
- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- SAP AI Core - Scheduling SAP HANA Machine Learning
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Product and Topic Expert
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
08-10-2023
2:36 PM
SAP AI Core is a component of the SAP Business Technology Platform to deploy any kind of Machine Learning model into production. It is particularly targeted at developers from both SAP partners and SAP's internal development organisation.
This blog gives an introduction on using SAP AI Core to train a Machine Learning model in SAP HANA Cloud (or SAP Datasphere) to estimate the price of a used car through SAP's Python package hana_ml. The Python code gets executed in SAP AI Core, but the hana_ml package pushes the calculation logic to SAP HANA Cloud, leveraging the embedded Machine Learning (Predictive Analysis Library and Automated Predictive Library). Data and algorithms are already in SAP HANA Cloud, hence no data needs to be extracted or moved elsewhere, not even into SAP AI Core.
Just for completeness, the Python logic to trigger the Machine Learning in SAP HANA Cloud can be deployed in virtually any other Python environment, SAP AI Core is just one option. On the SAP Business Technology Platform for instance you also have CloudFoundry, Kyma or SAP Data Intelligence. Examples for deployment on non-SAP Systems are Databricks, Azure, Google or Dataiku. The choice is yours.
Table of contents:
To follow this blog, all data and code is available in this repository.
Prerequisites to follow this blog hands-on:
No Machine Learning without data. Start by loading the training data for our scenario. This blog is focussing on how the hana_ml logic can be deployed to SAP AI Core. Hence we skip the data exploration and preparation steps that would be extremely important in a real project.
Our data is based on the Ebay Used Car Sales Data. For simplification various columns from the dataset have been deleted from the file that we are using here. Also, vehicles that were in need of repair have been excluded. A detailed analysis of this dataset and various Machine Learning models on that data can be found in the (German speaking) Book Data Science mit SAP HANA. An older (English) example is in the blog SAP Data Intelligence: Deploy your first HANA ML pipeline.
The following Python code and the dataset can be downloaded from the repository.
Connect to SAP HANA Cloud:
Read the data into a Pandas DataFrame and upload the data as table into SAP HANA Cloud.
Create a filtered view of the data and display a few rows. The data is filtered so that outliers that can distort the Machine Learning are excluded, ie the most expensive cars. This view will be used as source to train the Machine Learning model.
Typically in a project I would start the Machine Learning side in a Jupyter Notebook, to explore the data, to prepare the data and to experiment with Machine Learning. We are skipping these steps here and go straight to the final code that we want to deploy.
The following Python code can be downloaded from the repository (main.py).
Steps in that file:
The code can identify whether it is running inside AI Core (Kubernetes) or outside. If run inside AI Core, it retrieves the logon credentials for SAP HANA from AI Core's secret store (we will set this up later). If run outside AI Core, it uses the Secure User Store, that we have also used above to load the data to SAP HANA Cloud in the first place. Also, when run in AI Core it will also store a model metric with the execution in AI Core.
Run the code locally and you receive a few status messages, finishing with "The model has been saved".
A few steps are needed to bring this code into AI Core. You can start by building the Docker image, during that process the above main.py code is copied onto the image.
The Python dependencies for the Docker image are in the requirements.txt
The Dockerfile:
Build the Docker image, ie with
And push it to the Docker repository that is already connected to AI Core.
Then you need the Argo WorkflowTemplate, Place this as hana-ml-car-price-training.yaml into the Git repository that is connected to your SAP AI Core instance (see the above prerequisites). Just remember to fill in the generic placeholders with your own details.
The above file doesn't have any surprises. However, note that it reads the SAP HANA Cloud logon credentials from an AI Core secret called hanacred.
Encode and store the logon credentials in these variables:
Place these encoded values into the JSON structure, which is expected by the main.py program that we want to deploy in AI Core. Execute this cell in the notebook and it will display the JSON, that cou can copy for use in AI Core.
Now we start working working within the user interface of SAP AI Core. Create an application in AI Core, pointing to the Git repository and the path, which holds the Argo file.
