
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- Exposing Calculation View with Dynamic Client via ...
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Product and Topic Expert
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
10-04-2023
10:26 AM
I recently was involved in a BTP project where one of the use cases evolved around exposing a HANA Cloud calculation view via an OData API. The calculation view was developed in Business Application Studio (BAS) and deployed to an HDI container, which is the best practice when it comes to developing HANA native artifacts for HANA Cloud. To expose this calculation view via an API, the best approach is to add a Cloud Application Programming (CAP) service layer.
Multiple blogs and tutorials have been written about combining or consuming HANA Native artifacts in a CAP service layer, which you can refer to for practical information:
For our project, just exposing the calculation view itself was not enough: the calculation view is consuming data from an ECC system with multiple clients. This (ECC) client number is different for development, test or production deployments so the calculation view needs to know the correct client. Calculation views support this via the 'Default Client' feature (see SAP Help Documentation) and by specifying a column of the table to filter on. To keep the client value dynamic, the calculation view will rely on the session context.
With calculation views configured to use the Session Client, the client value will be taken from the
Two solutions are discussed below:
The solution described in this section consists of 4 main steps:
The HANA Cloud database has to be configured to allow the granting of user altering privileges for configuring the runtime users. Runtime users are part of the
Note: To remove this configuration again, you can simply revoke the
The HDI container contains your calculation view, but we need to add a few elements to make sure the owner of the HDI (#OO user) is able to set the correct client for the runtime user (RT user).
In the HDI container, we need the following new artifacts:
The grants file will assign the
HDI_GRANTS_Client.hdbgrants:
The stored procedure is configured to execute statements using the
SET_CLIENT.hdbprocedure:
The stored procedure relies on the
SYS_DUMMY.hdbsynonym:
This is an optional table which will have a record inserted for every change in client value, just for logging/monitoring purposes.
LOG_TABLE.hdbtable:
The calculation view will be consumed by a CAP service layer to expose it via an OData API endpoint, while using the correct client value. To enable this, we need to create:
This is the standard approach to exposing a calculation view in CAP, and the above-mentioned tutorial goes into more depth on this topic. For now, it's important to understand that we need a proxy entity in the schema, and a service pointing to the already-existing calculation view.
To generate the proxy entity, you can always use the
Schema.cds:
Service.cds:
With this configuration, the CAP service understands there is an existing view named "CALCVIEWS_SAPDATA", providing an output corresponding to the schema entity.
The CAP framework emits specific events during its application startup routine, which we can listen and react to (See Capire Bootstrapping Servers documentation). Once the database connection details have been retrieved (together with some other things) it emits the
The below code snippet will verify that the application is connected to HANA Cloud, retrieve the current RT user from the bindings, and get the configured client value from an environment variable (defined later). With this information, it executes the stored procedure to store this client value for the user.
Server.js:
In the Multi-Target Application (MTA) Deployment Descriptor (mta.yaml) we specify an empty placeholder for a
We also need to define the
mta.yaml (truncated):
The user provided service refers to the below configuration file containing the
HDI_GRANTS_Client.json:
With this configuration, the entire project can be compiled/built generically, leaving the client value as a parameter set during the deployment phase.
The extension descriptor is a simple ".mtaext" file which defines the value of the environment variable. You can create as many extension files as you need different configurations.
As an example, the below extension defines value 200 for the
mta_client200.mtaext:
To finalize this approach, see Step 4: Deploy to BTP Landscape below.
The solution described in this section is a simplification of the first solution. Exploring this alternative was mainly driven by the fact that the first solution requires using the
This solution consists of 2 main steps:
The calculation view will be consumed by a CAP service layer to expose it via an OData API endpoint, while using the correct client value. To enable this, we need to create:
See solution 1 above.
The CAP framework emits specific events during its application startup routine, which we can listen and react to (See Capire Bootstrapping Servers documentation). Once the database connection details have been retrieved (together with some other things) it emits the
The below code snippet will verify that the application is connected to HANA Cloud and retrieve the configured client value from an environment variable (defined later). It will add two new properties to the standard HDI Service Instance binding to define the CLIENT value for this database session.
Specifying the
Server.js:
In the Multi-Target Application (MTA) Deployment Descriptor (mta.yaml) we specify an empty placeholder for a
There is no need for any grants we had in the first solution.
mta.yaml (truncated):
With this configuration, the entire project can be compiled/built generically, leaving the client value as a parameter set during the deployment phase.
See solution 1 above.
