

- SAP Community
- Products and Technology
- Technology
- Technology Blogs by SAP
- What’s New in SAP HANA Cloud – June 2023
Technology Blogs by SAP
Learn how to extend and personalize SAP applications. Follow the SAP technology blog for insights into SAP BTP, ABAP, SAP Analytics Cloud, SAP HANA, and more.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Advisor
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
06-23-2023
6:42 PM
Approaching the end of Q2 2023, I am super exciting sharing insights into our latest release of SAP HANA Cloud, which was just made available publicly.
As usually, this blogpost will illustrate some of the new innovations introduced to SAP HANA Cloud and should help you getting an idea about the release scope.
In case that you are not preferring to follow my written words, you can replay our What’s new in SAP HANA Cloud in Q2 2023 webinar, which happened 29th June 2023. Moreover, our release teaser tries to give a crisp and concise overview, for those being willing to spend at least 5 minutes.
Blog Contents
General Innovations in SAP HANA Cloud
Innovations in SAP HANA Cloud, SAP HANA database
Machine Learning and Predictive Analysis
SAP HANA Deployment Infrastructure (HDI)
Graphical View ModelingInnovations in SAP HANA Cloud, data lake
Export to PARQUET file formatInnovations in SAP HANA Client
General Innovations in SAP HANA Cloud
Diving right into the latest innovations introduced to SAP HANA Cloud, I would like to start off with highlighting some general enhancements.
Customer-Defined Backup Retention
While previously database instances' backup retention period were fixed and backups were retained for 14 days in SAP HANA Cloud, we are happy to share that database administrators can now customize the backup retention period.
Doing so, one can select the backup retention period from 1 day to up to 7 months, for both – the SAP HANA database and the Data Lake Relational Engine.
The adjustment can be performed either via SAP HANA Cloud Central or via Command Line Interface, satisfying our customers’ needs for long-term data preservation while also offering an option to reduce spending for data backups.

configuration of backup retention time via SAP HANA Cloud Central
SAP HANA Cloud Tooling
The Q2 release of SAP HANA Cloud is also bringing numerous enhancements for our SAP HANA Cloud tools, including SAP HANA Cloud Central and SAP HANA Database Explorer.
SAP HANA Cloud Central
With the latest release, we have also added another powerful feature to our landscape tooling called SAP HANA Cloud Central.
SQL Console
Now, you can access a newly designed SQL Console, allowing you to discover your data and run database statements without the need to navigate to any additional tool. This increases productivity for a majority of use cases and scenarios significantly.

SQL Console in SAP HANA Cloud Central
SAP HANA Database Explorer
Scheduled Jobs
Scheduled Jobs, running within your SAP HANA Cloud instance, can now be visualized via the catalog browser of SAP HANA Database Explorer. Apart from browsing existing jobs, you can make use of the tool to enable, disable or delete existing jobs.
The new user interface helps you to view details about your jobs, like the execution frequency as well as the next scheduled start time, details on parameters and their values, as well as information on previously running scheduled jobs. Moreover, the tooling helps you to form SQL statements used to create scheduled jobs.

Scheduled Jobs in SAP HANA Database Explorer
New functionalities for SAP HANA Cloud, Data Lake Files
Our SAP HANA Cloud, Data Lake Files storage gives you the possibility to store file-based content in a very cost efficient manner.
With the Q2 release, our Database Explorer is offering new capabilities to rename or move selected files and folders stored within the file storage. Furthermore, SQL on Files was added to the Database Explorer, both for the Relational Engine as well as the File Storage itself.

