Data Ingestion – Virtualization
https://blogs.sap.com/2020/03/09/hana-data-strategy-data-ingestion-virtualization/
The three simple methods of moving data that we will examine here are:
- a simple HANA INSERT into a HDL virtual table,
- a simple HDL INSERT from HDL accessing a HANA virtual table, and
- a HANA export and HDL LOAD.
Now you might be asking:
“Why go through HANA?”
“Why not load the data directly into HDL?”
And again, these customers are using the HANA Enterprise Information Management tools which currently require a HANA object (local or virtual) as a target. In future BLOGs we’ll discuss loading data directly into HDL via IQ Client-Side Load, Data Services and Data Intelligence.
The fastest way to load data from HANA Cloud, HANA into HANA Cloud, HANA Data Lake is doing it from HDL/IQ and running an INSERT statement with a SELECT from a HANA table using the “create existing local temporary table” to create a proxy table pointing to the HANA physical table (see details below).
| Method | Rows | Data Size | Time - seconds |
| HDL/IQ INSERT..SELECT | 28,565,809 | 3.3 GB of data | 52.86 |
*HDL/IQ LOAD Azure File System | 28,565,809 | 3.3 GB of data | 116 (1m 56s) |
*HDL/IQ LOAD HDL File System | 28,565,809 | 3.3 GB of data | 510 (8m 30s) |
| HANA INSERT..SELECT | 28,565,809 | 3.3 GB of data | 1277 (21m 7s) |
* Does not include the time to export the data from HANA to the file system
Using a TPC-D ORDERS table with 28,565,809 rows which is about 3.3 GB of data. Loading a small HDL configuration.
This was tested using this HANA Cloud configuration:
HANA 60GB/200GB 4 vCPU
HDL 16TB 8vCPU worker/8vCPU coordinator
In an HDL configuration more vCPUs would have allowed this to run more parallel (especially on wider tables) and by adding more TBs HDL will acquire more disk i/o throughput.
Detail configuration notes and syntax used for testing
Start Hana Cockpit to Manage SAP HANA Cloud
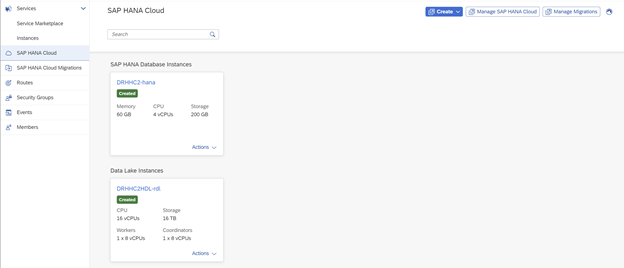
From Data Lake … choose Open in SAP HANA Database Explorer
You maybe prompted for your HDLADMIN password if this is the first time going here.

Enter SQL command and click to execute

HDL commands for creating:
- a server connecting to HANA Cloud from HDL,
- a local HDL table to load the data into and creating
- a local temporary proxy table pointing to the table in the HANA Cloud instance
CREATE SERVER
--DROP SERVER DRHHC2_HDB
CREATE SERVER DRHHC2_HDB CLASS 'HANAODBC' USING 'Driver=libodbcHDB.so;ConnectTimeout=60000;ServerNode=XXXX.hana.prod-us10.hanacloud.ondemand.com:443;ENCRYPT=TRUE;ssltruststore=XXXX.hana.prod-us10.hanacloud.ondemand.com;ssltrustcert=Yes;UID=DBADMIN;PWD=XXXXX;'
CREATE TARGET TABLE
CREATE TABLE REGIONPULL (
R_REGIONKEY bigint not null,
R_NAME varchar(25) not null,
R_COMMENT varchar(152) not null,
primary key (R_REGIONKEY)
);
CREATE local temporary PROXY
create existing local temporary table REGION_PROXY (
R_REGIONKEY bigint not null,
R_NAME varchar(25) not null,
R_COMMENT varchar(152) not null,
primary key (R_REGIONKEY)
)
at 'DRHHC2_HDB..TPCD.REGION';
INSERT DATA
INSERT into REGIONPULL SELECT * from REGION_PROXY;
Commit;
--1.9s
ORDERS table test commands
--DROP TABLE ORDERSPULL;
create table ORDERSPULL (
O_ORDERKEY BIGINT not null,
O_CUSTKEY BIGINT not null,
O_ORDERSTATUS VARCHAR(1) not null,
O_TOTALPRICE DECIMAL(12,2) not null,
O_ORDERDATE DATE not null,
O_ORDERPRIORITY VARCHAR(15) not null,
O_CLERK VARCHAR(15) not null,
O_SHIPPRIORITY INTEGER not null,
O_COMMENT VARCHAR(79) not null,
primary key (O_ORDERKEY)
);
create existing local temporary table ORDERS_PROXY (
O_ORDERKEY BIGINT not null,
O_CUSTKEY BIGINT not null,
O_ORDERSTATUS VARCHAR(1) not null,
O_TOTALPRICE DECIMAL(12,2) not null,
O_ORDERDATE DATE not null,
O_ORDERPRIORITY VARCHAR(15) not null,
O_CLERK VARCHAR(15) not null,
O_SHIPPRIORITY INTEGER not null,