The first step is to build the project from source code and package it in a deployable artifact (MTAR), using the below CLI commands. This can be done independently of choosing a client value. This deployable artifact can be used in your CI-CD pipeline.
The output will be a file like
Once built, your project can now be deployed to different BTP landscapes (development, test, production) by specifying the corresponding extension file via the
Deployed using the mta_client200.mtaext file, you will see the following result:
This blog explored the scenario where a calculation view requires a client value to respond correctly, and where this client value has to remain dynamic up until the project deployment step. Staying within the HDI and CAP frameworks, we looked at an approach of using the HDI object owner to change the user parameter of the runtime user based on a value given by the CAP service layer, as well as an approach to set the client value for the database session.
Please share your thoughts about this approach in the comments below. There might be some potential alternative approaches so I'd love to continue the conversation below.
Git Repository: A sample project containing all artifacts can be found here: SAP BTP Global CoE Samples.
Multiple blogs and tutorials have been written about combining or consuming HANA Native artifacts in a CAP service layer, which you can refer to for practical information:
- Tutorial about consuming Calculation Views: Create Calculation View and Expose via CAP (SAP HANA Cloud)
- Blog about calling Stored Procedures: How to create an API to run a HANA Cloud Stored Procedure in Cloud Foundry
For our project, just exposing the calculation view itself was not enough: the calculation view is consuming data from an ECC system with multiple clients. This (ECC) client number is different for development, test or production deployments so the calculation view needs to know the correct client. Calculation views support this via the 'Default Client' feature (see SAP Help Documentation) and by specifying a column of the table to filter on. To keep the client value dynamic, the calculation view will rely on the session context.
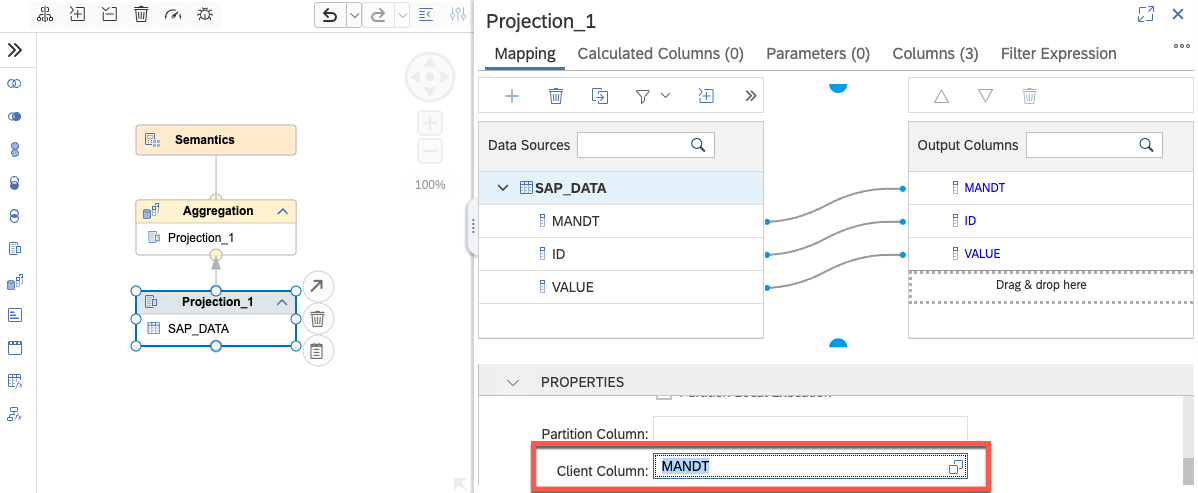
Sample calculation view using the MANDT column for client-based filtering (CALCVIEWS_SAPDATA.hdbcalculationview)
Challenge
With calculation views configured to use the Session Client, the client value will be taken from the
'client' user parameter of the user querying the calculation view, or from a value set for the database session. In an HDI deployment, this user would typically be a runtime user (RT user) which is automatically generated and as such doesn't have a client user parameter set by default. We need to be able to set the client user parameter for the RT user based on the landscape the solution is deployed to. (See: How to set user parameters in HANA Cloud)Solutions
Two solutions are discussed below:
- A theoretical approach, rather complex but solid, suitable for SAP HANA Cloud only.
- A much simpler, practical approach, suitable for both SAP HANA Cloud and SAP Datasphere.
