
- SAP Community
- Groups
- Interest Groups
- Artificial Intelligence and Machine Learning
- Blogs
- Using Machine Learning Foundations Bring Your Own ...
Artificial Intelligence and Machine Learning Blogs
Explore AI and ML blogs. Discover use cases, advancements, and the transformative potential of AI for businesses. Stay informed of trends and applications.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Showing results for
Associate
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report Inappropriate Content
02-22-2019
2:32 PM
This is the second part of a two parts tutorial. In this part we take the trained model that we created in the first part, upload it to Machine Learning Foundation and use it. We will create three Python files, one that carries a bunch of helper functions to interact with SAP Cloud Platform, a second one to upload our model and finally one inferring our model.
Prerequisites:
You have installed TensorFlow, best the GPU version. This requires that you also have installed one of the following Python versions: 3.4, 3.5 or 3.6. At the time this tutorial was written TensorFlow does not support Python 3.7. In addition, the following Python libraries are required:
- numpy
- scikit-image
- tensorflow-serving-api
- requests
- scikit-learn
You also need a global SAP Cloud Platform (SCP) account with a Space that contains an instance of service ml-foundation including a service key.
Traget Reader Group
This tutorial shall give developers some insides how to use Machine Learning Foundation and how to deploy and run an own model on SCP.
Getting a Service Key
To be able to send requests to SCP we need to be able to authenticate ourselves and to create bearer token. For this tutorial we want to keep things simple and store the service key of our ml-foundation service as ServiceKey.txt in our tutorial folder.
For those that never did that a small description:
Logon to your Global Account, navigate to your Subaccount, from there to the Space the ml-foundation instance has been created in, choose Service Instances, click on instance name and finally choose Service Keys:

Copy the service key and, as mentioned, save it as ServiceKey.txt. For a productive usage we would create an application and bind it ml-foundation.
Interacting with SAP Cloud Platform
We interaction with SAP Cloud Platform (SCP) fulfill four tasks:
- Upload a model to the model repository. The model repository contains of all versions of all our model. This includes also the models one may have created using the retrain services.
- Create a so-called model server running our model.
- Remove old model server running outdated versions of our model.
- Call the model server for interference.
For all these tasks Machine Learning Foundation provides rest APIs. The last task can also be fulfilled using gRPC. We will have a look at both methods. Please note that the code, to be short, has no elaborated error handling.
Let’s start with creating file scp_access.py. This file will take all the function to call the Machine Learning Foundation APIs that we need.
import os
import base64
import requests as req
from json import JSONDecoder as jd
import tensorflow as tf
import skimage.io
from tensorflow_serving.apis import predict_pb2
from tensorflow_serving.apis import prediction_service_pb2_grpc
from grpc.beta import implementations
def load_json_from_file(path):
with open(path, mode='rt') as json:
data = json.read()
return jd(strict=False).decode(data)
def generate_bearer(auth_url, client_id, client_secret):
url = "/".join([auth_url, 'oauth', 'token'])
querystring = {"grant_type": "client_credentials"}
credetials = '{}:{}'.format(client_id, client_secret)
base64string = base64.b64encode(str.encode(credetials)).decode("ascii")
headers = { 'Content-type': 'application/x-www-form-urlencoded',
'Authorization' : "Basic %s" % base64string}
response = req.get(url, params=querystring, headers=headers)
token = jd(strict=False).decode(response.text)
return 'Bearer ' + token['access_token']
The first two function we have created are required to create the bearer token, which we need to authenticate us at the called services. The first function, load_json_from_file, will help us to load the service key. The second one, generate_bearer, takes the SAPUAA URL and the client credentials from the service key and requests a bearer.
Having done that, we can create the functions to perform rest call to store our model in the model repository:
def upload_model(model_name, token, service_urls, model_path):
url = service_urls['MODEL_REPO_URL'] + '/api/v2/models/{}/versions'.format(model_name)
headers = {'Authorization' : token,
'Accept' : 'application/json'}
body = {'file' : (os.path.split(model_path)[1], _load_model_from_file(model_path))}
response = req.post(url, files=body, headers=headers)
return (response.status_code, jd(strict=False).decode(response.content.decode()))
def _load_model_from_file(path):
with open(path, mode='rb') as model:
return model.read()
Function upload_model has four parameters:
- model_name is the name, and with that the id, our model shall have within the model repository.
- token takes the bearer token.
- service_urls is a dictionary containing the endpoints of all machine learning foundation service, which we can get from the service key.
- model_path contains of the path to the model .zip file.
