
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- Getting Started with Document Information Extracti...
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Product and Topic Expert
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
02-20-2020
4:06 AM
Introduction
Over recent weeks, I have encountered few customer PoC scenarios that involve reading digitized document and extract key information to further processing later (i.e. posting to SAP backend). This is tricky considering digitized documents such as invoices will have very high variability, and we can imagine how many billions of invoices are issued each year in Asia alone.
A traditional OCR won't help us in this as it requires all documents come in same format or few fixed format. What we need is an AI powered OCR technology to handle documents that vary from one vendor to another.
Let's check out options that we have here:
- Inference Service for OCR from SAP Leonardo Machine Learning Foundation Functional Services.
Unfortunately this generic OCR service has been deprecated from SAP API Business Hub. Will skip this one for now. - Document Information Extraction
This service is part of SAP AI Business Services portfolio offering. SAP Concur Invoice, and SAP S/4HANA (i.e. SAP Cash Application) already uses Document Information Extraction service as part of their solution package. Now to benefit customer who wants to use this service via API integration to their Applications, it's made available via CPEA since September 2019. The trial service available on November 2019.
Setting Up Document Information Extraction Trial Service
The Document Information Extraction service is a pre-trained service leverages deep-learning algorithms to extract structured semantical information from unstructured documents, at the same time, specialized models are available for the most common document types to provide even better extraction results and additional capabilities.