Solution 1
The solution described in this section consists of 4 main steps:
- HANA Cloud configuration:
We need to enable HANA Cloud to give privileges to HDI object owners (#OO users) to set the client user parameter for their runtime users (RT users). - New HDI artifacts:
We need to create a grant and a stored procedure to set the client user parameter for the active runtime user via theALTER USERstatement. - CAP service layer:
The CAP service which will consume and expose the calculation view as an OData API needs to call the stored procedure with the target client value configured during deployment. - Deploy to BTP landscape:
Build generically, but deploy the project to BTP with a specific client value.

Solution Overview (option 1)
Step 1: HANA Cloud configuration
The HANA Cloud database has to be configured to allow the granting of user altering privileges for configuring the runtime users. Runtime users are part of the
HDISHARED User Group. In order to limit the use of the DBADMIN user for any operational tasks, we create a separate user (UG_GRANTOR_USER) with the privilege to assign the user altering privileges to HDI object owner users. This user altering privilege will be assigned via a new role: UG_GRANTOR_ROLE. Any user receiving this role will be able to alter HDI runtime users.-- Run these statements with the DBADMIN user
-- Allow DBADMIN to grant Usergroup Operater privileges to a user:
CALL "SYSTEM".GRANT_USERGROUP_OPERATOR('BROKER_UG_HDISHARED');
-- Create a role which will contain the privilege to alter users:
CREATE ROLE UG_GRANTOR_ROLE NO GRANT TO CREATOR;
GRANT USERGROUP OPERATOR ON USERGROUP BROKER_UG_HDISHARED TO UG_GRANTOR_ROLE WITH GRANT OPTION;
-- Create user UG_GRANTOR_USER who will be allowed to grant the new role to other users:
CREATE USER UG_GRANTOR_USER PASSWORD "YourSecretPassword" SET USERGROUP DEFAULT;
ALTER USER UG_GRANTOR_USER disable PASSWORD lifetime;
-- Grant new role to UG_GRANTOR_USER with option to grant to others (which will be #OO users):
GRANT UG_GRANTOR_ROLE TO UG_GRANTOR_USER WITH ADMIN option;Note: To remove this configuration again, you can simply revoke the
Usergroup Operator privileges which will cascade down and disable any ALTER USER statements going forward.-- Disable the granting and revoke privileges of the UG_GRANTOR_USER and all #OO users:
CALL "SYSTEM".REVOKE_USERGROUP_OPERATOR('BROKER_UG_HDISHARED');
-- Delete the role/user (clean-up)
DROP ROLE UG_GRANTOR_ROLE;
DROP USER UG_GRANTOR_USER;Step 2: New HDI Artifacts
The HDI container contains your calculation view, but we need to add a few elements to make sure the owner of the HDI (#OO user) is able to set the correct client for the runtime user (RT user).
In the HDI container, we need the following new artifacts:
- HDI_GRANTS_Client.hdbgrants: A grants file to assign our role to the HDI object owner.
- SET_CLIENT.hdbprocedure: A stored procedure to look up the current session user and set its client value.
- LOG_TABLE.hdbtable (optional): A logging table to record changes in client value.
Grants
The grants file will assign the
UG_GRANTOR_ROLE role to the HDI object owner (#OO user), as well as provide access to the SYS.DUMMY table which will be used in the stored procedure to determine the current session user.HDI_GRANTS_Client.hdbgrants:
{
"HDI_GRANTS_Client": {
"object_owner": {
"object_privileges": [
{
"schema": "SYS",
"name": "DUMMY",
"privileges": [ "SELECT" ]
}
],
"roles": [
{
"roles": [ "UG_GRANTOR_ROLE" ]
}
]
}
}
}
Stored Procedure
The stored procedure is configured to execute statements using the
DEFINER privileges, which is the HDI object owner (#OO user). It will retrieve the current SESSION_USER (the RT user) and set its 'CLIENT' user parameter. An entry is written to the log table as well for monitoring purposes (optional).SET_CLIENT.hdbprocedure:
PROCEDURE "SET_CLIENT" (IN client NVARCHAR(3))
LANGUAGE SQLSCRIPT
SQL SECURITY DEFINER
AS BEGIN
DECLARE result NVARCHAR(1000);
DECLARE su NVARCHAR(255);
DECLARE EXIT HANDLER FOR SQLEXCEPTION
BEGIN
ROLLBACK;
SELECT ::SQL_ERROR_MESSAGE INTO result FROM SYS_DUMMY;
INSERT INTO LOG_TABLE ("CLIENT", "RESULT") VALUES (:client, :result);
COMMIT;
RESIGNAL;
END;
SELECT session_user INTO su FROM SYS_DUMMY;
EXEC 'ALTER USER ' || :su || ' SET PARAMETER "CLIENT"=''' || :client || '''';
INSERT INTO LOG_TABLE ("CLIENT", "RESULT") VALUES (:client, 'Success');
END;
The stored procedure relies on the
SYS.DUMMY table from the HANA database, which is accessed via the SYS_DUMMY synonym.SYS_DUMMY.hdbsynonym:
{
"SYS_DUMMY": {
"target": {
"object": "DUMMY",
"schema": "SYS"
}
}
}
Logging Table
This is an optional table which will have a record inserted for every change in client value, just for logging/monitoring purposes.