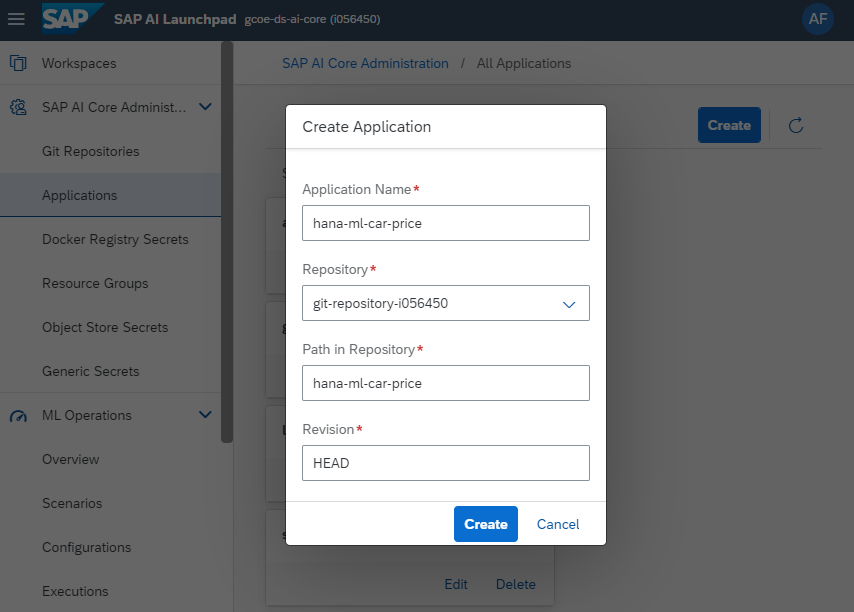
Then save the logon credentials as Generic Secret on the Resource Group that you are using. Paste the JSON that you created earlier.

You can see in SAP AI Core, that the scenario "HANA ML Car Price" has been created automatically, based on the configuration in the yaml file.

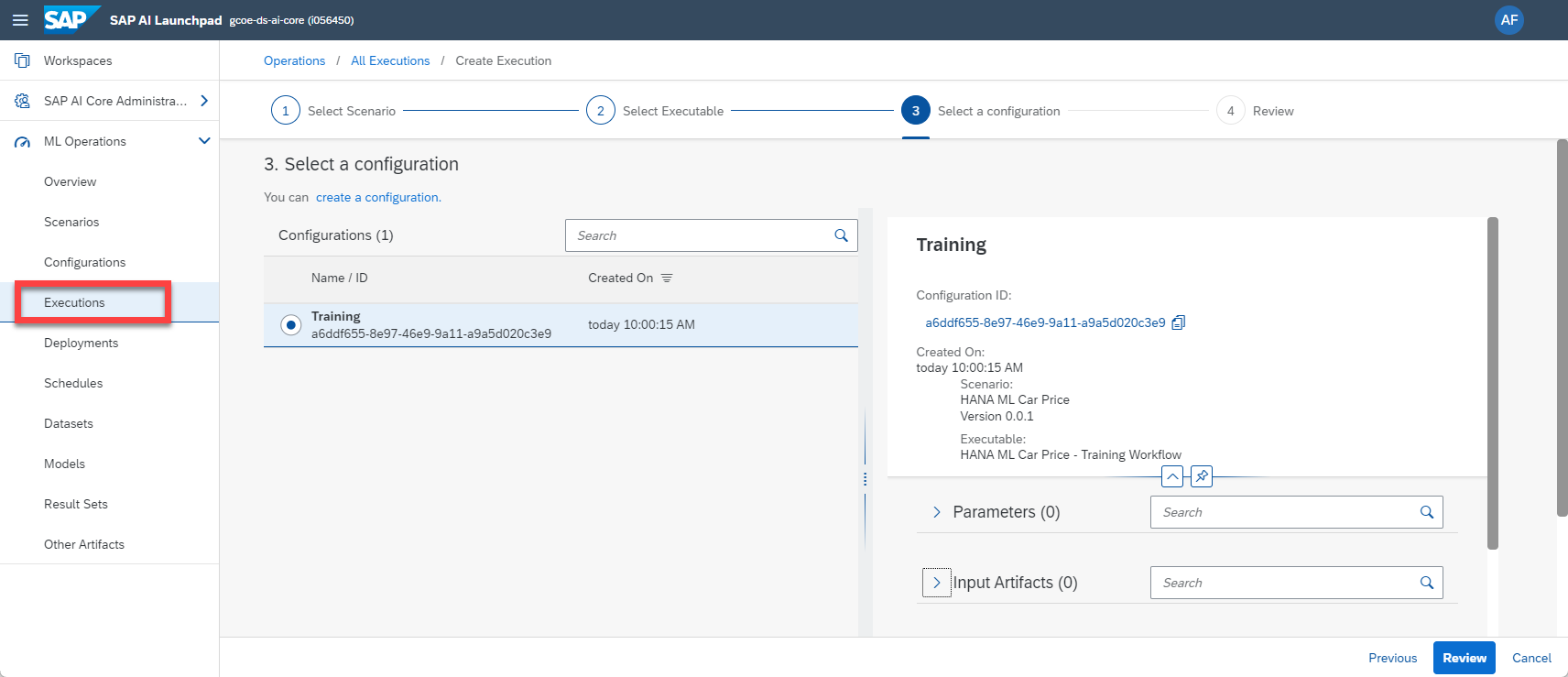
Now manually create a Configuration based on the above scenario. Just call it "Training", all other values are selected from the drop-downs.

