Getting Started with Document Information Extracti...
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Over recent weeks, I have encountered few customer PoC scenarios that involve reading digitized document and extract key information to further processing later (i.e. posting to SAP backend). This is tricky considering digitized documents such as invoices will have very high variability, and we can imagine how many billions of invoices are issued each year in Asia alone.
A traditional OCR won't help us in this as it requires all documents come in same format or few fixed format. What we need is an AI powered OCR technology to handle documents that vary from one vendor to another.
Let's check out options that we have here:
Inference Service for OCR from SAP Leonardo Machine Learning Foundation Functional Services.
Unfortunately this generic OCR service has been deprecated from SAP API Business Hub. Will skip this one for now.
Document Information Extraction
This service is part of SAP AI Business Services portfolio offering. SAP Concur Invoice, and SAP S/4HANA (i.e. SAP Cash Application) already uses Document Information Extraction service as part of their solution package. Now to benefit customer who wants to use this service via API integration to their Applications, it's made available via CPEA since September 2019. The trial service available on November 2019.
Setting Up Document Information Extraction Trial Service
The Document Information Extraction service is a pre-trained service leverages deep-learning algorithms to extract structured semantical information from unstructured documents, at the same time, specialized models are available for the most common document types to provide even better extraction results and additional capabilities.
This API service takes in PDF (textual or image-based) as input and returns structured information in the from of JSON format. Extraction group as follows:
- Header field
- Line item
- Matching
- Country detection
Where as the supported document types are vendor invoices and payment advices at the moment.
This article will guide you on setting up the Document Information Extraction Trial in your SAP Cloud Platform Trial account.