LOG_TABLE.hdbtable:
COLUMN TABLE LOG_TABLE (
TIME TIMESTAMP default CURRENT_TIMESTAMP,
EXECUTER NVARCHAR(255) default CURRENT_USER,
SUBJECT NVARCHAR(255) default SESSION_USER,
CLIENT NVARCHAR(3),
RESULT NVARCHAR(1000)
);Step 3: CAP Consumption layer
The calculation view will be consumed by a CAP service layer to expose it via an OData API endpoint, while using the correct client value. To enable this, we need to create:
- Schema and Service: Enable API access to the calculation view.
- Server: Call the stored procedure during application startup.
- MTA Deployment Descriptor: Create an environment variable to hold the target client value and a user provided service for the grants.
- MTA Deployment Extension Descriptor: The final configuration, used during deployment, specifying the client value.
Schema and Service
This is the standard approach to exposing a calculation view in CAP, and the above-mentioned tutorial goes into more depth on this topic. For now, it's important to understand that we need a proxy entity in the schema, and a service pointing to the already-existing calculation view.
To generate the proxy entity, you can always use the
inspectView HANA CLI command to retrieve the data model.Schema.cds:
namespace SAP;
@cds.persistence.exists
@cds.persistence.calcview
entity DATA {
key MANDT : String(3);
key ID : Integer;
VALUE : Integer;
};
Service.cds:
using { SAP } from '../db/schema';
service CALCVIEWS {
@cds.persistence.exists
entity SAPDATA as projection on SAP.DATA;
};With this configuration, the CAP service understands there is an existing view named "CALCVIEWS_SAPDATA", providing an output corresponding to the schema entity.
Server
The CAP framework emits specific events during its application startup routine, which we can listen and react to (See Capire Bootstrapping Servers documentation). Once the database connection details have been retrieved (together with some other things) it emits the
served event, so that's the signal for us that we can start to execute database queries. It's important to name this file "server.js" so it is picked up automatically.The below code snippet will verify that the application is connected to HANA Cloud, retrieve the current RT user from the bindings, and get the configured client value from an environment variable (defined later). With this information, it executes the stored procedure to store this client value for the user.
Server.js:
const cds = require('@sap/cds');
cds.once('served', () => {
const client = process.env?.sap_client || null,
user = cds.db?.options?.credentials?.user || null,
dbkind = cds.db?.kind || null;
if (user && client && dbkind == 'hana') {
cds.db.run(`CALL SET_CLIENT(client => '${client}')`)
.then(() => console.log(`Set client ${client} for user ${user} successfully.`))
.catch(error => console.error(`ERROR: Could not set client ${client} for user ${user}. ${error}`));
} else {
console.log(`Project is not configured to set client [user: ${user}, client: ${client}, db: ${dbkind}].`);
}
});MTA Deployment Descriptor
In the Multi-Target Application (MTA) Deployment Descriptor (mta.yaml) we specify an empty placeholder for a
sap_client environment variable for the "srv" application. This variable will be filled with the correct value from the MTA Deployment Extension Descriptor (defined later).We also need to define the
User Provided Service that contains the credentials of the UG_GRANTOR_USER user which is used in the HDI_GRANTS_Client.hdbgrants file. This is relevant to the "db-deployer" application which will deploy the HDI artifacts.mta.yaml (truncated):
modules:
- name: calcview_client-srv
type: nodejs
path: gen/srv
deployed-after: [ calcview_client-db-deployer ] # otherwise the app could possibly start before the db is ready
properties:
sap_client: '' # empty value when no mta-ext is used
parameters:
buildpack: nodejs_buildpack
...
- name: calcview_client-db-deployer
type: hdb
path: gen/db
parameters:
buildpack: nodejs_buildpack
requires:
- name: calcview_client-db
- name: HDI_GRANTS_Client
...
resources
- name: HDI_GRANTS_Client
type: org.cloudfoundry.user-provided-service
parameters:
path: ./HDI_GRANTS_Client.json
...