Based on this new Configuration, you can create an Execution, which runs the Python code and thereby triggers the Machine Learning in SAP HANA Cloud.
Wait a few minutes and the job should complete. SAP HANA Cloud has trained the Machine Learning model and saved it to a table.
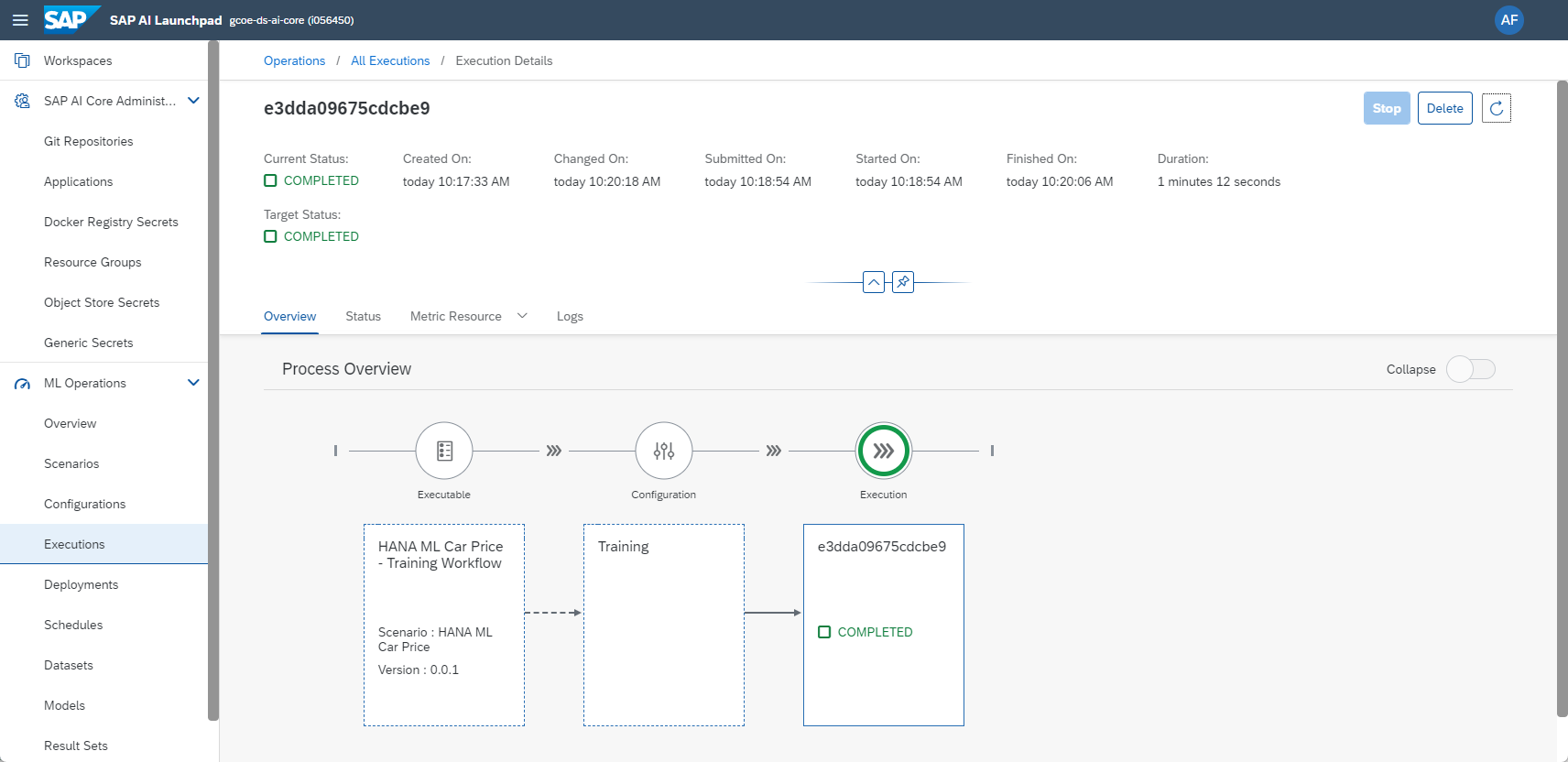
In case no connection to SAP HANA Cloud could be established, SAP AI Core's external IP address might have been blocked by SAP Datasphere for example. You need to add the IP address on SAP Datasphere's allowlist. The Python code prints the IP address the "Logs" tab. This address can change though, it might be best to lock a ticket with our Technical Support to get a list of the potential IP addresses you need to allow through.