This API service takes in PDF (textual or image-based) as input and returns structured information in the from of JSON format. Extraction group as follows:
- Header field
- Line item
- Matching
- Country detection
Where as the supported document types are vendor invoices and payment advices at the moment.
This article will guide you on setting up the Document Information Extraction Trial in your SAP Cloud Platform Trial account.
Prerequisite
Step 1: Login to SAP Cloud Platform Trial Cockpit
SAP Cloud Platform trial cockpit here. Skip this step if you have already logged-in.
Step 2: Access Cloud Foundry Trial Sub-Account
Click
Access Cloud Foundry Trial link. You will find the link when you scroll down the page.
If there's no Cloud Found Trial sub-account provisioned, just create one. But do make sure you have selected
Europe (Frankfurt) in Region drop-down selection.Click
trial sub-account link.
Step 3: Access Cloud Foundry Trial Dev Space
Click
dev link in the Spaces (1) section.
Step 4: Access Service Marketplace
Click
Service Marketplace link from side menu drawer under Services.
Step 5: Create Document Information Extraction Service Instance
Search for
Document Information Extraction trial service, and click Document Information Extraction tile.Note: If you don't see this service, the quota for Document Information Extraction service may need to be configured explicitly for your SAP Cloud Platform Trial account. Try to configure the entitlement and quota as described here.

Click
Instances from side menu drawer.
Click
New Instance button.
A create instance wizard pop-up will appears. Click
Next button to proceed.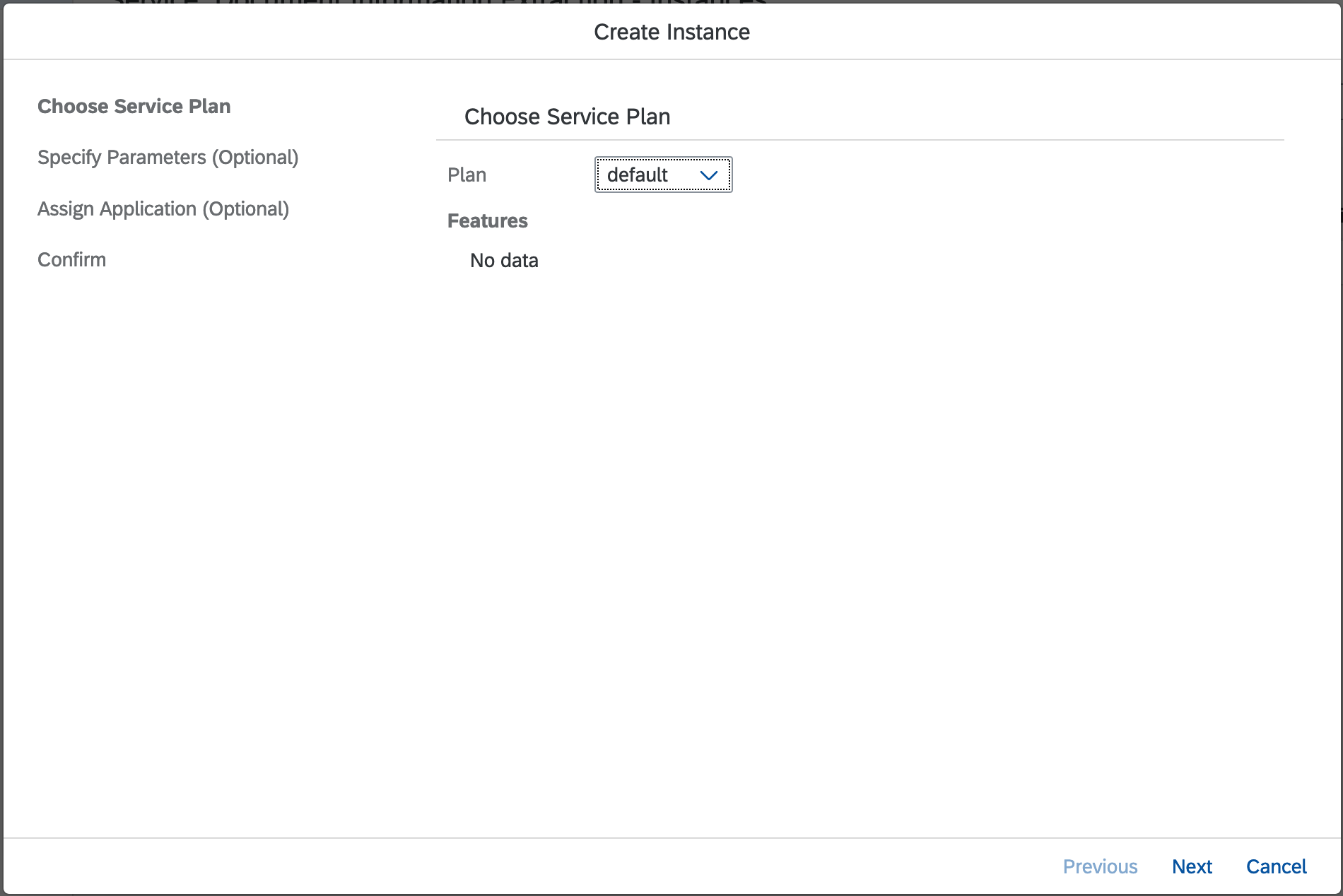
No parameters required, just click
Next button.
Click
Next button again as we don't have Application deployed in Cloud Foundry.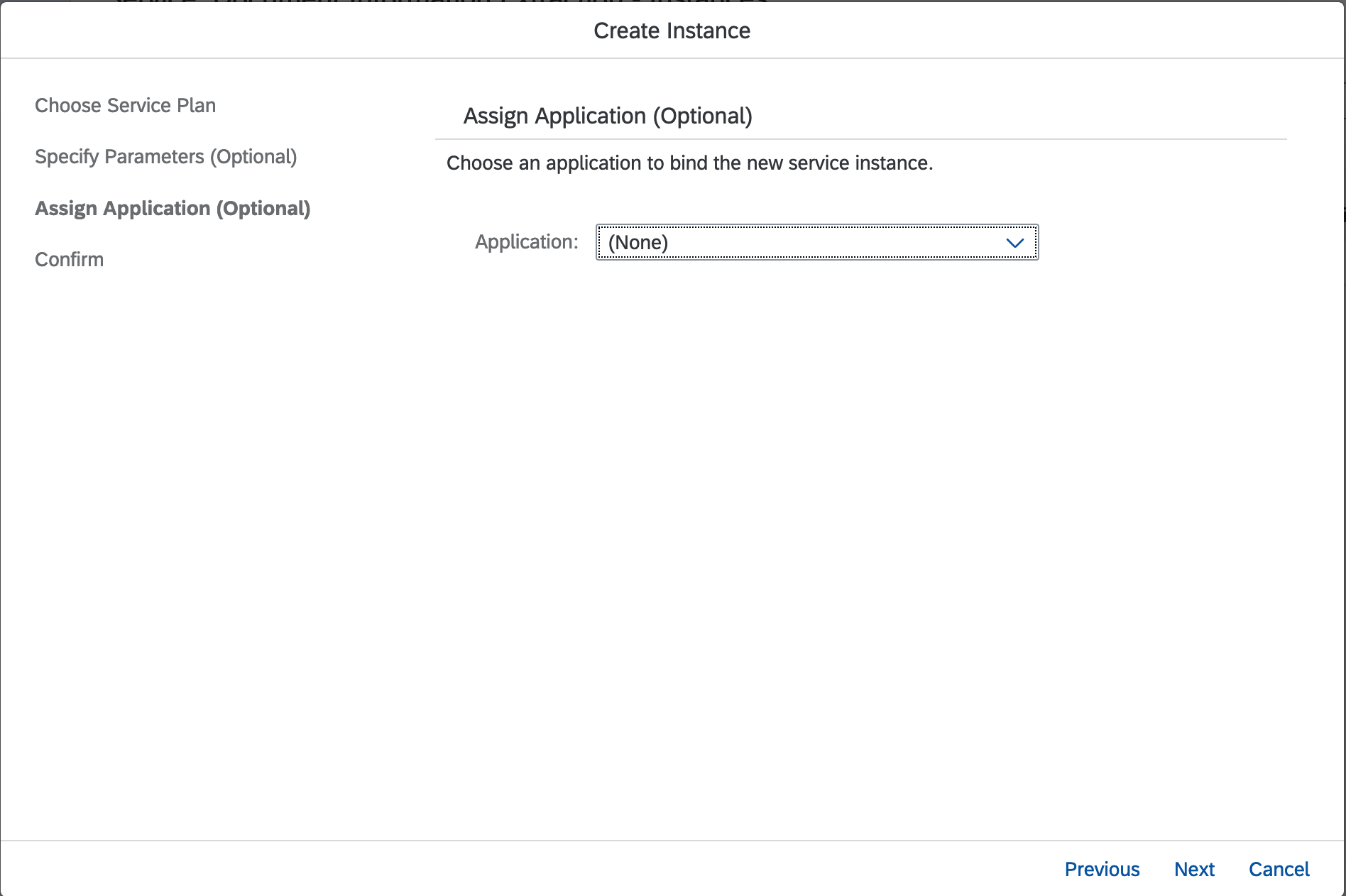
Enter the instance name, here I put
doc-ocr-demo.