SAP Cloud Platform trial cockpit here. Skip this step if you have already logged-in.
Step 2: Access Cloud Foundry Trial Sub-Account
Click Access Cloud Foundry Trial link. You will find the link when you scroll down the page.
If there's no Cloud Found Trial sub-account provisioned, just create one. But do make sure you have selected Europe (Frankfurt) in Region drop-down selection.
Click trial sub-account link.
Step 3: Access Cloud Foundry Trial Dev Space
Click dev link in the Spaces (1) section.
Step 4: Access Service Marketplace
Click Service Marketplace link from side menu drawer under Services.
Step 5: Create Document Information Extraction Service Instance
Search for Document Information Extraction trial service, and click Document Information Extraction tile.
Note: If you don't see this service, the quota for Document Information Extraction service may need to be configured explicitly for your SAP Cloud Platform Trial account. Try to configure the entitlement and quota as described here.
Click Instances from side menu drawer.
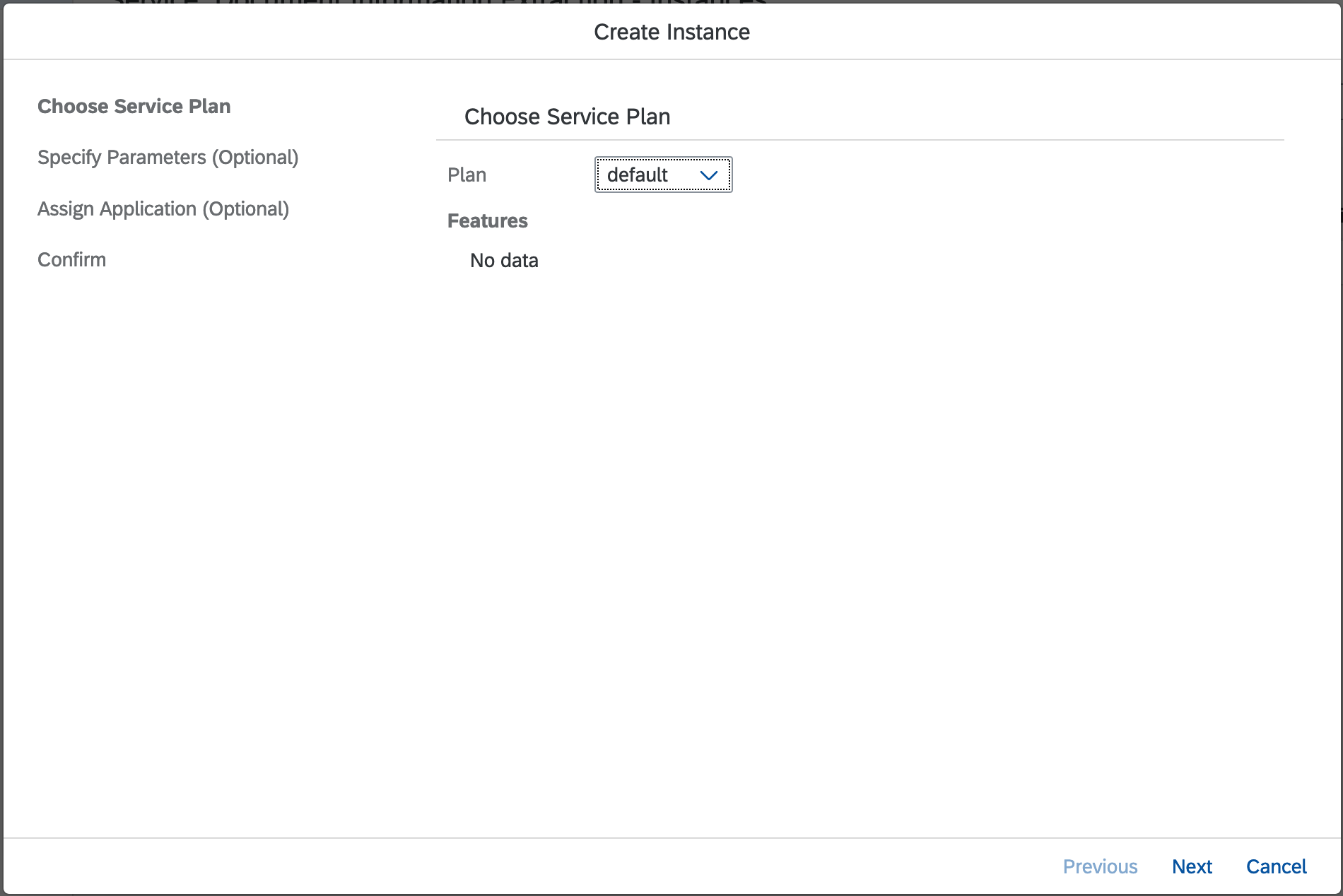
Click New Instance button.
A create instance wizard pop-up will appears. Click Next button to proceed.
No parameters required, just click Next button.
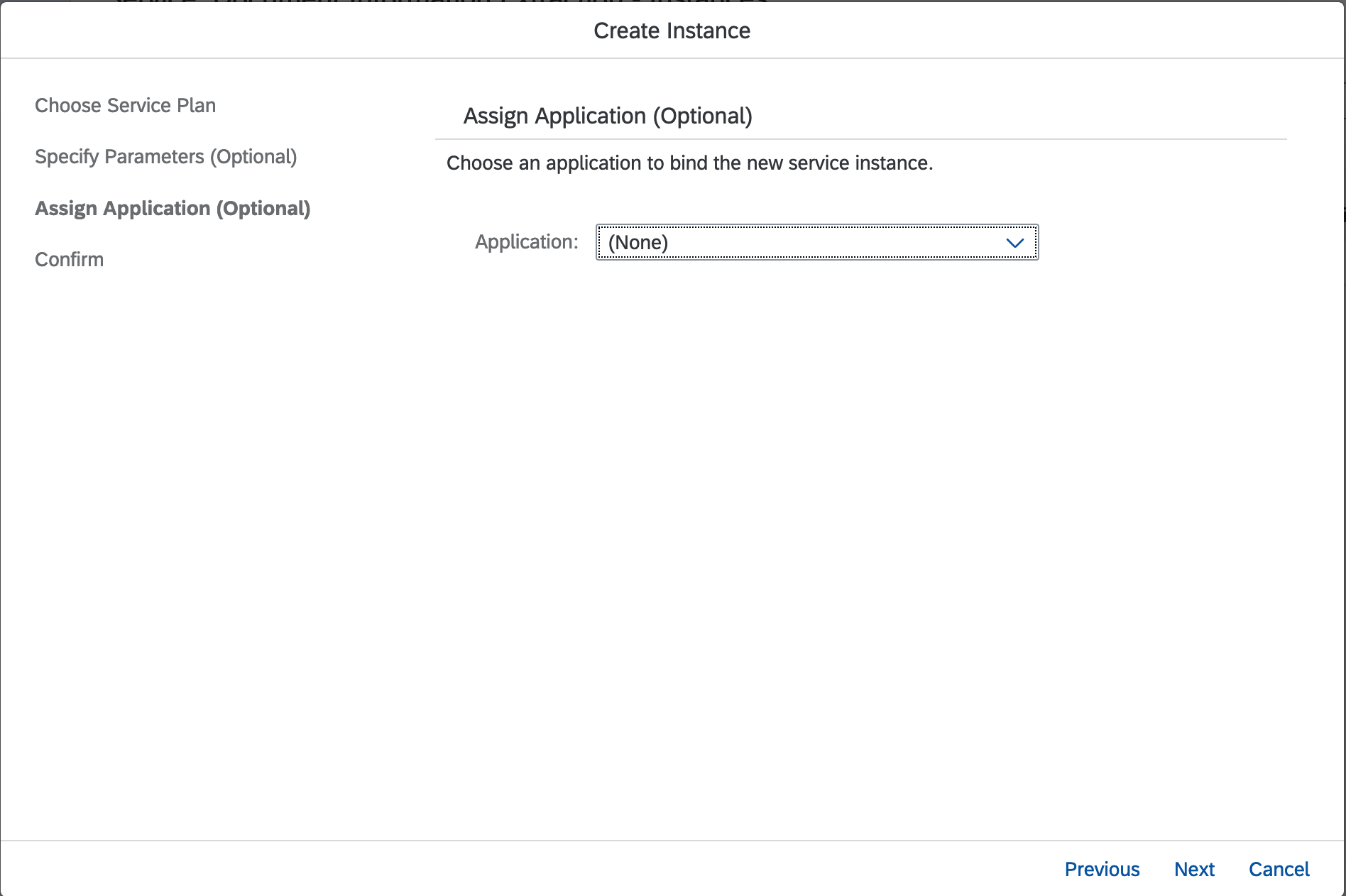
Click Next button again as we don't have Application deployed in Cloud Foundry.
Enter the instance name, here I put doc-ocr-demo.
Once new instance successfully created, you will see the status Created in Last Operation column.
Click the instance name (i.e. doc-ocr-demo) to proceed next step.
Step 6: Create New Service Key
A service key is required to access the Document Information Extraction API instance that we have created above.
Click Service Keys from side menu drawer, and click Create Service Key button.
A create instance wizard pop-up will appears. Enter the service key name, here I put doc-ocr-demo-service-key. Click Save to proceed.
Once the a service key has been created, you will see JSON output containing API endpoint URL and User Account and Authentication (UAA) details. Copy the JSON output and save it in your favorite notepad or text-pad application. You will need it later.