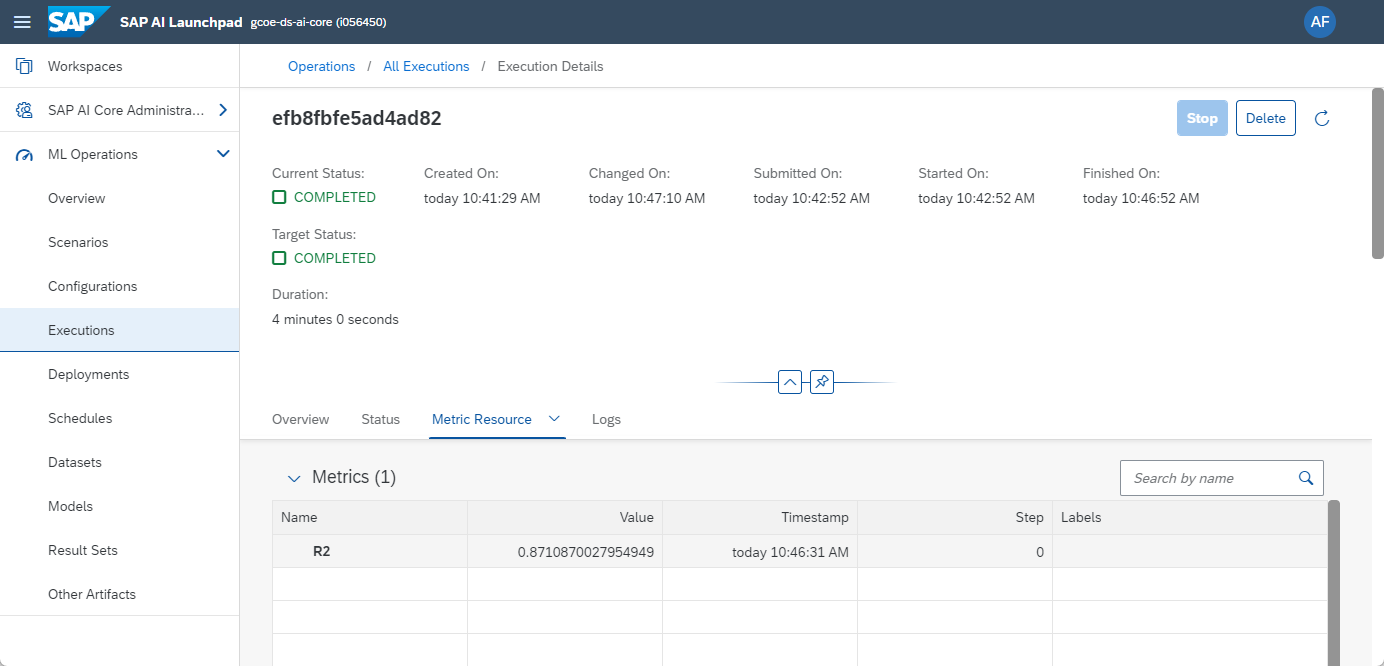
Once the code executes correctly, the "Metric Resource" tab shows the model's R2 indicator. More information, such as the print statements, are in the "Logs" tab.
If you want to run the regularly, ie to re-train the ML model on the latest data, you can define a Schedule.

And over time the Execution history will fill up.