new functionalities for Data Lake File Storage
Ability to view multiple spatial geometries
Additionally, the latest release of SAP HANA Cloud gives you the possibility to view multiple geospatial geometries within SAP HANA Database Explorer’s SQL Console viewer. Apart from viewing geometries on the map, map markers can be selected to see properties of each map marker, which eases working with geospatial data significantly and takes away the need for other geospatial viewers.
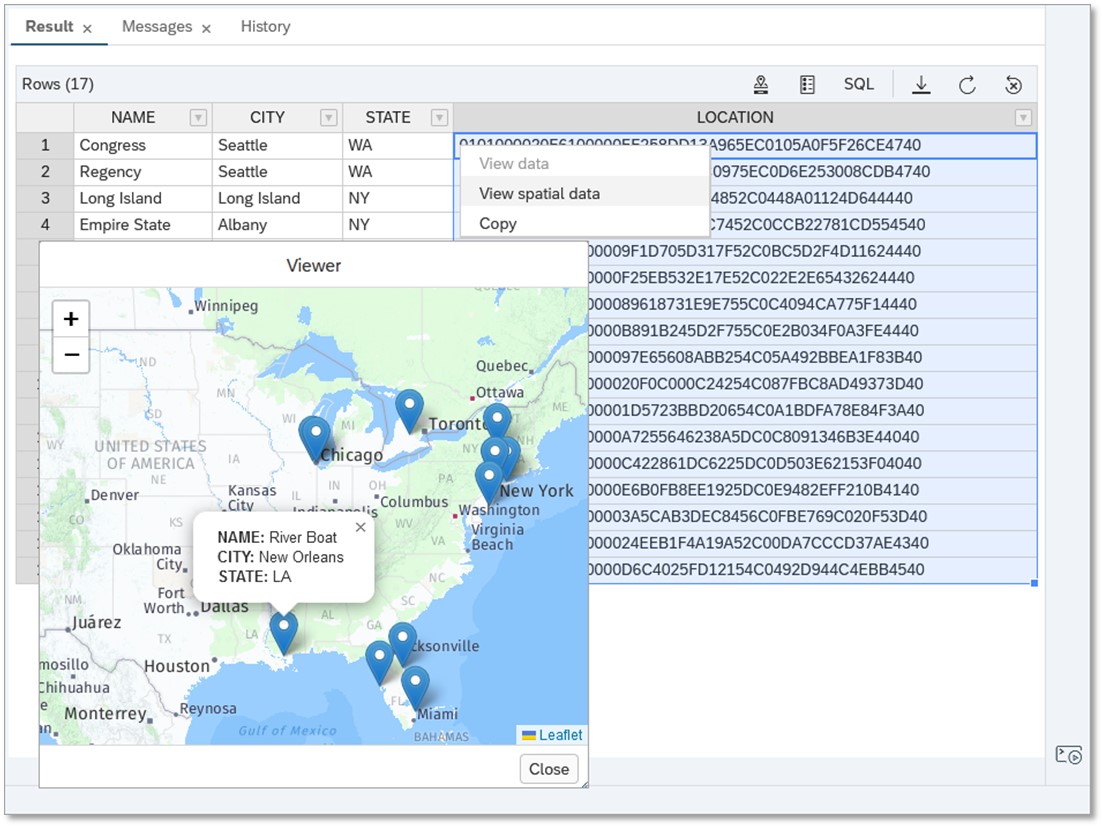
visualize geospatial data on a map in SAP HANA Database Explorer
Innovations in SAP HANA Cloud, SAP HANA database
After looking at some general enhancements, let’s dive into innovations specifically relevant for the SAP HANA database within SAP HANA Cloud.
Lifecycle Operations
Easing operations required when working with our database as a service solution is a core focus topic for us. Therefore, I am happy to share two new capabilities specifically impacting lifecycle operations:
Template-Based Instance Creation
The latest release introduces the possibility to create SAP HANA database instances via so-called templates. These templates can be user-defined and ease the provisioning of multiple systems at once. Moreover, they can help to “copy” systems based on self-formed stencils. The capability can, for instance, be particularly helpful when needing to create a quality assurance (QA) landscape from a single template.
The creation of a template as well as the creation of an instance based on the template can be performed via command line interface. Created templates are stored in customer provided Data Lake Files containers in order to make them available across cloud service providers and across regions. You can find more details about the functionality in our official SAP HANA Cloud documentation.
Fallback-Snapshots
In addition, the latest release also introduced the possibility to generate so-called fallback snapshots. These snapshots can be used for accelerate rollbacks after critical operations such as application or version upgrades.
Fallback snapshots need to be generated explicitly via command line interface and are retained for 14 days. As only one fallback snapshot is supported at a time, older snapshots need to be deleted before you can generate new ones.
In case you are looking for more details on the functionally, take a look at the blog post provided by our product expert srboljub.dave.