The user provided service refers to the below configuration file containing the
UG_GRANTOR_USER credentials.HDI_GRANTS_Client.json:
{
"user": "UG_GRANTOR_USER",
"password": "YourSecretPassword",
"tags": [ "password" ]
}
With this configuration, the entire project can be compiled/built generically, leaving the client value as a parameter set during the deployment phase.
MTA Deployment Extension Descriptor
The extension descriptor is a simple ".mtaext" file which defines the value of the environment variable. You can create as many extension files as you need different configurations.
As an example, the below extension defines value 200 for the
sap_client variable.mta_client200.mtaext:
_schema-version: '3.1'
ID: calcview_client_client200
extends: calcview_client
modules:
- name: calcview_client-srv
properties:
sap_client: '200'
To finalize this approach, see Step 4: Deploy to BTP Landscape below.
Solution 2
The solution described in this section is a simplification of the first solution. Exploring this alternative was mainly driven by the fact that the first solution requires using the
DBADMIN user which is not available in SAP Datasphere.This solution consists of 2 main steps:
- (not needed)
- (not needed)
- CAP service layer:
The CAP service which will consume and expose the calculation view as an OData API needs to define the client value for the database connection, regardless of the used RT user. - Deploy to BTP landscape:
Build generically, but deploy the project to BTP with a specific client value.

Solution Overview (option 2)
Step 3: CAP Consumption Layer
The calculation view will be consumed by a CAP service layer to expose it via an OData API endpoint, while using the correct client value. To enable this, we need to create:
- Schema and Service: Same as solution 1.
- Server: Call the stored procedure during application startup.
- MTA Deployment Descriptor: Create an environment variable to hold the target client value.
- MTA Deployment Extension Descriptor: Same as solution 1.
Schema and Service
See solution 1 above.
Server
The CAP framework emits specific events during its application startup routine, which we can listen and react to (See Capire Bootstrapping Servers documentation). Once the database connection details have been retrieved (together with some other things) it emits the
served event, so that's the signal for us to extend these connection details with the correct client setting. It's important to name this file "server.js" so it is picked up automatically.The below code snippet will verify that the application is connected to HANA Cloud and retrieve the configured client value from an environment variable (defined later). It will add two new properties to the standard HDI Service Instance binding to define the CLIENT value for this database session.
Specifying the
databaseName is required for the SESSIONVARIABLE to be picked up correctly. If omitted, the variable value gets lost in connection redirects/reconnects.Server.js:
const cds = require('@sap/cds');
cds.once('served', () => {
const client = process.env?.sap_client || null;
const dbkind = cds.db?.kind || null;
if (client && dbkind == 'hana' && cds.db?.options?.credentials) {
cds.db.options.credentials['databaseName'] = 'H00';
cds.db.options.credentials['SESSIONVARIABLE:CLIENT'] = client;
console.log(`Set client ${client} for database session successfully.`);
} else {
console.log(`Project is not configured to set client [client: ${client}, db: ${dbkind}].`);
}
});
MTA Deployment Descriptor
In the Multi-Target Application (MTA) Deployment Descriptor (mta.yaml) we specify an empty placeholder for a
sap_client environment variable for the "srv" application. This variable will be filled with the correct value from the MTA Deployment Extension Descriptor (defined later).There is no need for any grants we had in the first solution.
mta.yaml (truncated):
modules:
- name: calcview_client-srv
type: nodejs
path: gen/srv
properties:
sap_client: '' # empty value when no mta-ext is used
parameters:
buildpack: nodejs_buildpack
...With this configuration, the entire project can be compiled/built generically, leaving the client value as a parameter set during the deployment phase.
MTA Deployment Extension Descriptor
See solution 1 above.
Step 4: Deploy to BTP Landscape (same for Solution 1 and 2)
The first step is to build the project from source code and package it in a deployable artifact (MTAR), using the below CLI commands. This can be done independently of choosing a client value. This deployable artifact can be used in your CI-CD pipeline.