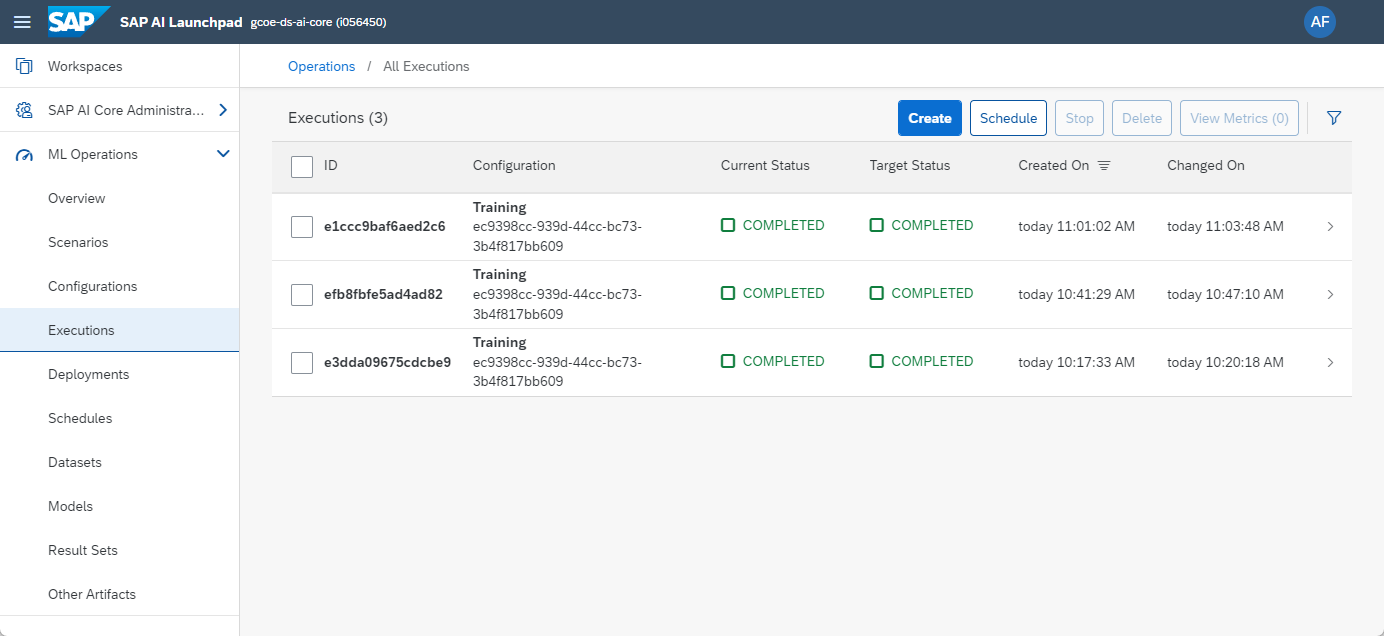
We now have a Machine Learning model in SAP HANA Cloud, that gets regularly updated. However, nothing is yet happening with the model. It is just sitting there. You could easily add further code either into this Configuration or a separate Configuration to create predictions on a scheduled interval.
Creating predictions in real-time on new data, that hasn't been saved yet to SAP HANA Cloud, is explained in the additional blog SAP AI Core – Realtime inference with SAP HANA Machine Learning.
Also, the concept of running Python code in SAP AI Core, as described in this blog, can also be used for many different purposes. You could for example store an APIKey from OpenAI as secret and schedule the Python code that interacts with GPT, or any other Large Language Model.
And finally, many thanks to paul.skiba and karim.mohraz for their help in getting me started with SAP AI Core!
This blog gives an introduction on using SAP AI Core to train a Machine Learning model in SAP HANA Cloud (or SAP Datasphere) to estimate the price of a used car through SAP's Python package hana_ml. The Python code gets executed in SAP AI Core, but the hana_ml package pushes the calculation logic to SAP HANA Cloud, leveraging the embedded Machine Learning (Predictive Analysis Library and Automated Predictive Library). Data and algorithms are already in SAP HANA Cloud, hence no data needs to be extracted or moved elsewhere, not even into SAP AI Core.
Just for completeness, the Python logic to trigger the Machine Learning in SAP HANA Cloud can be deployed in virtually any other Python environment, SAP AI Core is just one option. On the SAP Business Technology Platform for instance you also have CloudFoundry, Kyma or SAP Data Intelligence. Examples for deployment on non-SAP Systems are Databricks, Azure, Google or Dataiku. The choice is yours.

Table of contents:
- Prerequisites
- Data upload
- Local Python to train the Machine Learning model
- Python in AI Core to train the Machine Learning model
- Next steps
To follow this blog, all data and code is available in this repository.
Prerequisites
Prerequisites to follow this blog hands-on:
- You have access to either SAP Datasphere or SAP HANA Cloud, that has the Script Server enabled. This is not the case for the free trial systems.
- You have got some first experience in using the Machine Learning that is embedded in SAP HANA Cloud. There are a number of tutorials on the SAP Community to get started, for instance this blog by wei.han7 or these sample notebooks.
