
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- GenAI Integration with Events-to-Business Framewor...
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Product and Topic Expert
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
11-14-2023
9:16 PM
Introduction
The expanding complexity of industrial operations generates a multitude of critical events. Businesses primarily rely on manual operations to respond; however, such an approach limits their agility and adaptability to real-time changing conditions. As these businesses grow, so does their IT landscapes' complexity, warranting a need for improved performance and scalability. Our open-source framework called Events-to-Business (E2B) framework, built on the SAP Business Technology Platform (BTP) steps in to address this challenge. Designed with an event-driven architecture, it integrates events from varied non-SAP sources into SAP business processes, enhancing process efficiency. Regardless of whether these events emanate from IoT platforms, mobile or web applications, or enterprise systems, our framework seamlessly incorporates them. Apart from its extensibility and customization, it offers reusable components, integration capabilities with SAP services, and an accessible user interface for actions and services definitions. This enables users to design process actions efficiently based on real-time events. In essence, our solution bridges the gap between disparate landscapes, reduces manual effort, and empowers businesses to be more intelligent and interconnected.
Learn more about E2B framework and it’s use cases from other blogs in the series:
[Part-1] ‘Events-to-Business Actions’: An event-driven architecture on SAP BTP to implement Industry 4.0 scenarios with Microsoft Azure Services (click here)
[Part-2] Understand the details of “Events-To-Business Actions” framework (click here)
[Part-3] SAP Integration Suite’s upcoming event bridging functionality for outbound scenario (click here)
[Part-4] Try out ‘Events to Business Actions Framework’ for SAP Service Cloud scenario (click here)
[Part-5] Collaborative Event-Driven Business Applications with SAP BTP and Microsoft Teams (click here)
Challenge
One of the significant challenges faced by users when utilizing E2B framework is the considerable chunk of time and effort spent on identifying the correct API for their specific use-cases, at times even about 50% of development time. This time-consuming task becomes more complex as it is not simply about selecting an API; it's also about thoroughly understanding its capabilities, its interfaces, constraints, and exactly how it interacts with the other systems in the landscape. Moreover, users also need to understand which fields are necessary and should be filled up to ensure harmonious communication between systems. This requires going through extensive documentation often of the order of tens of thousands of lines, understanding the technical terminologies, and gaining insights into the designs of the API to ensure efficient use.
Adding to the complexity is the fact that often within E2B framework, there is a requirement for supporting actions to the main action. As an example, for a main action like creation of purchase order requisition, there is a need for pre-action in the form of fetching data from say Material Master and a post action like updating the requisition ID into the IoT database. Therefore, having built-in support or decision-making tools to guide users in API selection and usage would significantly enhance the efficiency and user-friendliness of the framework. To solve the challenge, we adopted a state-of-the-art solution powered by Generative AI, called Retrieval Augmented Generation (RAG), using the LangChain framework. Further explanations on these terms will be provided later in the article. For a refresher on Generative AI, readers can follow this article.
Generative AI Hub & SAP HANA Cloud Vector Engine Announcement
SAP is committed to advancing Generative AI, a subset of AI known for problem-solving capabilities. Recognizing its power to enhance business operations, SAP has invested heavily in its research and development to boost automation, decision-making, and customer experiences. By incorporating Generative AI into its applications and services, SAP enables businesses to generate new content, design products, automate customer services, and more.
At SAP TechEd 2023 in Bangalore, significant announcements were made regarding Generative AI, including the introduction of Joule, SAP's GenAI-based co-pilot as shown in Figure-1 (Ref: SAP TechEd 2023 Executive Keynote – Highlights). Set to integrate across SAP's cloud enterprise suite, Joule will provide proactive, context-based insights from various SAP and third-party sources. By quickly analysing and contextualizing data, Joule aims to enhance operational efficiency and drive better business outcomes, ensuring a secure and compliant process.
The AI Foundation will introduce a Generative AI Hub in the SAP AI Core that will provide developers direct access to a variety of Large Language Models (LLMs), facilitating model orchestration and accelerating Generative AI application development. This hub will also work seamlessly with the SAP HANA Cloud’s vector capabilities. Vector datastores, managing unstructured data, will aid AI models by providing better context and memory, simplifying interactions with LLMs, and easing the incorporation of Generative AI into applications. The SAP HANA Cloud Vector Engine will natively store and retrieve vector embeddings, facilitating the integration of LLMs with business data and empowering intelligent data applications through RAG.