In case we were successful the response contains beside the model name the model version, which we need in the next step, the creation of our model server:
def create_model_server(model_name, model_version, token, service_urls):
url = service_urls['DEPLOYMENT_API_URL'] + '/api/v2/modelServers'
headers = { 'Content-Type' : 'application/json',
'Accept' : 'application/json',
'Authorization' : token}
data = {'specs' : {'enableHttpEndpoint' : True,
'modelRuntimeId': 'tf-1.8',
'models' : [{'modelName' : model_name, 'modelVersion' : model_version}]
},
'replicas': 1,
'resourcePlanId': "starter"
}
response = req.post(url, json=data, headers=headers)
return (response.status_code, jd(strict=False).decode(response.content.decode()))
When a model servicer is created, a container instance is started. The features of this container are described by a JSON body. Some of the Attributes shall be explained here:
- enableHttpEndpoint: By default, a model server provides only the gRPC API. In case we want to have the rest API as well, what we want, we need to set this parameter to true.
- modelRuntimeId: It is possible to choose between different TensorFlow version. We choose the latest supported version at the time of writing this tutorial. You can find a list of all option in the SAP Help.
- models: The model, which shall be taken from the model repository.
- resourcePlanId: Sets the resource plan, which describes the number of CPUs and, if required, the number of GPUs that shall be booked and the amount of memory to be allocated. For testing our model, the smallest and cheapest resource plan will make it.
- replicas: Number of instances of the model server that shall be created. For us one instance is sufficient.
For more details you may want to have a look at the service in SAPs API Hub.
As mentioned, creating a model server is not all we want to do. We also want to retrieve information about our model server and, if they are no longer needed, delete them:
def get_model_server_by_id(model_server_id, token, service_urls):
url = service_urls['DEPLOYMENT_API_URL'] + '/api/v2/modelServers/{}'.format(model_server_id)
return _execute_get(token, url)
def get_model_server_by_name(model_name, token, service_urls):
url = service_urls['DEPLOYMENT_API_URL'] + '/api/v2/modelServers?modelName={}'.format(model_name)
return _execute_get(token, url)
def remove_model_server(model_server_id, token, service_urls):
url = service_urls['DEPLOYMENT_API_URL'] + '/api/v2/modelServers/{}'.format(model_server_id)
headers = {'Authorization' : token,
'Accept' : 'application/json'}
response = req.delete(url, headers=headers)
return (response.status_code, response.content.decode())
def _execute_get(token, url):
headers = {
'Accept': 'application/json',
'Authorization': token,
'Cache-Control': "no-cache"
}
response = req.get(url, headers=headers)
return response.status_code, jd(strict=False).decode(response.text)
Having done that, we are ready to use the model server. The following part has the code to call the http endpoint:
DATA_TYPES = {"float" : 1, "int64" : 9, "int32" : 3, "string" : 7}
VALUE_TYPES = {1 :"float_val", 3 : "int32_val", 7 : "string_val", 9 : "int64_val"}
def _to_float(data):
return data.astype(float)/255
def infer_model_http(endpoint, token, model_name, model_version, image_path, signature_name = 'predict_images'):
# Read an image as a two-dimensional array of integer
dtype = DATA_TYPES['float']
data = _to_float(skimage.io.imread(image_path))
url = 'http://' + endpoint['host'] + '/api/v2/predict'
headers = { 'Content-Type' : 'application/json',
'Accept': 'application/json',
'Authorization' : token}
body = {'model_spec' : {
'name': model_name,
'version': model_version,
'signature_name': signature_name
},
'inputs': {
'images': {
'dtype': dtype,
'tensor_shape': {
'dim': [
{'size': '1'},
{'size': '32'},
{'size': '32'},
{'size': '3'}]},
'{}'.format(VALUE_TYPES[dtype]): data.flatten().tolist()
}
}
}
response = req.post(url, json = body, headers = headers)
if response.status_code >= 300:
return (response.status_code, response.content.decode())
else:
return (response.status_code, jd(strict = False).decode(response.content.decode())['outputs']['scores']['float_val'])
First, we have two dictionaries to handle the data type of the data we provide. DATA_TYPES is just for convenience. The API expects the data type as an integer, but we want to give by name. VALUE_TYPES helps us to dynamically give the right attribute name in the payload.
Second, we have _to_float, a small helper function that converts the image data from integer values to floats. We do this, as we must provide the image in the format that the input tensor of our signature has. You may remember that we used the following code to transform the loaded data images in the first part:
self.images = images.reshape(n,3,32,32).transpose(0,2,3,1).astype(float)/255 The rest of the transformation is not needed, as our examples anyhow have a shape of [32,32,3].