- You have access to SAP AI Core and have implemented a first scenario, for example this tutorial. This means for example, that you have already connected a Git repository and a Docker repository to your SAP AI Core instance.
Data upload
No Machine Learning without data. Start by loading the training data for our scenario. This blog is focussing on how the hana_ml logic can be deployed to SAP AI Core. Hence we skip the data exploration and preparation steps that would be extremely important in a real project.
Our data is based on the Ebay Used Car Sales Data. For simplification various columns from the dataset have been deleted from the file that we are using here. Also, vehicles that were in need of repair have been excluded. A detailed analysis of this dataset and various Machine Learning models on that data can be found in the (German speaking) Book Data Science mit SAP HANA. An older (English) example is in the blog SAP Data Intelligence: Deploy your first HANA ML pipeline.
The following Python code and the dataset can be downloaded from the repository.
Connect to SAP HANA Cloud:
import hana_ml.dataframe as dataframe
conn = dataframe.ConnectionContext(userkey='MYHC')
conn.connection.isconnected()Read the data into a Pandas DataFrame and upload the data as table into SAP HANA Cloud.
import pandas as pd
df_data = pd.read_csv('USEDCARS.csv', sep=',')
df_remote = dataframe.create_dataframe_from_pandas(connection_context=conn,
pandas_df=df_data,
table_name='USEDCARS',
force=True,
drop_exist_tab=False,
replace=False)Create a filtered view of the data and display a few rows. The data is filtered so that outliers that can distort the Machine Learning are excluded, ie the most expensive cars. This view will be used as source to train the Machine Learning model.
df_remote = df_remote.filter('PRICE >= 1000 AND PRICE <= 20000 and HP >= 50 AND HP <= 300 and YEAROFREGISTRATION >= 1995 AND YEAROFREGISTRATION <= 2015')
df_remote.save('V_USEDCARS', table_type='VIEW', force=True)
df_remote.head(5).collect()
Local Python to train the Machine Learning model
Typically in a project I would start the Machine Learning side in a Jupyter Notebook, to explore the data, to prepare the data and to experiment with Machine Learning. We are skipping these steps here and go straight to the final code that we want to deploy.
The following Python code can be downloaded from the repository (main.py).
Steps in that file:
- Connect to SAP HANA Cloud
- Point to the view that has the filtered data
- Train a Machine Learning model that estimates the price of the cars
- Save the trained Model in SAP HANA
The code can identify whether it is running inside AI Core (Kubernetes) or outside. If run inside AI Core, it retrieves the logon credentials for SAP HANA from AI Core's secret store (we will set this up later). If run outside AI Core, it uses the Secure User Store, that we have also used above to load the data to SAP HANA Cloud in the first place. Also, when run in AI Core it will also store a model metric with the execution in AI Core.
import os, datetime
import hana_ml.dataframe as dataframe
from hana_ml.algorithms.pal.unified_regression import UnifiedRegression
from hana_ml.algorithms.pal.model_selection import GridSearchCV
from hana_ml.model_storage import ModelStorage
from ai_core_sdk.tracking import Tracking
from ai_core_sdk.models import Metric
# Print external IP address
from requests import get
ip = get('https://api.ipify.org').text
print(f'My public IP address is: {ip}')
if os.getenv('KUBERNETES_SERVICE_HOST'):
# Code is executed in AI Core
print('Hello from Python in Kubernetes')
hana_address = os.getenv('HANA_ADDRESS')
print('The SAP HANA address is: ' + hana_address)
conn = dataframe.ConnectionContext(address=os.getenv('HANA_ADDRESS'),
port=int(os.getenv('HANA_PORT')),
user=os.getenv('HANA_USER'),
password=os.getenv('HANA_PASSWORD'))
else:
# File is executed locally
print('Hello from Python that is NOT in Kubernetes')
conn = dataframe.ConnectionContext(userkey='MYHC')
print('Connection to SAP HANA established: ' + str(conn.connection.isconnected()))
# Point to the training data in SAP HANA
df_remote = conn.table('V_USEDCARS')
# Train the Regression model
ur_hgbt = UnifiedRegression(func='HybridGradientBoostingTree')
gscv = GridSearchCV(estimator=ur_hgbt,
param_grid={'learning_rate': [0.001, 0.01, 0.1],
'n_estimators': [5, 10, 20, 50],
'split_threshold': [0.1, 0.5, 1]},
train_control=dict(fold_num=3,
resampling_method='cv',
random_state=1,
ref_metric=['rmse']),
scoring='rmse')
gscv.fit(data=df_remote,
key= 'CAR_ID',
label='PRICE',
partition_method='random',
partition_random_state=42,
output_partition_result=True,
build_report=False)
r2 = ur_hgbt.statistics_.filter("STAT_NAME = 'TEST_R2'").select('STAT_VALUE').collect().iloc[0, 0]
print('The model has been trained. R2: ' + str(r2))
# If executed on AI Core, store model metrics with the execution
aic_connection = Tracking()
aic_connection.log_metrics(
metrics = [
Metric(
name= "R2", value= float(r2), timestamp=datetime.datetime.now(datetime.timezone.utc)),
]
)
# Save the model
model_storage = ModelStorage(connection_context=conn)
ur_hgbt.name = 'Car price regression'
model_storage.save_model(model=ur_hgbt)
print('The model has been saved')Run the code locally and you receive a few status messages, finishing with "The model has been saved".