Figure-1: Keynote by Chief Technology Officer and Member of the Executive Board of SAP Juergen Mueller
The Solution – Retrieval Augmented Generation
Now the question is why we chose RAG. It is extremely valuable for businesses because it allows them to combine the strengths of LLMs with their own business documents without the complex and expensive process of fine-tuning LLMs. Instead, it simply adds their unique data to the existing large dataset that LLMs use. This makes it streamlined and cost-effective to carry out QnA over documents or other knowledge bases.
Under the hood, RAG combines the retrieval of relevant information from a vast database of custom content not present in the original training data for the LLM, with a subsequent step where the retrieved information is used to generate an augmented response. In essence, the retrieved documents guide the language generation with the most relevant information. The concept is pictorially represented in Figure-2.
First, the set of documents over which one wants to do the QnA are collected and chunked which is a technique used to divide a large body of text or document into manageable, smaller pieces or "chunks". When a query is posed to a RAG model, it attempts to retrieve information from these databases. Given the size of some databases, it can be computationally inefficient to scan through the entire database for every query. By splitting the data into smaller chunks, the AI model can efficiently scan and retrieve relevant information pertaining to the query.

Figure-2: Brief Overview of Retrieval Augmented Generation (RAG)
These chunks are then embedded. Embeddings in Natural Language Processing (NLP) and Generative AI are numerical representations of text data. Embeddings can be thought of to translate language into numbers that a computer can understand. Essentially, each word or phrase is transformed into a list of numbers (vector) that represents its meaning and context. For example, in a very simplified model, we might represent the word "apple" as [1, 0], "orange" as [0, 1], and "fruit" as [0.5, 0.5], indicating that "fruit" is semantically related to both "apple" and "orange". But say something like “printer” will be represented as [10,10] showing it is both semantically and syntactically different from the above.
In terms of Generative AI, these embeddings serve as an efficient way to handle text data, as they allow the AI to consider semantic relationships between words or sentences when generating new text. They are used to reduce the high dimensionality of text data and to capture semantic and contextual meanings of words, sentences, or documents.
Embeddings are created by training a model on a large corpus of text. Each unique word or phrase in the text is assigned a numerical vector, often of a lower dimension than the original text space that represents its context in relation to the other words or phrases in the corpus. Two common algorithms used to create embeddings are Word2Vec and GloVe (Global Vectors for Word Representation), but transformer-based models like BERT (Bidirectional Encoder Representations from Transformer) and GPT-3 also generate sophisticated embeddings that capture a deeper level of linguistic context. Modern embedding models like text-embedding-ada-002 by OpenAI convert each embedded chunk into a vector containing 1536 numbers.
These embeddings are stored into a vector database (VDB). Imagine the VDB to be a table of two columns, with the text being on the left and its corresponding embedding on the right. The rows correspond to all the chunks created.
The query which the user gives too is embedded using the same model which is used on the chunks. After this, similarity search is performed which is a process of comparing query vector with other vectors in the VDB using mathematical functions. The goal is to find the document vectors that are most similar (closest) to the query. After the most similar documents are retrieved, the LLM uses these documents as context, and the original query, to generate the response. By using similarity search, RAG ensures that the responses generated by the LLM are relevant and accurate with respect to the input query.
RAG with API Data
The proposed approach aimed to develop a Vector Database (VDB) using raw data from various pertinent APIs, diverging from conventional RAG use cases that predominantly rely on common text content from sources like PDFs or websites. For instance, the raw data for the Purchase Requisition API consisted of around 9000 lines of content, as partly illustrated in the Figure-3. Finally, the implementation of RAG was enabled through the SAP Generative AI Hub, currently accessible on canary BTP sub-accounts. We have used GPT-4 as the model after experimenting with various LLMs and doing relative performance analysis.

Figure-3: Purchase Requisition API Raw Data
For storage of vectors, we opted for PostgreSQL, in line with recommended practice, until the release of the HANA Vector Engine. We utilized the pgvector extension within PostgreSQL, which facilitates the execution of similarity search algorithms. The central goal for our use case was to enable action chaining, allowing the main action to be seamlessly connected with preceding and succeeding actions. Moreover, we aimed for the model to intelligently determine whether a given main action requires pre and/or post actions. Thus, before initiating the RAG call, it was deemed pragmatic to first parse the user query and extract the actions via a standard chat completion call to the LLM. In our scenario, the LLM acted as an "action recommendation engine for the E2B scenario," with additional traits for the necessary task.