Getting Started with Document Information Extraction Trial Service
Yes, the Document Information Extraction API has Swagger built-in that make it easier to test the service.
Step 1: Testing Document Information Extraction API via Swagger
To access Swagger, just copy the url value (not inside uaa JSON node) from service key's JSON output and append /document-information-extraction/v1. You should get this page:
Step 2: Generate API Authorization Bearer Token
In order to consume any of the Document Information Extraction API service, we will need Authorization Bearer Token.
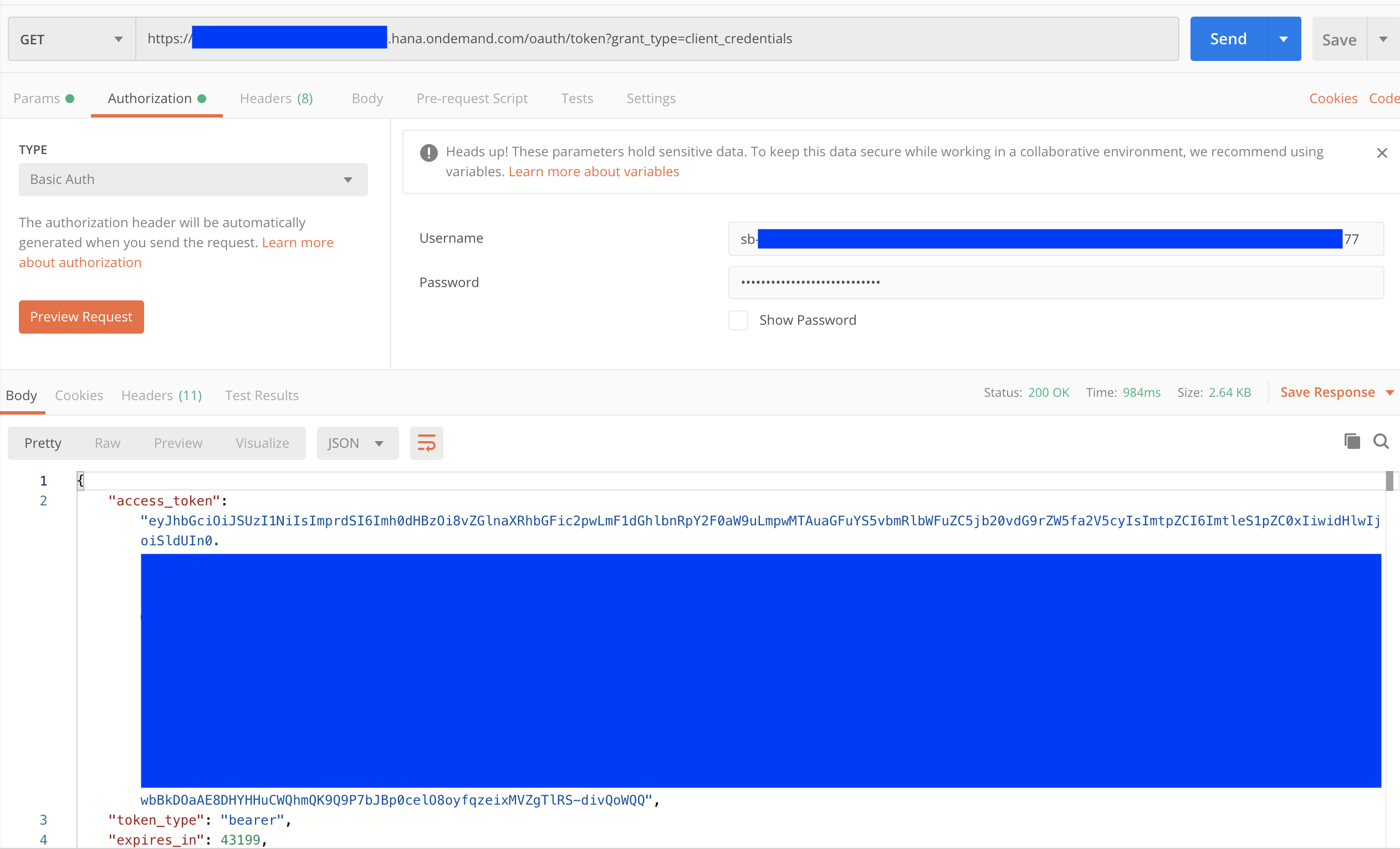
You can use Postman to generate bearer token - use HTTP GET.
Copy url value inside uaa JSON node from service key and append query oauth/token?grant_type=client_credentials.
In HTTP HEADER authorization use Basic Auth type, and copy clientid value and clientsecret value inside uaa JSON node from service key as username and password.
Copy the access_token value for next step.
Step 3: Create Client
Client is required for submitting the document for information extraction processing.
But first click on Authorize button to open Available authorizations pop-up. Enter the Bearer text with access_token value from previous step into the Value text field and click Authorize button.
Open POST /clients API section to create one client, and try it out the API.
Feel free to modify the clientId and clientName value. You should get 201 success response if authorization bearer token and POST /clients payload configured correctly.
Note down the clientId for next step.
Step 4: Upload PDF Document for OCR Processing
Now we have API client created, let's try out extract structured information from PDF document such as invoice, or payment advice document.
Open POST /document/jobs API section, and try it out.
The API accept file and options in formData content-type.
Leave the JSON payload in options default as we want to get all extraction header fields and line items, however please ensure you input the right clientId in the payload.
Start upload any sample invoice, and execute it.