Python in AI Core to train the Machine Learning model
A few steps are needed to bring this code into AI Core. You can start by building the Docker image, during that process the above main.py code is copied onto the image.
Docker
The Python dependencies for the Docker image are in the requirements.txt
hana_ml==2.17.23071400
ai_core_sdk===1.22.3
shapely==1.8.0
jinja2==3.1.2
urllib3==1.26.16
requests==2.29.0
cryptography==39.0.1
IPython==8.14.0
The Dockerfile:
# Specify which base layers (default dependencies) to use
# You may find more base layers at https://hub.docker.com/
FROM python:3.9
#
# Creates directory within your Docker image
RUN mkdir -p /app/src/
#
# Copies file from your Local system TO path in Docker image
COPY main.py /app/src/
COPY requirements.txt /app/src/
#
# Installs dependencies within you Docker image
RUN pip3 install -r /app/src/requirements.txt
#
# Enable permission to execute anything inside the folder app
RUN chgrp -R 65534 /app && \
chmod -R 777 /appBuild the Docker image, ie with
docker build --no-cache -t YOURUSERHERE/hana-ml-car-price-training:01 .And push it to the Docker repository that is already connected to AI Core.
docker push YOURUSERHERE/hana-ml-car-price-restapi-inference:01Argo WorkflowTemplate
Then you need the Argo WorkflowTemplate, Place this as hana-ml-car-price-training.yaml into the Git repository that is connected to your SAP AI Core instance (see the above prerequisites). Just remember to fill in the generic placeholders with your own details.
apiVersion: argoproj.io/v1alpha1
kind: WorkflowTemplate
metadata:
name: hana-ml-car-price-training # Executable ID (max length 64 lowercase-hyphen-separated), please modify this to any value if you are not the only user of your SAP AI Core instance. Example: `first-pipeline-1234`
annotations:
scenarios.ai.sap.com/name: "HANA ML Car Price"
scenarios.ai.sap.com/description: "Estimate the price of a use car with SAP HANA Machine Learning"
executables.ai.sap.com/name: "HANA ML Car Price - Training Workflow"
executables.ai.sap.com/description: "Train the model in SAP HANA"
labels:
scenarios.ai.sap.com/id: "hana-ml-car-price" # The scenario ID to which the serving template belongs
ai.sap.com/version: "0.0.1"
spec:
imagePullSecrets:
- name: docker-registry-secret-XYZ # your docker registry secret
entrypoint: mypipeline
templates:
- name: mypipeline
container:
image: docker.io/YOURUSERHERE/hana-ml-car-price-training:01 # Your docker image name
command: ["/bin/sh", "-c"]
args:
- "python /app/src/main.py"
env:
- name: HANA_ADDRESS # Name of the environment variable that will be available in the image
valueFrom:
secretKeyRef:
name: hanacred # Name of the generic secret created in SAP AI Core for the Resource Group
key: address # Name of the key from the JSON string that is saved as generic secret
- name: HANA_PORT
valueFrom:
secretKeyRef:
name: hanacred
key: port
- name: HANA_USER
valueFrom:
secretKeyRef:
name: hanacred
key: user
- name: HANA_PASSWORD
valueFrom:
secretKeyRef:
name: hanacred
key: password The above file doesn't have any surprises. However, note that it reads the SAP HANA Cloud logon credentials from an AI Core secret called hanacred.