To make sure of the efficacy of the model in generating the right set of actions, we used Few-Shot Prompting which is a technique used the model is given a few number of examples, to help guide its understanding of a task. In this technique, the model is shown a few instances of the input-output pair for a particular task at the beginning of the prompt. This helps the model understand what is expected of it for the rest of the prompt. For example, if we want a model to translate English to German, we might provide it with couple of English sentences along with their German translations, and then give it a new English sentence to translate. The initial pairs effectively serve as instructions to guide the model's subsequent performance with the new English sentence. Here, we gave it a few examples of how query parsing would work to create action chains.
Now these actions would be used with the API VDB for RAG as shown in Figure-4.

Figure-4: Chained Action Generation using RAG
It is essentially Chain of Thought Prompting (CoT) that we use for the entire flow, by first breaking down the user query followed by RAG. It is a technique that aids in maintaining a relative state of coherence and context throughout a conversation or a block of content. For instance, if an LLM is involved in a dialogue or is generating a longer narrative, CoT allows the model to keep track of themes, scenarios, or arguments already mentioned or developed, and then to create responses or further text that logically continues from these, much like how a human would hold a consistent thread of thought throughout a conversation. It improves tractability of using LLMs and improves performance by breaking down a big task into smaller steps.
Eventually, we ask the LLM to generate the following facets:
- Action Payload
- Action Name
- Brief Description of API
- Request Method (GET, PUT, POST, PATCH, DELETE)
- API Path
Below is a demo for the Generative AI powered action chaining capability in E2B framework which is embedded in the UI.
We observe that with inclusion of Generative AI in the scenario, the process of selecting and configuring APIs became so straightforward and streamlined. With this new addition, the complete solution architecture looks as shown below in Figure-5.
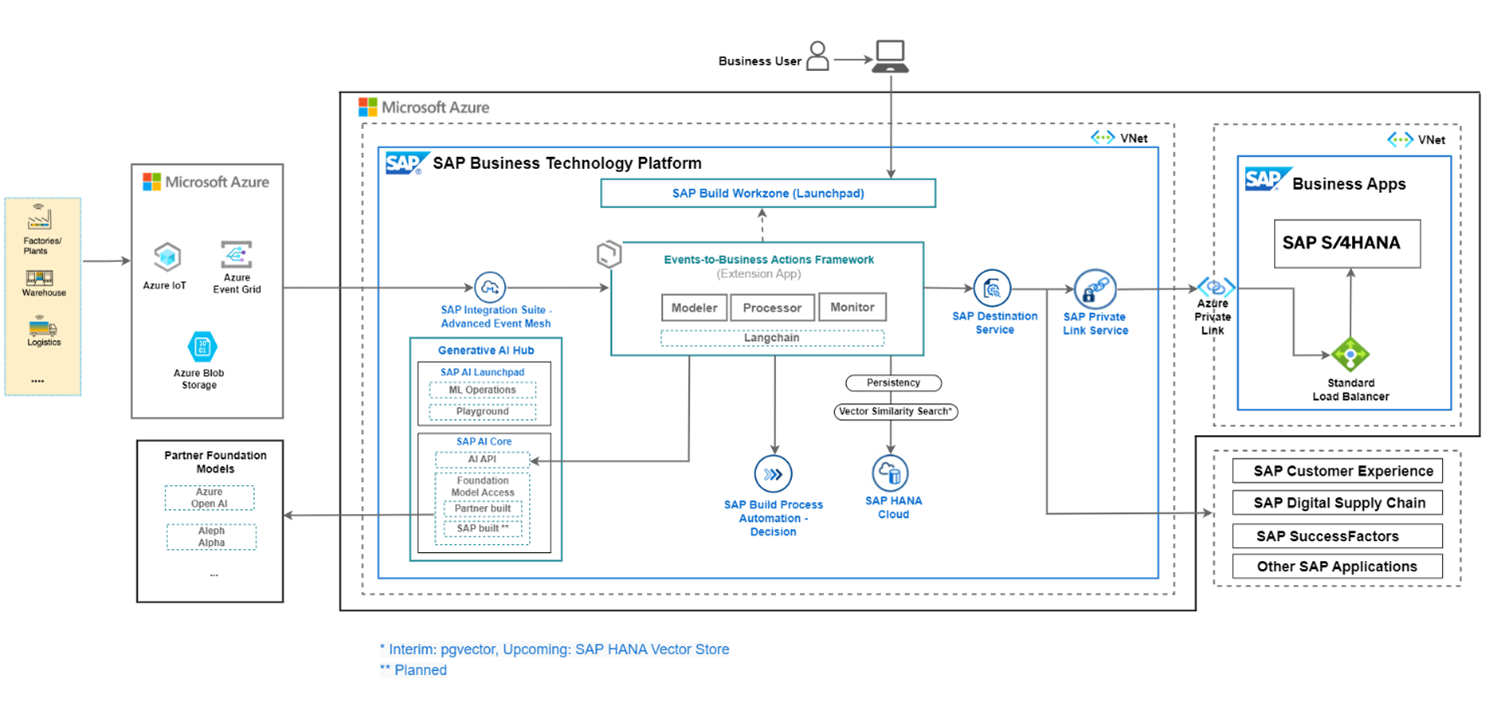
Figure-5: Architecture Diagram with Generative AI Hub
Conclusion
We observe that through the integration of cutting-edge techniques such as RAG, Few-Shot Prompting and Chain of Thought Prompting into the E2B Framework has illuminated a path toward transformative event-driven orchestration. These innovative approaches have allowed us to streamline and enhance the process of crafting JSON payloads and orchestrating business actions in response to critical events, ultimately contributing to increased automation, accuracy, and responsiveness. The process of selecting and setting up APIs is brought down from order of hours to few days, down to few minutes. RAG promises to be a very useful and robust technology that will serve as the go-to technique for all enterprise grade Generative AI use cases that require conversation with custom data.