Now the document has been submitted for processing, as you can see the in response body, there's an id issued and status PENDING. Copy down the id value.
Step 5: Retrieve OCR Results of PDF Document Uploaded
Open GET/document/jobs/{uuid} API section, and try it out.
Fill in the right clientId, and uuid. Execute it.
If the document processing completed, in the response body we will see status DONE otherwise status will still PENDING. Try it again in few seconds.
So far so good, the extracted information from my uploaded sample invoice pdf scores high accuracy.
That's it. There are some other API services that you can it try yourself here at your own pace, for example:
- GET /capabilities - to see lists of extractable fields, enrichment and document types that the API is
capable of processing.
- GET /document/jobs - to see lists of submitted jobs (uploaded pdf documents processing).
Go ahead try the Document Information Extraction Trial service yourself.
I've followed your instructions - however, I cannot find any "Document Information Extraction trial service" as described in step 5 - any clue? Cheers, Andy
Excellent document Joni, thank you for putting this out there , very clear and simple to follow. Got it all working in our SCP. Now will to try this out with iRPA to process customer purchase orders.
Thanks for your comment.
No retraining option made available at the moment, however the product team does open up an option for co-innovation (case by case basis) with customer if they have specific document templates where retraining is required to extract wider range of extraction attributes.
Hi Yasir, as Joni mentioned, the retraining is currently possible as a co-innovation approach. However, the product team is also working on the so called "template processing" functionality. With that the user will get the opportunity to define a recurring layout which features the relevant fields that need to be extracted. The beta release is planned with 2005a. Best, Tomasz
I uploaded the invoice pdf and now tryin to get the extracted results but the status is still pending after almost 10 mins. Does this mean, it was not able to process the pdf ?