creation of fallback snapshot via CLI
Machine Learning and Predictive Analysis
SAP HANA Cloud's embedded machine learning and predictive analysis capabilities help to build intelligent data applications without the need for secondary systems and extensive pipelines.
In the area of forecasting and machine learning, the SAP HANA Cloud Q2 2023 release adds segmented forecasting execution for time series data outlier detection and forecast accuracy calculation (see all innovations).
Furthermore the Predictive Analysis Libraries’s (PAL) long-term time series forecasting (LTSF) function is now supporting multiple new neural network types, providing a much faster forecast performance with less network parameter tuning efforts for a simplified use and improved forecast results.
In addition to that, a new permutation-based feature-importance-calculation-method for PAL’s classification algorithms reveals a new feature influence calculation for an improved machine learning model interpretability.
The Python machine learning client 2.17 adds support for CAP-application artifact generation for SAP HANA Cloud machine learning scenarios driving Intelligent Data Applications. This enhancement is illustrated further in this following blog post.
Multi-Model Data Processing
SAP HANA Cloud’s Multi-Model Data Processing capabilities are a core value of the in-memory platform and offer you the flexibility to store, process and analyse a large variety of different data types, all within one single database system. Our Q2 release is therefore also bringing some fantastic new functionalities and enhancements to this area of the solution:
ST_MakeValid
The newly added functionality ST_MakeValid gives users the possibility to correct invalid geometries so that they can be used for geospatial analysis. This way, data scientists can make use of all existing geospatial data and leverage the value contained. Via the functionality both polygons and points can be made valid.
Syntax: <geom>.ST_MakeValid([<polygon_algorithm>][,<keep_degenerate>])
As making polygons valid is not a trivial operation, we are providing two options:

options available to make invalid polygons valid
ST_AsGeoJSON (multi-column) for feature sets
The enhanced ST_AsGeoJSON functionality is now providing the possibility to express larger features sets of geospatial data in GeoJSON format, including attribute values. Such attribute values are especially valuable when performing comprehensive geospatial analysis.
Syntax : ST_AsGeoJSON(<expression_list>[, <named_parameter_value>[,...] ])
The result returned by the aggregate function is a string representing a set of rows in geoJSON format.
Furthermore, the “include_bbox” attribute can be very helpful as it explains the extent of the geospatial data.
See below how to apply the function, and how the result maps to the input:

ST_AsEsriJSON (multi-column) for feature sets
Quite similar to the ST_AsGeoJSON function, the ST_AsEsriJSON function will also help you to retrieve a set of geospatial features, but in EsriJSON format.
The functionality can be applied in a similar way to retrieve aggregate values.
Syntax : ST_AsEsriJSON(<expression_list>[, <named_parameter_value>[,...] ])

ST_FréchetDistance
As part of your geospatial data analysis you may want to compare multiple trajectories or line strings, to understand their similarity.
The so-called Fréchet Distance can be a useful measure to do so.
The result can be particularly useful when comparing line strings and performing clusting based on their similarity, for instance.
Syntax: <geometry1>.ST_FrechetDistance(<geometry2>[, <unit_name>])