Once new instance successfully created, you will see the status
Created in Last Operation column.Click the instance name (i.e. doc-ocr-demo) to proceed next step.

Step 6: Create New Service Key
A service key is required to access the Document Information Extraction API instance that we have created above.
Click
Service Keys from side menu drawer, and click Create Service Key button.
A create instance wizard pop-up will appears. Enter the service key name, here I put
doc-ocr-demo-service-key. Click Save to proceed.
Once the a service key has been created, you will see JSON output containing API endpoint URL and User Account and Authentication (UAA) details. Copy the JSON output and save it in your favorite notepad or text-pad application. You will need it later.

Getting Started with Document Information Extraction Trial Service
Yes, the Document Information Extraction API has Swagger built-in that make it easier to test the service.
Step 1: Testing Document Information Extraction API via Swagger
To access Swagger, just copy the
url value (not inside uaa JSON node) from service key's JSON output and append /document-information-extraction/v1. You should get this page:
Step 2: Generate API Authorization Bearer Token
In order to consume any of the Document Information Extraction API service, we will need Authorization Bearer Token.
You can use Postman to generate bearer token - use HTTP GET.
Copy
url value inside uaa JSON node from service key and append query oauth/token?grant_type=client_credentials.In HTTP HEADER authorization use Basic Auth type, and copy
clientid value and clientsecret value inside uaa JSON node from service key as username and password.Copy the
access_token value for next step.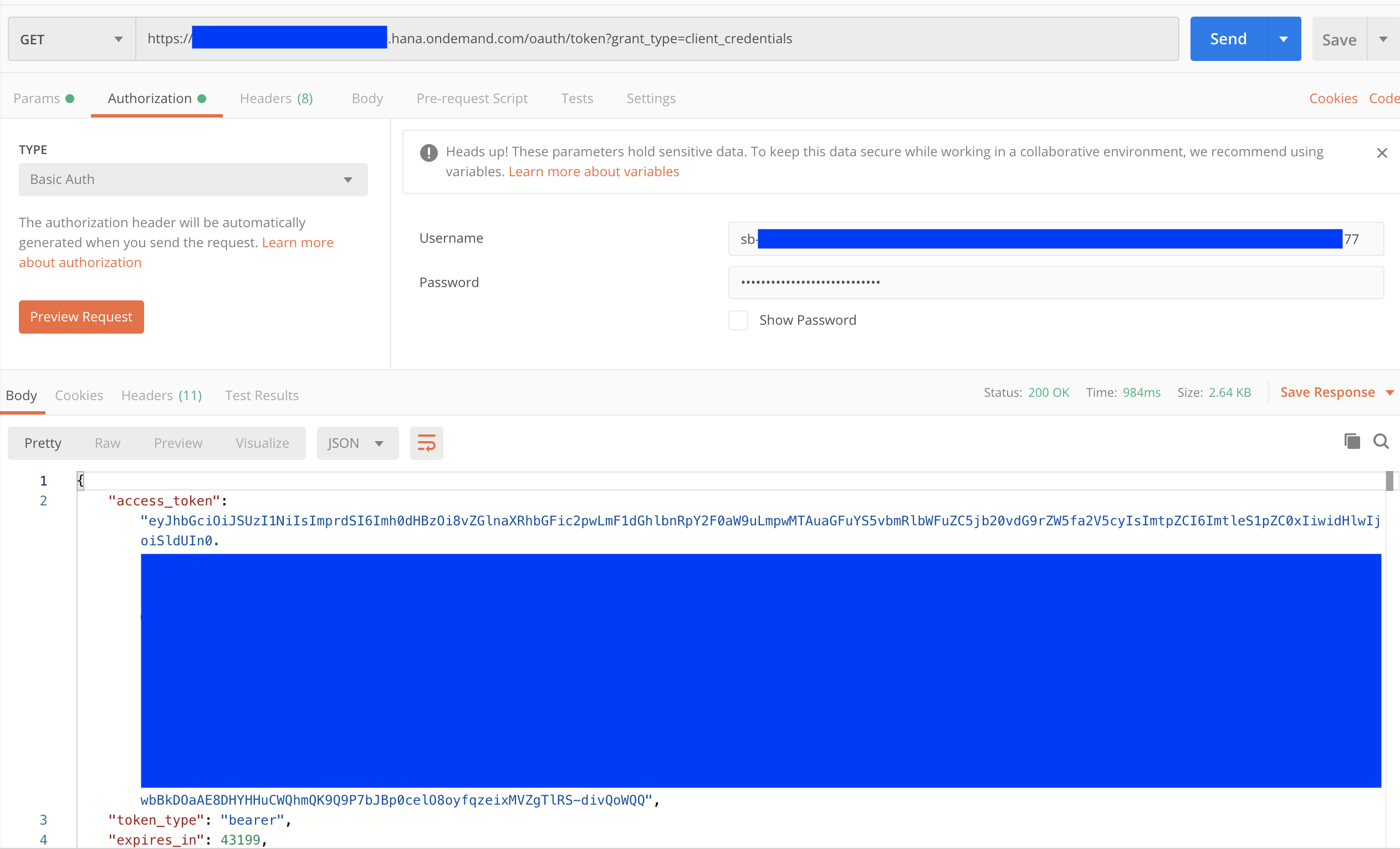
Step 3: Create Client
Client is required for submitting the document for information extraction processing.
But first click on
Authorize button to open Available authorizations pop-up. Enter the Bearer text with access_token value from previous step into the Value text field and click Authorize button.
Open POST /clients API section to create one client, and try it out the API.
Feel free to modify the
clientId and clientName value. You should get 201 success response if authorization bearer token and POST /clients payload configured correctly.Note down the
clientId for next step.
Step 4: Upload PDF Document for OCR Processing