Sorry somewhat I missed the notification of your comment.
The DOX API service accept PDF format, but please ensure your pdf file size not that big (try to compress it if it's above 2Mb); or check if the swagger API is also down, if yes, you may want to restart the API service instance by recreating it since trial has limited resources quota. If issue still persist you can try raise the ticket to get further support.
You can't add other document type yet as this is pre-trained model so the structured extraction result is optimised for above document types only at the moment.
Need to wait for the new version release (by this end March) first before it's available on trial account.
Please try it on your project and let me know how it goes 🙂
I'm investigating the posibilities of this service for my company and I'd like to ask you a couple of qestions about retraining process:
1.- If I send Confirmed documents to retrain the service, would the retraining results affect only to my instance/tenant or affect to the instances/tenants of any other client too?
2.- Does the retraining process allow to extract more fields than the preset ones for a document type?
1- Your own tenant
2- Fixed extraction fields - header fields: https://help.sap.com/viewer/5fa7265b9ff64d73bac7cec61ee55ae6/SHIP/en-US/b1c07d0c51b64580881d11b4acb6a6e6.html and line item fields: https://help.sap.com/viewer/5fa7265b9ff64d73bac7cec61ee55ae6/SHIP/en-US/ff3f5efe11c14744b2ce60b95d210486.html
Before I ask you, I had tryed to ask SAP many times without sucess about this theme. After your answer and to be sure (you put AFAIK), I try to ask SAP again and I got finally an answer from SAP AI BUS - Document Information Extraction Team, especifically from Sebastian Koebe and I want to share it with you:
Q1.- Would the retraining results affect only to my instance/tenant or affect to the instances/tenants of any other client too?
Answer: Currently the data feedback information we are collecting from users, will be used to improve our global extraction models and would therefore benefit/affect all customers. In the future we are planning to also enable users to improve the extraction results only for their tenant.
Q2.- Does the retraining allow to extract more fields than the preset ones for a document type?
Answer: No, the feedback data collection and sub-sequent retraining is not related to the extraction of additional fields. The structural extensibility of a document type is something that we will provide via the templating mechanism in the near future.
I received the same error but I don't have any idea what you mean by deleting a customer record. I don't see anywhere in there where I would have a customer record.
To process documents or upload enrichment data, you need to create at least one client. You can use this API (via Swagger): Get Client to see number of client entries there, if it's more than 1, just use this API: Delete Client to remove the client / customer entry.
To add to Joni Liu's answer: you already have a default client when using your trial account. Check with GET/clients. The client id should be "default" and you can use it without problems.
Hi, the create template function is not available for trial? I tried do create a custom schema, and then uploaded to the service. Then an option to create a template appears but when I try do create the template, the message error says something like "not having a plan".
But using the same functionality inside Sap Process Automation, I was capable of doing the annotations.
The create template function is available under Trial landscape with 'default' plan. You can try the following resolutions:
Ensure you have these roles assigned to your user for creating template: Document_Information_Extraction_UI_Admin_User_trial and Document_Information_Extraction_UI_Templates_Admin_trial.
If you already had above roles but still facing issue, you could try to delete existing subscription, and re-subscribe using Booster approach.
I have just tried with my trial (AWS - US EAST) without an issue when creating custom schema and template. Hope it helps.
Hi joni.liu Thanks for the beautiful blog. We were able to extract the information from the document we uploaded from our local machine. Could you please help us to understand is there a way to bring the document from other cloud system (SAP Service Cloud) to SAP BTP and extract the information from the document out of it and send the extracted information back from BTP to the cloud system.
We are bit stuck in this use case. Could you please help us on this by sharing the right way to do it?
Thanks abasu_accn to my understanding of your question here, as long as there's (document download) API from other cloud system that allow you to download the document, then yes perhaps you can automate the process of download, upload, and extract the document all via APIs.
And if API not available, then you can consider to leverage on RPA.
This kind of task automation (automate via API and/or RPA) can be configured within SAP Build Process Automation too.
Note: SAP Build Process Automation has a bundled version of DOX (see more details here, and demo here).
Since I'm not SAP Cloud Service expert, perhaps you can check with your SAP Service Cloud contact on its (document download) API availability.
We are using ODATA call to extract the document from SAP Service Cloud and it comes as a Binary content in the payload. Do we have anything on BTP side which read binary content and extract information from the content?