Frechet Distance - Walking Your Dog example
Community Detection - Using Louvain Algorithm
Via community detection, you can uncover hidden groups or clusters within complex networks. Via the algorithm, one can better identify nodes which are densely connected internally, but also loosely with other nodes.
Therefore, this functionality represents a valuable addition to our graph data processing capabilities.
 To better understand how the algorithm operates, we have illustrated the steps performed:
To better understand how the algorithm operates, we have illustrated the steps performed:
- Initialise the Graph
- Calculate the Modularity of each community (measure how well the nodes are connected)
- Finding the best split (finding the pair of community with the lowest modularity)
- Merging communities (communities with lowest modularity gain are merged)
- Repeat steps 3 & 4 until no more merges are required
SAP HANA Deployment Infrastructure (HDI)
Our SAP HANA Deployment infrastructure, or short HDI, allows developers to efficiently deploy database development artefacts to their SAP HANA database systems, via so-called containers. As with every release of SAP HANA Cloud, we have also introduce some very useful enhancement to this area of the product.
DML Update in hdbmigrationtable
With the Q2 update of SAP HANA Cloud, you are gaining the ability to use the DML Update functionality in “hdbmigrationtable” definitions. This enables you to perform proper adjustments of a table definition, fitting to your changing business requirements:
- Resize string length
- Adjust number types
- Enable explicit type casting
- Improve data model quality
- Support schema/table evolution
- Apply growing/changing requirements of table definitions
- Splitting 1 field into multiple fields
- Merging multiple fields into 1 field
ALTER Partition in hdbmigrationtable
Moreover, with the Q2 release, we are introducing the possibility to alter partitions when working with the hdbmigrationtable artefact.
This functionality helps to reduce the overall TCO of our system by allowing the definition and change of partitions on SAP HANA deployment infrastructure tables without complex rights assignment in SAP HANA deployment infrastructure. In addition, it allows partitioning already at the modeling level such as core data services for SAP Cloud Application Programming (CAP) model. And it supports the usage of partitioning on SaaS-type data models with no need for manual interaction at run time.
With the introduction of the feature, partitioning can now be added to a hdbmigrationtable as a migration step:

Database ID in service instances
Apart from the mentioned enhancement, the latest release is also providing adjustments easing the identification of the SAP HANA Cloud instance owning certain HDI containers.
To do so, we have added the database_id to the HDI container’s service key within the SAP BTP Cloud Foundry environment. With this attribute being added, handling a larger amount if HDI containers can be improved significantly.

database_id in service keys
Graphical View Modeling
Same as with the previous quarter’s release, the functionalities designed for graphical view modeling in SAP HANA Cloud once again received a great set of enhancements and new innovations. These include for instance new options for data preview, support for time ranges, additional capabilities for user-defined functions and many more.
To get an in-depth overview about the new capabilities, take a look at the blog post provided by our product expert jan.zwickel.
Innovations in SAP HANA Cloud, data lake
Our second database service component of SAP HANA Cloud, the so-called Data Lake, is also benefiting from great new enhancements introduced. So let’s take a closer look at some:
Transactional DDL Statements
The first innovation that I would like to introduce is the support for transactional DDL statement execution. Transactional DDL support gives you the ability to execute a group of DDL statements as a single transaction rather than as a series of separate transactions per statement. While the historic and default behaviour is still for all DDL statements to automatically commit each individual statement, we are offering our users the freedom to adjust the execution behaviour.

transactional DDL execution
With the introduction of the feature there are the following limitations present:
- Transactional DDL can only be executed on the Coordinator, not on Worker nodes
- Not all DDL statements are supported: DDL Statements Supported by Transactional DDL in Data Lake Relational Engine
Export to PARQUET file format
Prior to the QRC2 release of SAP HANA Cloud, the Data Lake Relational Engine supported only LOAD TABLE from Parquet files but did not support UNLOAD to Parquet file format. Now, we are introducing also the export to the Parquet, allowing you to benefit from the highly compressed file format.
New UNLOAD statement parameters that are specific to Parquet support include ROW GROUP SIZE and COMPRESSION.