Third, we have the function that calls the rest service. We want to have a look at some of the function parameter:
- endpoint: https endpoint of the model server we have created with create_model_server.
- signature_name: Name of the signature that we like to address. This name was defined when we called add_meta_graph_and_variables during our training.
- image_path: The path to the image on our machine.
Even so the code seems to be straight forward, it’s the creation of a rest call with a JSON body, we should have a look at the following line:
'{}'.format(VALUE_TYPES[dtype]): data.flatten().tolist()The API expects, depending on the type of our data, a different parameter e.g. float_val in case of float. To be more generic we use our dictionaries to look the correct parameter name up.
The last function does the same but using gRPC:
def infer_model_grcp(endpoint, token, model_name, image_path, signature_name = 'predict_images'):
#Read an image as a two dimensional array of integer
data = skimage.io.imread(image_path)
#Create a channel for an RPC with tensorflow
credentials = implementations.ssl_channel_credentials(root_certificates=endpoint["caCrt"].encode())
channel = implementations.secure_channel(str(endpoint['host']),
int(endpoint['port']), credentials)
stub = prediction_service_pb2_grpc.PredictionServiceStub(channel._channel)
req = predict_pb2.PredictRequest()
req.model_spec.name = model_name
req.model_spec.signature_name = signature_name
req.inputs["images"].CopyFrom(tf.contrib.util.make_tensor_proto(_to_float(data), shape=[1,32,32,3], dtype="float32"))
res = stub.Predict(req, 150, metadata=_metadata_transformer(token))
intermediates = (str(res).split('}')[3].split('\n'))[1:][:-1]
values = [float(value.split(':')[1]) for value in intermediates]
return values
def _metadata_transformer(bearer_token):
additions = []
token = bearer_token
additions.append(('authorization', token))
return tuple(additions)
Creating a Model Server
Now that we have everything we need to first store our model in the model repository and then deploy it and create model server. The code shall be placed in a file we call deployment.py. The first step we need to make is to create a Bearer Token. As already mentioned in the beginning, we keep things simple and read the service key from the file system. With the information from it we can create one.
import scp_access as scp
import time
import requests as req
from pprint import pprint as pp
MODEL_PATH = 'cifar10.zip'
SERVICE_KEY_PATH = 'ServiceKey.txt'
MODEL_NAME = 'cifar10-tutorial'
# Load the Service Key
service_key = scp.load_json_from_file(SERVICE_KEY_PATH)
print("Service Key read")
bearerToken = scp.generate_bearer(service_key['url'], service_key['clientid'], service_key['clientsecret'])
print('Token created')
Please be aware that you must adjust MODEL_PATH and KEY_PATH in case you did not store the model and/or the service key in the same folder as deployment.py.
Next, we store the model in the repository:
#Load the trained model to the repository
try:
print('Start model upload')
status, resp = scp.upload_model(MODEL_NAME, bearerToken, service_key['serviceurls'], MODEL_PATH)
except req.RequestException as e:
print(e.read().decode())
Now we perform two steps. We look for existing model server instances using our model and start the creation of a new instance.
else:
print('Model uploaded ({}). Search for old versions'.format(status))
status, model_severs = scp.get_model_server_by_name(MODEL_NAME, bearerToken, service_key['serviceurls'])
try:
# Find existing model server for older versions of the model
status, resp = scp.create_model_server(resp['modelName'], resp['version'], bearerToken, service_key['serviceurls'])
except req.RequestException as e:
print(e.read().decode())
In fact, the last rest call did not create the model server but creates a job that creates the model server for us. So, we need to check the state of the creation:
else:
print('Started server creation. Create no. instances {} with plan "{}"'.format(resp['specs']['replicas'], resp['specs']['resourcePlanId']))
deployment_state = resp['status']['state']
model_server_id = resp['id']
# The deployment is a asynchronous process. We need to wait still it ends
while deployment_state == 'PENDING':
print("Current deployment status: {}".format(deployment_state))
time.sleep(10) # Ping for the status every 10 seconds
status, resp = scp.get_model_server_by_id(model_server_id, bearerToken, service_key['serviceurls'])
deployment_state = resp['status']['state']
If everything went well we can, as a last step, delete the old model server instances:
if deployment_state == 'SUCCEEDED':
print('Model successfully deployed. Model Server Id: {}'.format(model_server_id))
if len(model_severs['modelServers']) > 0:
#After the model has successfully deployed, delete old model server
print('Remove old versions')
for model_servers in model_severs['modelServers']:
try:
status, _ = scp.remove_model_server(model_server['id'], bearerToken, service_key['serviceurls'])
if status < 300:
print('Successfully removed version {}'.format(model_server['specs']['models'][0]['modelVersion']))
except req.RequestException as e:
print(e.read().decode())
else:
print ('Final status: {}'.format(status))
print(resp)
Our script is finished, we can let it run. The result shall look like this:
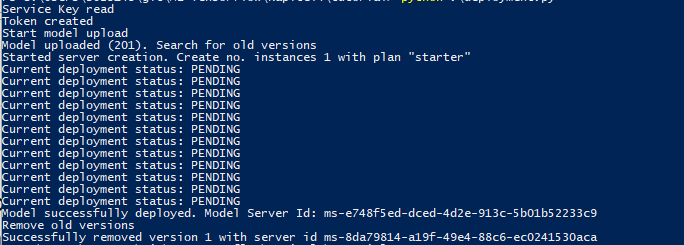
Using the Model Server
If you reached this point of the tutorial your model server is up and running. So, let’s create another script that we can use to infer pictures. You can name it again as you want e.g. inference.py.
