- SAP Community
- Products and Technology
- Technology
- Technology Q&A
- DOX - Detect Automatically at Document load time
- Subscribe to RSS Feed
- Mark Question as New
- Mark Question as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
DOX - Detect Automatically at Document load time
- Subscribe to RSS Feed
- Mark Question as New
- Mark Question as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
on 07-20-2023 11:52 AM
G'day all,
I believe I understand the nature of "Detect Automatically" when using the "Extract Data (Template)" step. You have multiple templates and some logic determines which will give the best result (I kinda think of DB indexes here - I worry that too many will confused the engine).

What I don't understand and haven't seen reference to is what does "Detect Automatically" mean when you Upload a new Document?
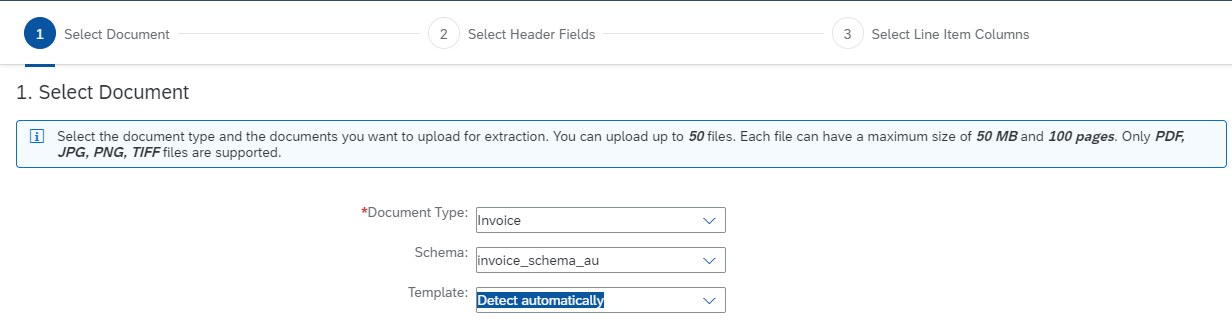
What does this mean? Is the Document itself now considered a Template? How is this document considered in the over all logic?
This screen says you can have 50 files. I'd assumed that was per Template. The doco on Tech Constraints doesn't mention this 50 file restriction.

I'd initally thought it was 50 files in each template. The numbers get big. 1000 schemas with a 1000 templates each with 50 files... 50,000,000 files loaded potentially?
But again, what does it all mean if you select "Detect Automatically" at the Document level.
Any and all advice appreciated.
Have fun,
Mark
{kind=link}
{kind=link}
{kind=link}
- SAP Managed Tags:
- Document Information Extraction,
- SAP Build Process Automation
Accepted Solutions (1)
Accepted Solutions (1)
- Mark as New
- Bookmark
- Subscribe
- Subscribe to RSS Feed
- Report Inappropriate Content
Hi Mark,
Is the "50 Docs" just about how many you can upload simultaneoulsy or is it how many Docs you can use to Train a Template?
It's about how many documents you can upload in one go through the UI. We can process more documents simultaneoulsy if you upload them through the API. For training a template, one document per template (layout) is sufficient.
What happens if I upload a Document with "Detect Automatically" and either I don't have any Templates defined, or there is no similiar Templates... does it generate a new Template?
Even if I have 3 Templates what happens if the new Doc doesn't fit well? Does is it generate a Template?
If no matching tempalte is found, the template extraction is skipped and the system falls back to the default extractors you defined in your schema. If you didn't define any default extractor, then the results will remain empty. After correcting the extraction results, you can createa a new template through the UI for this unknown layout (there is a button in the document screen for this). That way you can extend the list of templates for a schema over time.
Assuming it finds a suitable Template, does it tell you which has been chosen?
Yes, you can see the template that got used both in the API response as well as in the document screen on top of the image of the document.
Given the 1000 Templates per Schema is it expected that it's a Template per Vendor? And if not, how do you know which Docs should be loaded against which Template, or do you trust the "Detect Automatically"? I don't see how it makes much sense if it doesn't auto-generate a new Template when it's not happy.
That depends on your scenario, you can use templates to improve accuracy for some vendors, while you rely on our pretrained models for the remaining vendors. In this case you only need to create templates for few selected vendors.
In the scenario you describe, where you want to extend the list of fields, you would need to create a template per vendor. As described above, you can create templates over time through the UI, whenever you upload a document for which no template was found, you can create a new one through the UI.
The "Detect automatically" functionality is designed to be very robust so that it can be trusted.
Best regards,
Tobias
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Answers (1)
Answers (1)
- Mark as New
- Bookmark
- Subscribe
- Subscribe to RSS Feed
- Report Inappropriate Content
Hi Mark,
The 50 document limit is purely for the upload screen in the UI to not overload the UI. You can upload significantly more documents in parallel through the API or by uploading multiple batches of 50 documents through the UI.Autodetect means, that we analyze each uploaded document and check if their is a template of similar layout within the set of active templates that belong to the selected schema. And this functionality is limited to 1,000 templates per schema since we want to make sure to have an extremely high accuracy in the template detection part.
Since autodetect always refers to one schema, we only need to load and analyze the max. 1,000 active templates belonging to this schema and not all templates in the system.
Let's assume you have the following:
Schema1- Template1A
- Template1B
- Template1C
- Template2A
- Template2B
When you upload a document and select schema1, templates 1A, 1B and 1C are being analyzed. If you select schema2, templates 2A and 2B are being analyzed.
Hope this helps to understand the functionality better.
Best regards,
Tobias
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
- Mark as New
- Bookmark
- Subscribe
- Subscribe to RSS Feed
- Report Inappropriate Content
G'day Tobias,
Thanks for the reply, but still not quite clear.
Is the "50 Docs" just about how many you can upload simultaneoulsy or is it how many Docs you can use to Train a Template?
What happens if I upload a Document with "Detect Automatically" and either I don't have any Templates defined, or there is no similiar Templates... does it generate a new Template?
Even if I have 3 Templates what happens if the new Doc doesn't fit well? Does is it generate a Template?
Assuming it finds a suitable Template, does it tell you which has been chosen?
I do have another question open - https://answers.sap.com/questions/13926530/dox-process-of-training-an-extended-invoice-schema.html
Given the 1000 Templates per Schema is it expected that it's a Template per Vendor? And if not, how do you know which Docs should be loaded against which Template, or do you trust the "Detect Automatically"? I don't see how it makes much sense if it doesn't auto-generate a new Template when it's not happy.
Really appreciate any insights.
Have fun,
Mark
- SAP BTP FAQs - Part 3 (Security) in Technology Blogs by SAP
- Business AI for Aerospace, Defense and Complex Manufacturing in Technology Blogs by SAP
- Deep dive: End-to-End processes with a closer look on Source to Pay in Technology Blogs by SAP
- First steps to work with SAP Cloud ALM Deployment scenario for SAP ABAP systems (7.40 or higher) in Technology Blogs by SAP
- SAP Cloud ALM: Requirements Management on Steroids in Technology Blogs by SAP
| User | Count |
|---|---|
| 76 | |
| 9 | |
| 8 | |
| 7 | |
| 6 | |
| 5 | |
| 5 | |
| 5 | |
| 5 | |
| 4 |
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.