O_COMMENT VARCHAR(79) not null
)
at 'DRHHC2_HDB..TPCD.ORDERS';
INSERT into ORDERSPULL SELECT * from ORDERS_PROXY;
Commit;
--59s
--52.86 s
SELECT COUNT(*) FROM ORDERSPULL;
--28,565,809
LINEITEM table test commands
create table LINEITEM (
L_ORDERKEY BIGINT not null,
L_PARTKEY BIGINT not null,
L_SUPPKEY BIGINT not null,
L_LINENUMBER INTEGER not null,
L_QUANTITY DECIMAL(12,2) not null,
L_EXTENDEDPRICE DECIMAL(12,2) not null,
L_DISCOUNT DECIMAL(12,2) not null,
L_TAX DECIMAL(12,2) not null,
L_RETURNFLAG VARCHAR(1) not null,
L_LINESTATUS VARCHAR(1) not null,
L_SHIPDATE DATE not null,
L_COMMITDATE DATE not null,
L_RECEIPTDATE DATE not null,
L_SHIPINSTRUCT VARCHAR(25) not null,
L_SHIPMODE VARCHAR(10) not null,
L_COMMENT VARCHAR(44) not null,
primary key (L_ORDERKEY,L_LINENUMBER)
);
create existing local temporary table LINEITEM_PROXY (
L_ORDERKEY BIGINT not null,
L_PARTKEY BIGINT not null,
L_SUPPKEY BIGINT not null,
L_LINENUMBER INTEGER not null,
L_QUANTITY DECIMAL(12,2) not null,
L_EXTENDEDPRICE DECIMAL(12,2) not null,
L_DISCOUNT DECIMAL(12,2) not null,
L_TAX DECIMAL(12,2) not null,
L_RETURNFLAG VARCHAR(1) not null,
L_LINESTATUS VARCHAR(1) not null,
L_SHIPDATE DATE not null,
L_COMMITDATE DATE not null,
L_RECEIPTDATE DATE not null,
L_SHIPINSTRUCT VARCHAR(25) not null,
L_SHIPMODE VARCHAR(10) not null,
L_COMMENT VARCHAR(44) not null
)
at 'DRHHC2_HDB..TPCD.LINEITEM';
INSERT into LINEITEM SELECT * from LINEITEM_PROXY;
Commit;
-- Rows affected: 114,129,863
-- Client elapsed time: 4 m 52 s
In Conclusion
The fastest way to load data from HANA Cloud, HANA into HANA Cloud, HANA Data Lake is doing it from HDL/IQ and running an INSERT statement with a SELECT from a HANA table using the “create existing local temporary table” to create a proxy table pointing to the HANA physical table. This can be very easily done using the commands listed in this blog or even easier by creating a procedure that will generate these commands (see Daniel’s BLOG below).
Also see:
Jason Hansberger’s Loading Data into SAP HANA Cloud, Data Lake BLOG goes into detail on how raising HDL vCPUs and database size effects load performance:
https://blogs.sap.com/2020/11/23/loading-data-into-sap-hana-cloud-data-lake/
Daniel Utvich’s Move data FAST from an SAP HANA Cloud database to a HANA Data Lake BLOG, has an example of a procedure that will generate this SQL code for you based on system table information:
https://blogs.sap.com/2022/01/14/move-data-fast-from-an-sap-hana-cloud-database-to-a-hana-data-lake/
SAP HANA Data Strategy BLOGs Index
- SAP Managed Tags:
- SAP Datasphere,
- SAP HANA Cloud,
- SAP HANA Cloud, SAP HANA database,
- SAP HANA,
- Big Data,
- SAP HANA Cloud, data lake
Labels:
9 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,658 -
Business Trends
110 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
74 -
Expert
1 -
Expert Insights
177 -
Expert Insights
348 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
GraphQL
1 -
Kafka
1 -
Life at SAP
780 -
Life at SAP
14 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,575 -
Product Updates
391 -
Replication Flow
1 -
REST API
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,871 -
Technology Updates
482 -
Workload Fluctuations
1
Related Content
- Integrating SAP S/4HANA with Kafka via SAP Advanced Event Mesh: Part1 – Outbound connection in Technology Blogs by Members
- VD51 in sap public cloud in Technology Q&A
- Unleashing the Power of Custom Widgets in SAP Analytics Cloud in Technology Blogs by Members
- Deployment from BAS to SAP S/4HANA Public cloud dev tenant in Technology Q&A
- RingFencing & DeCoupling S/4HANA with Enterprise Blockchain and SAP BTP - Ultimate Cyber Security 🚀 in Technology Blogs by Members
Top kudoed authors
| User | Count |
|---|---|
| 15 | |
| 11 | |
| 10 | |
| 10 | |
| 9 | |
| 8 | |
| 7 | |
| 7 | |
| 7 | |
| 7 |