As in the last script we begin with creating a Bearer token:
import scp_access as scp
import numpy as np
CIFAR_CATEGORY = ['Airplane', 'Automobile', 'Bird', 'Cat', 'Deer', 'Dog', 'Frog', 'Horse', 'Ship', 'Truck']
SERVICE_KEY_PATH = 'ServiceKey.txt'
AIRPLANE_PATH = 'cifar-airplane5.png'
SHIP_PATH = 'cifar-ship9.png'
MODEL_NAME = 'cifar10-tutorial'
service_key = scp.load_json_from_file(SERVICE_KEY_PATH)
print("Service Key read")
bearer_token = scp.generate_bearer(service_key['url'], service_key['clientid'], service_key['clientsecret'])
print('Token created')
The last code snipped has three steps:
status, resp = scp.get_model_server_by_name(MODEL_NAME, bearer_token, service_key['serviceurls'])
print('Model server instance found. Run test')
resp = resp['modelServers'][0]
result = scp.infer_model_grcp(resp['endpoints'][0], bearer_token, resp['specs']['models'][0]['modelName'], AIRPLANE_PATH)
print("Result of test: {}".format(result))
category = np.argmax(result)
print("Selected Category: {}({})".format(category, CIFAR_CATEGORY[category]))
status, result = scp.infer_model_http(resp['endpoints'][1], bearer_token, MODEL_NAME, resp['specs']['models'][0]['modelVersion'], SHIP_PATH)
print("Result of test: {}".format(result))
category = np.argmax(result)
print("Selected Category: {}({})".format(category, CIFAR_CATEGORY[category]))
First, we retrieve information about our model server. Mainly the endpoint of your model server instance. Second, we call the server using gRPC and finally we call the server using rest.
The two examples mentioned in the code are given below. You can store them anywhere, but if you store same in the same folder and use cifar-airplane5.png, cifar-ship9.png, you do not have to change the value for the corresponding parameter.


Running inference.py should give you a result like the following:

We have finished the second part of the tutorial. I hope you had some fun and got some new insides.
- SAP Managed Tags:
- Machine Learning
3 Comments
You must be a registered user to add a comment. If you've already registered, sign in. Otherwise, register and sign in.
Labels in this area
-
Agents
4 -
AI
5 -
AI Launchpad
2 -
Artificial Intelligence
2 -
Artificial Intelligence (AI)
3 -
Brainstorming
1 -
BTP
1 -
Business AI
2 -
Business Trends
1 -
Business Trends
1 -
Cloud Foundry
1 -
Data and Analytics (DA)
1 -
Design and Engineering
1 -
forecasting
1 -
GenAI
1 -
Generative AI
5 -
Generative AI Hub
4 -
Graph
1 -
Language Models
1 -
LlamaIndex
1 -
LLM
2 -
LLMs
2 -
Machine Learning
1 -
Machine learning using SAP HANA
1 -
Mistral AI
1 -
NLP (Natural Language Processing)
1 -
open source
1 -
OpenAI
1 -
Python
2 -
RAG
2 -
Retrieval Augmented Generation
1 -
SAP Build Process Automation
1 -
SAP HANA
1 -
SAP HANA Cloud
1 -
Technology Updates
1 -
User Experience
1 -
user interface
1 -
Vector Database
3 -
Vector DB
1 -
Vector Similarity
1