SAP HANA Cloud logon credentials
So lets create this secret in AI Core. The logon credentials need to be base64 encoded and placed into a JSON structure. You can use the following helper function that does the encoding:
import base64
def encode_base64(message):
message_bytes = message.encode('ascii')
base64_bytes = base64.b64encode(message_bytes)
base64_message = base64_bytes.decode('ascii')
return base64_messageEncode and store the logon credentials in these variables:
address_enc = encode_base64('YOURENDPOINT')
port_enc = encode_base64('443')
user_enc = encode_base64('YOURUSER')
password_enc = encode_base64('YOURPASSWORD')Place these encoded values into the JSON structure, which is expected by the main.py program that we want to deploy in AI Core. Execute this cell in the notebook and it will display the JSON, that cou can copy for use in AI Core.
print(json.dumps(
{"address":f'{address_enc}',
"port":f'{port_enc}',
"user":f'{user_enc}',
"password":f'{password_enc}'}
))Now we start working working within the user interface of SAP AI Core. Create an application in AI Core, pointing to the Git repository and the path, which holds the Argo file.
Then save the logon credentials as Generic Secret on the Resource Group that you are using. Paste the JSON that you created earlier.
Code execution with SAP AI Core
You can see in SAP AI Core, that the scenario "HANA ML Car Price" has been created automatically, based on the configuration in the yaml file.
Now manually create a Configuration based on the above scenario. Just call it "Training", all other values are selected from the drop-downs.
Based on this new Configuration, you can create an Execution, which runs the Python code and thereby triggers the Machine Learning in SAP HANA Cloud.
Wait a few minutes and the job should complete. SAP HANA Cloud has trained the Machine Learning model and saved it to a table.
In case no connection to SAP HANA Cloud could be established, SAP AI Core's external IP address might have been blocked by SAP Datasphere for example. You need to add the IP address on SAP Datasphere's allowlist. The Python code prints the IP address the "Logs" tab. This address can change though, it might be best to lock a ticket with our Technical Support to get a list of the potential IP addresses you need to allow through.
Once the code executes correctly, the "Metric Resource" tab shows the model's R2 indicator. More information, such as the print statements, are in the "Logs" tab.
If you want to run the regularly, ie to re-train the ML model on the latest data, you can define a Schedule.
And over time the Execution history will fill up.
Next steps
We now have a Machine Learning model in SAP HANA Cloud, that gets regularly updated. However, nothing is yet happening with the model. It is just sitting there. You could easily add further code either into this Configuration or a separate Configuration to create predictions on a scheduled interval.
df_remote_topredict = conn.table('USEDCARS')
df_remote_predicted = gscv.predict(df_remote_topredict, key='CAR_ID')
df_remote_predicted.save('USEDCARS_PREDICTED', force=True)Creating predictions in real-time on new data, that hasn't been saved yet to SAP HANA Cloud, is explained in the additional blog SAP AI Core – Realtime inference with SAP HANA Machine Learning.
Also, the concept of running Python code in SAP AI Core, as described in this blog, can also be used for many different purposes. You could for example store an APIKey from OpenAI as secret and schedule the Python code that interacts with GPT, or any other Large Language Model.
And finally, many thanks to paul.skiba and karim.mohraz for their help in getting me started with SAP AI Core!
- SAP Managed Tags:
- Machine Learning,
- SAP Datasphere,
- SAP HANA Cloud,
- Python,
- Artificial Intelligence,
- SAP AI Core,
- SAP AI Launchpad
Labels:
1 Comment
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,658 -
Business Trends
93 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
67 -
Expert
1 -
Expert Insights
177 -
Expert Insights
301 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
GraphQL
1 -
Kafka
1 -
Life at SAP
780 -
Life at SAP
13 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,577 -
Product Updates
346 -
Replication Flow
1 -
REST API
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,873 -
Technology Updates
429 -
Workload Fluctuations
1
Related Content
- New Machine Learning features in SAP HANA Cloud in Technology Blogs by SAP
- SAP HANA Cloud Vector Engine: Quick FAQ Reference in Technology Blogs by SAP
- 10+ ways to reshape your SAP landscape with SAP Business Technology Platform - Blog 5 in Technology Blogs by SAP
- 10+ ways to reshape your SAP landscape with SAP Business Technology Platform – Blog 4 in Technology Blogs by SAP
- Experiencing Embeddings with the First Baby Step in Technology Blogs by Members
Top kudoed authors
| User | Count |
|---|---|
| 34 | |
| 17 | |
| 15 | |
| 14 | |
| 11 | |
| 9 | |
| 8 | |
| 8 | |
| 8 | |
| 7 |