# create the deployable artifact
npm install
mbt buildThe output will be a file like
./mta_archives/calcview_client_1.0.0.mtar.Once built, your project can now be deployed to different BTP landscapes (development, test, production) by specifying the corresponding extension file via the
-e flag:# deploy for client 100
cf deploy ./mta_archives/calcview_client_1.0.0.mtar -e mta_client100.mtaext
# deploy for client 200
cf deploy ./mta_archives/calcview_client_1.0.0.mtar -e mta_client200.mtaext
# deploy for client 300
cf deploy ./mta_archives/calcview_client_1.0.0.mtar -e mta_client300.mtaext
Outcome
Deployed using the mta_client200.mtaext file, you will see the following result:
- The environment variable of the "srv" application
- The entry written in the "srv" application startup log
- The entry in the logging table (only for Solution 1)
- The output of the calculation view filtered for client 200

Environment Variable set from extension file
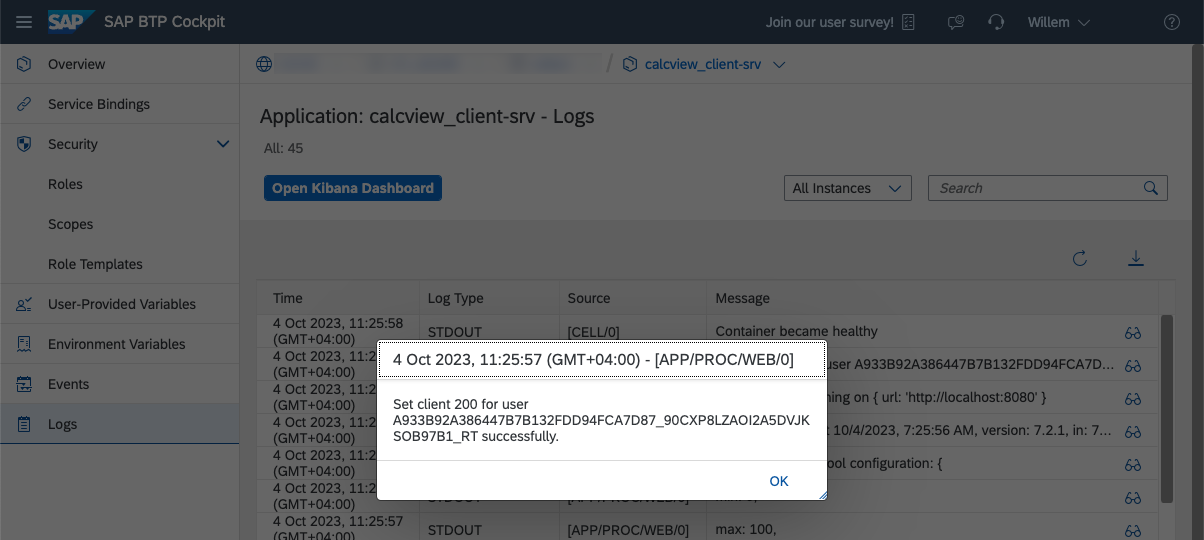
Application startup log showing a successful stored procedure call

Entry in the logging table showing the #OO and RT users

Query of the calculation view showing data filtered for client 200
Summary
This blog explored the scenario where a calculation view requires a client value to respond correctly, and where this client value has to remain dynamic up until the project deployment step. Staying within the HDI and CAP frameworks, we looked at an approach of using the HDI object owner to change the user parameter of the runtime user based on a value given by the CAP service layer, as well as an approach to set the client value for the database session.
Please share your thoughts about this approach in the comments below. There might be some potential alternative approaches so I'd love to continue the conversation below.
Git Repository: A sample project containing all artifacts can be found here: SAP BTP Global CoE Samples.
- SAP Managed Tags:
- SAP HANA Cloud,
- SAP Cloud Application Programming Model
Labels:
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,658 -
Business Trends
108 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
73 -
Expert
1 -
Expert Insights
177 -
Expert Insights
345 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
GraphQL
1 -
Kafka
1 -
Life at SAP
780 -
Life at SAP
14 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,575 -
Product Updates
387 -
Replication Flow
1 -
REST API
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,871 -
Technology Updates
478 -
Workload Fluctuations
1
Related Content
- SAP BTP FAQs - Part 2 (Application Development, Programming Models and Multitenancy) in Technology Blogs by SAP
- What’s New in SAP Analytics Cloud Q2 2024 in Technology Blogs by SAP
- advanced formula step for calculation of dynamic measures in Technology Q&A
- SAC Data Action Advanced Formula - Calculate dynamic Average in Technology Q&A
- What’s New in SAP Analytics Cloud Release 2024.07 in Technology Blogs by SAP
Top kudoed authors
| User | Count |
|---|---|
| 17 | |
| 15 | |
| 12 | |
| 11 | |
| 9 | |
| 8 | |
| 8 | |
| 7 | |
| 7 | |
| 7 |