export to Parquet file format
Innovations in SAP HANA Client
Also our innovations for the SAP HANA Clients are important to mention, as they directly introduce improvements towards usability and total cost of ownership (TCO) of SAP HANA Cloud.
Compression of network traffic between SAP HANA Cloud and SAP HANA Client
As of the QRC2 version release of SAP HANA Cloud, network data traffic between SAP HANA Cloud and SAP HANA Client interfaces is not compressed by default. This decreases the data volume being transmitted significantly and thereby reduces the cost for network traffic in many cases. While by default the compression is now activated, users can also adjust the behavior via connection property.
Node.js Connection Pool Support for User Switching
Furthermore, we have introduced new parameters, allowing for an efficient usage of connection pools when working with the Node.js clients. The ‘uid’ and ‘pwd’ parameters for getConnection help making use of established connection pools to improve application performance. Learn more about these enhancements via this tutorial.
Ability to stream large objects (LOBs) using the HANA Client GO driver
Last, I would like to call out the enhancements towards streaming of large objects (LOBs). With the Q2 release, we have now introduced the possibility to stream large objects using the HANA Client GO driver. The new API objects WriteLOB and ReadLOB can be used to reduce an application’s memory use and efficiently operate on larger objects. You can find out more at LOB Streaming in SAP HANA Client Interface Programming Reference
After reading about some of the highlight of our latest release, do you now want to get an even more detailed perspective of the Q2 2023 release of SAP HANA Cloud?
In that case, I can recommend taking a look at our What’s New Viewer in our Technical Documentation, which describes the entire scope of the release.
Also, to get some first-hand demonstrations on the latest innovations in SAP HANA Cloud, and to be able to raise any of your open questions, can replay our “What’s New in SAP HANA Cloud“ webinar, which happened on June 29, 2023. Together with my colleagues from the SAP HANA Cloud product management team, I will share more details about the release highlights.
Last but not least, it’s important to say: Don’t forget to follow the SAP HANA Cloud tag to not miss any updates on SAP HANA Cloud! In addition, you can find all our what’s new blogposts under the tag whatsnewinsaphanacloud. In the unfortunate case that you have missed the What’s New webinar in Q1 2023, you can find it and all future webinars in this playlist on YouTube.
Do you want to discuss some of the outlined innovations or have any other questions related to SAP HANA Cloud? Feel free to post them in our SAP HANA Cloud Community Q&A or in the comments below.
- SAP Managed Tags:
- SAP HANA Cloud, SAP HANA database,
- SAP HANA,
- SAP HANA Cloud, data lake,
- SAP HANA Cloud
Labels:
6 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
ABAP CDS Views - CDC (Change Data Capture)
2 -
AI
1 -
Analyze Workload Data
1 -
BTP
1 -
Business and IT Integration
2 -
Business application stu
1 -
Business Technology Platform
1 -
Business Trends
1,658 -
Business Trends
110 -
CAP
1 -
cf
1 -
Cloud Foundry
1 -
Confluent
1 -
Customer COE Basics and Fundamentals
1 -
Customer COE Latest and Greatest
3 -
Customer Data Browser app
1 -
Data Analysis Tool
1 -
data migration
1 -
data transfer
1 -
Datasphere
2 -
Event Information
1,400 -
Event Information
74 -
Expert
1 -
Expert Insights
177 -
Expert Insights
348 -
General
1 -
Google cloud
1 -
Google Next'24
1 -
GraphQL
1 -
Kafka
1 -
Life at SAP
780 -
Life at SAP
14 -
Migrate your Data App
1 -
MTA
1 -
Network Performance Analysis
1 -
NodeJS
1 -
PDF
1 -
POC
1 -
Product Updates
4,575 -
Product Updates
391 -
Replication Flow
1 -
REST API
1 -
RisewithSAP
1 -
SAP BTP
1 -
SAP BTP Cloud Foundry
1 -
SAP Cloud ALM
1 -
SAP Cloud Application Programming Model
1 -
SAP Datasphere
2 -
SAP S4HANA Cloud
1 -
SAP S4HANA Migration Cockpit
1 -
Technology Updates
6,871 -
Technology Updates
482 -
Workload Fluctuations
1
Related Content
- RingFencing & DeCoupling S/4HANA with Enterprise Blockchain and SAP BTP - Ultimate Cyber Security 🚀 in Technology Blogs by Members
- First steps to work with SAP Cloud ALM Deployment scenario for SAP ABAP systems (7.40 or higher) in Technology Blogs by SAP
- SAP Datasphere catalog - Harvesting from SAP Datasphere, SAP BW bridge in Technology Blogs by SAP
- Backdated postings in EWM in Technology Q&A
- Digital Twins of an Organization: why worth it and why now in Technology Blogs by SAP
Top kudoed authors
| User | Count |
|---|---|
| 15 | |
| 11 | |
| 10 | |
| 9 | |
| 8 | |
| 8 | |
| 7 | |
| 7 | |
| 7 | |
| 7 |