With SAP Generative AI Hub, the task of testing with different LLMs and checking their comparative performances becomes easy. After launch of SAP HANA Cloud Vector Engine, the dependency on 3rd party databases for storing embeddings will also be averted, meaning enterprises will have their models, applications and data housed within the SAP BTP landscape thus ensuring security, integrability, and extensibility.
Authors
Vedant Gupta, Associate Developer - BTP Platform Advisory & Adoption, SAP Labs India (vedant_gupta, LinkedIn)
Praveen Kumar Padegal, Development Expert - BTP Platform Advisory & Adoption, SAP Labs India (praveenpadegal, LinkedIn, Twitter)

Acknowledgements
Many thanks to my team members praveenpadegal, ajitkpanda and swati_maste for driving this project by collaborating with all the stakeholders involved in the engagement, and our leaders anirban.majumdar and pvn.pavankumar for their support in this project. Thanks to Wolfgang Moller from NTT Data Business Solutions for insights on the use case.
For more information about this topic or to ask a question, please contact us at paa_india@sap.com.
- SAP Managed Tags:
- Artificial Intelligence,
- SAP AI Services,
- SAP AI Core,
- SAP AI Launchpad,
- SAP Business Technology Platform
Labels:
3 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,658 -
Business Trends
105 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
70 -
Expert
1 -
Expert Insights
177 -
Expert Insights
337 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
GraphQL
1 -
Kafka
1 -
Life at SAP
780 -
Life at SAP
14 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,575 -
Product Updates
379 -
Replication Flow
1 -
REST API
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,872 -
Technology Updates
469 -
Workload Fluctuations
1
Related Content
- Replicate BOM Product from S/4 Hana Private Cloud to CPQ 2.0 in Technology Q&A
- Essential SAP Fiori Transaction Codes for Fiori Developers in Technology Q&A
- Opening Fiori Launchpad with Transaction Code /UI2/FLP via Hosts File Modification in Technology Q&A
- Connectivity guaranteed with Cloud Integration version and Cloud Connector version in Technology Q&A
- How to troubleshoot BusinessObjects Business Intelligence Platform server/service issues in Technology Blogs by SAP
Top kudoed authors
| User | Count |
|---|---|
| 18 | |
| 12 | |
| 9 | |
| 8 | |
| 7 | |
| 6 | |
| 6 | |
| 6 | |
| 6 | |
| 6 |