Now we have API client created, let's try out extract structured information from PDF document such as invoice, or payment advice document.
Open POST /document/jobs API section, and try it out.
The API accept
file and options in formData content-type.Leave the JSON payload in
options default as we want to get all extraction header fields and line items, however please ensure you input the right clientId in the payload.Start upload any sample invoice, and execute it.

Now the document has been submitted for processing, as you can see the in response body, there's an
id issued and status PENDING. Copy down the id value.
Step 5: Retrieve OCR Results of PDF Document Uploaded
Open GET/document/jobs/{uuid} API section, and try it out.
Fill in the right
clientId, and uuid. Execute it.
If the document processing completed, in the response body we will see status
DONE otherwise status will still PENDING. Try it again in few seconds.
So far so good, the extracted information from my uploaded sample invoice pdf scores high accuracy.

That's it. There are some other API services that you can it try yourself here at your own pace, for example:
- GET /capabilities - to see lists of extractable fields, enrichment and document types that the API is
capable of processing.
- GET /document/jobs - to see lists of submitted jobs (uploaded pdf documents processing).
Go ahead try the Document Information Extraction Trial service yourself.
Resources / References
Labels:
35 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,658 -
Business Trends
107 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
72 -
Expert
1 -
Expert Insights
177 -
Expert Insights
340 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
GraphQL
1 -
Kafka
1 -
Life at SAP
780 -
Life at SAP
14 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,575 -
Product Updates
384 -
Replication Flow
1 -
REST API
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,872 -
Technology Updates
472 -
Workload Fluctuations
1
Related Content
- SAP Cloud ALM: Requirements Management on Steroids in Technology Blogs by SAP
- Notes to Documents Migration in Technology Blogs by SAP
- 10+ ways to reshape your SAP landscape with SAP Business Technology Platform – Blog 7 in Technology Blogs by SAP
- revamped SAP First Guidance Collection in Technology Blogs by Members
- Third-Party Cookies and SAP Analytics Cloud in Technology Blogs by SAP
Top kudoed authors
| User | Count |
|---|---|
| 17 | |
| 14 | |
| 12 | |
| 10 | |
| 9 | |
| 8 | |
| 7 | |
| 7 | |
| 6 | |
| 6 |